
Amazon SageMaker CanvasとDataRobotを比較してみた

概要
こんにちは。電通デジタルでデータサイエンティストをしている中嶋です。
昨年11月にAWSからSageMakerのアナリスト向けGUIソリューションとしてSageMaker Canvasが発表されました。この記事ではこのソリューションをハンズオン形式で動かしてみて、使用感やアウトプットを見ていこうと思います。また同じGUIの機械学習自動化ソリューションとしても有名なDataRobot AI Cloud(以下、DataRobot)とも比較してレビューします。想定読者としてはこれから実務に機械学習を取り入れていきたいと考えているビジネスユーザーや駆け出しデータサイエンティスト向けとなっています。そのため細かい機能などについては割愛しています。
サマリー
最初に忙しい方向けに各サービスの特徴と結果をまとめておきます。
SageMaker Canvasの特徴
AWSが提供するクラウド上で実行可能な機械学習サービスSageMakerの派生ソリューション。このCanvasはコーディングに不慣れなユーザー向けにGUIでモデル作成が可能なサービスとなっている。
モードは standard buildとquick buildから選べる
Kaggleのタイタニックデータでの検証ではstandard buildは1時間以上かかるが精度の高いモデルを作ることができる。また、モデル学習後はSageMakerにGUIで簡単にデプロイ(構築したモデルを実運用に乗せること) でき、APIでバッチ/リアルタイム推論を呼び出すことができる
quick buildは簡易なモデル作成機能のみ。数分で学習結果が出力される
UIの使い心地としては、モデリング時の細かい設定まではできないが操作性はシンプルで使いやすい
モデルアウトプットはquick buildでは必要最低限の特徴量インパクト、説明変数の値ごとのインパクト値、精度指標となっており、モデルの詳細は確認することはできない。standard buildではこれらに加えモデルのアルゴリズムやハイパーパラメーターなどを確認することができる
Kaggleのタイタニックデータを用いた精度検証では、quick buildではtestデータの正解率が73.2%、standard buildでは78.0%となった
エンドポイント設定を行うことでモデルによる予測スコアを他サービスに連携することができる。
料金体系はオンデマンド方式で使用した分だけの請求となる
DataRobotの特徴
DataRobot社が提供する機械学習モデリングに特化した自動分析ツール。直感的なGUIを維持しつつ、上級者向けの細かい設定も可能。更にMLOpsまでカバーしている。
モードはオートパイロット、クイック、手動、包括的の4種類から選べる
Kaggleのタイタニックデータの場合、オートパイロットモード(2ワーカー)で学習に53分程度かかり、クイックモードよりも多くのモデルをテストし精度の高いモデルを構築可能
同じタイタニックデータの場合、クイックモード(2ワーカー)で学習に33分ほどかかる。クイックといえどもオートパイロットと同様に詳細なモデル結果を参照できる
所要時間に関してはライセンスに応じてワーカー数を増やすことでより短時間にすることも可能
UIの使い心地としては、モデリング時の細かい設定まで必要に応じて行うことができる一方で、UIの分かりやすさも損なわずクイックな検証にも使いやすい
モデルアウトプットは各モード共通で評価、解釈、説明、予測等の様々な観点から色々な指標を見ることができる。どのようなモデルが作られたのかがよく理解できるよう工夫されており、SageMaker Canvasと比較して多くの可視化機能を備えている。 具体的にはROCカーブや特徴量インパクトはもちろん、使用したモデルアルゴリズムの種類やブループリントと呼ばれるデータ処理パイプライン等も確認することができる。
Kaggleのタイタニックデータを用いた精度検証では、クイックモードではtestデータの正解率が80.1%、オートパイロットモードでは76.6%となった
MLOpsの思想を念頭に置いたソリューション設計になっており、デプロイも簡単にでき、モデル予測の監視機能も備えている。
料金体系は年間でのライセンス契約となっている
ここからは各サービスをハンズオン的に使いながら、上記の観点で比較した内容を見ていきたいと思います。
各サービスの使い方
サービスごとにデータの準備、モデル作成と結果の確認、予測までの手順を見ていきたいと思います。
Sagemaker Canvas
データの準備
最初にAWSのコンソール画面からユーザーの追加を行います。(これは初めて使う場合のみで2回目以降は不要です。)

実行ロールの設定がありますがここでは特に関係ないのでそのままにして、「次へ」、「送信」と進みます。

ユーザーが追加されたら右側の「アプリケーションを起動」のプルダウンメニューからCanvasを選択します。

数分経つと下記のような画面が出てきます。New modelを押してモデルの名称を決めます。今回はtitanic_testとします。

次にデータセットのインポートを行います。UI上ではドラッグ&ドロップでローカルからアップロードできるように見えますが現状はまだできないようでした。AWSのS3、Snowflake