なるべく簡単に画像生成AIの追加学習をしよう🚀

こんにちは。だだっこぱんだです。
追加学習って聞くとなんか難しそうに感じますよね。
実際むずいです。
今回はそんな追加学習をなるべく簡単にできるように超ざっくり解説していきます。
WebUIを作ってみた
追加学習のWebUIを作ってみました。
そのまま起動もできますし、AUTOMATIC1111/StableDiffusionWebUIの拡張機能としても使えます。
このWebUIでは @kohya さんの sd-scripts を使用させていただいてます。
まずはインストールしてみましょう
インストール方法は
WebUIの拡張機能として
Colabで (推奨)
ローカルにインストール (推奨)
の三種類です。
拡張機能としてインストール
これは超簡単です。
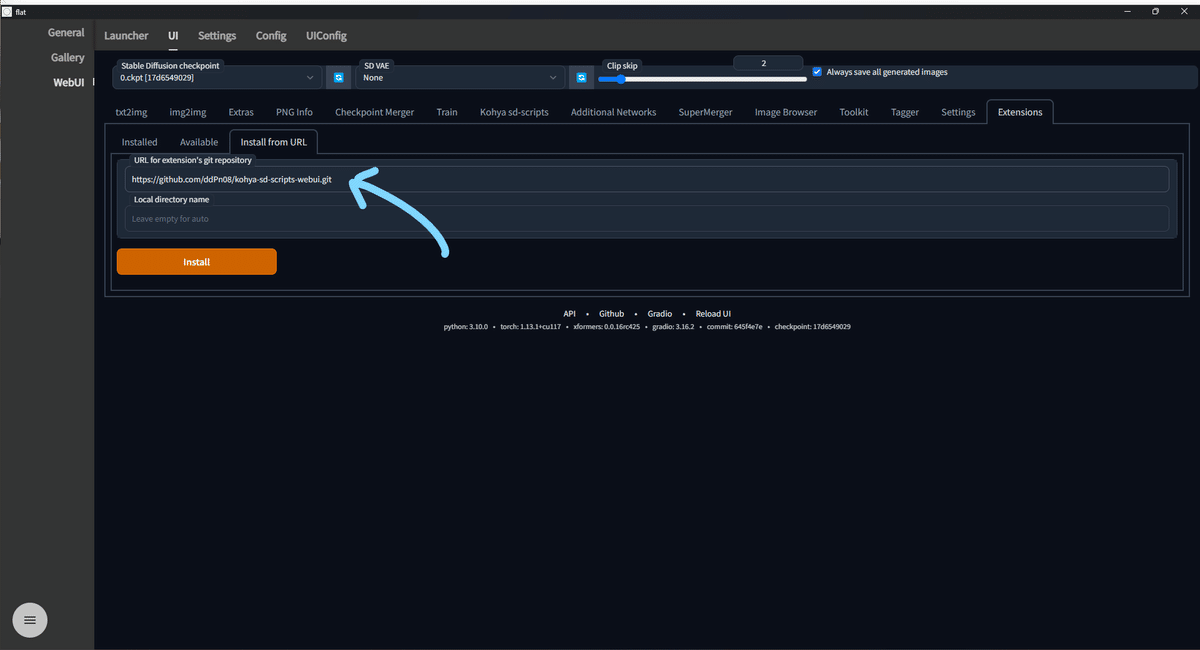
Extensions > Install from URL から以下のURLを入力してインストールボタンを押します。
https://github.com/ddPn08/kohya-sd-scripts-webui.gitしかし、この方法にはいくつか問題があります。
まず、メモリ不足に陥りやすいです。
学習時にWebUIのモデル等が残ってしまうのでメモリが圧迫された状態で学習することになります。
これを回避するためには0.ckpt等の空のモデルファイルを読み込んでから学習させるのが良いです。
https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/908#issuecomment-1256198421
Colabでトレーニング
上のリンクからノートブックを開きます。

開いたら ランタイム > 全てのセルを実行 をクリックします。
開き方はStableDiffusionWebUIと同じ感じです。URLが表示されたら、"http://127.0.0.1:7860"ではない方のURLをクリックし、ページを開きます。
ローカルで起動
Gitをインストール
これに従ってGitをインストールします。
コマンドプロンプトを起動 (Windows)
(MacOS持ってないのでWinodwsだけの解説になります)
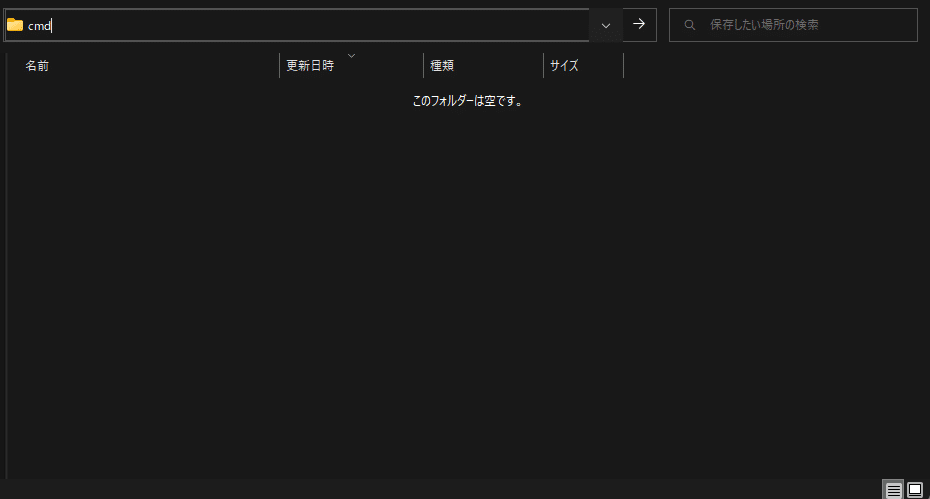
ツールのフォルダを保存したい場所をエクスプローラーで開きます。
エクスプローラのパスが表示されている部分に"cmd"と入力します。
起動したコマンドプロンプトで以下のコマンドを実行します
git clone https://github.com/ddPn08/kohya-sd-scripts-webui.git
cd kohya-sd-scripts-webui
./webui.bat --xformersそうするとインストールと起動が始まります。(少し時間がかかります)
インストールが終わったら表示されたURLをクリックします。
開いたら

いろいろ表示されます。
この先はどういう学習方法で学習するかによって操作が変わってきます。
今回は学習手法の一つであるLoRA を使っていきます。
細かい説明等はKohyaさんのリポジトリを参照してください。
画風を学習
データセットはご自分で集めてくださいフォルダに画像ファイルが入っていればOKです。
画風の場合20~100くらいがいいかな?僕も経験浅いので正解かどうかはわからないです。
タグ付け
すでにタグが付いてる(画像ファイルと同じ名前のテキストファイルがフォルダに存在する)のであればスキップして大丈夫です。

preparetion > Tag images by wd1.4tagger を開きます。
"train_data_dir" に画像が入ったフォルダのパスを選択。
そしたらRunボタンをクリックします。
Runボタンの上のボックスに"Finished."と表示されたら成功です。
Metaファイルを作成
学習に使う情報を保存するmetaファイルを生成します。
場所はどこでも大丈夫です。
※すでに存在する場所を指定すると情報が追記されて予期しない動作をする場合があるので注意してください。

preparetion > Merge tags を開きます。
"train_data_dir" に画像が入ったフォルダのパスを選択。
"out_json" にメタデータの出力先を入力。(例: C:\Users\ddPn08\Users\datasets\meta.json)
Runボタンの上のボックスに"Finished."と表示されたら成功です。
latentsの事前取得
最後の準備作業です。
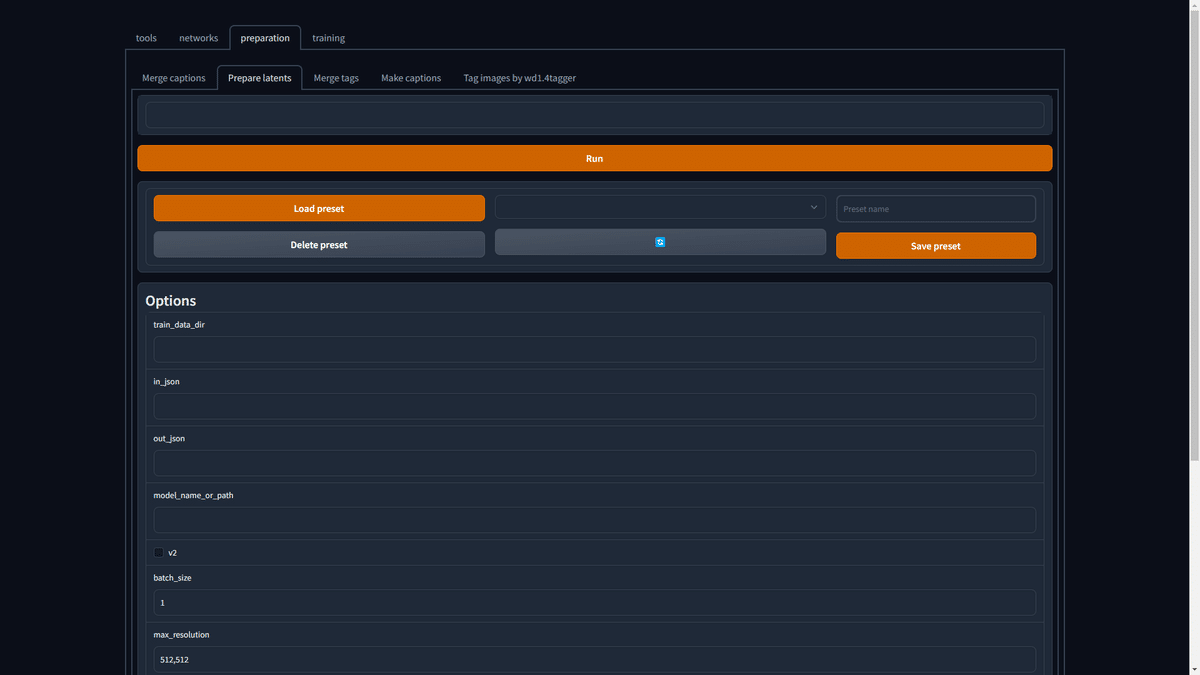
preparetion > Prepare latents を開きます。
"train_data_dir" に画像が入ったフォルダのパスを選択。
"in_json" に先ほど生成したメタデータの出力先を入力。(例: C:\Users\ddPn08\Users\datasets\meta.json)
"out_json" に新しいメタデータの出力先を入力。(例: C:\Users\ddPn08\Users\datasets\meta-lat.json)
"model_name_or_path" に学習に使うモデルファイル、もしくはdiffusersのidを入力。
Runボタンの上のボックスに"Finished."と表示されたら成功です。
学習

preparetion > Train network を開きます。
まずLoad Presetボタンの右側のドロップダウンを開き"lora-x512"を選択します。そうしたらLoad Presetボタンをクリックし、プリセットを読み込みます。
"train_data_dir" に画像が入ったフォルダのパスを選択。
"in_json" に先ほど生成したメタデータの出力先を入力。(例: C:\Users\ddPn08\Users\datasets\meta-lat.json)
"model_name_or_path" に学習に使うモデルファイル、もしくはdiffusersのidを入力。
"output_dir" に、学習したモデルファイルを出力するフォルダを入力。
"save_every_n_epochs" には何エポックごとに学習データを保存するかを入力。(例: 学習画像が100枚なら5を指定すると500枚学習した段階でモデルが一つ保存されます。)
Runボタンの上のボックスに"Finished successfully."と表示されたら成功です。
概念の学習
いつか書きます()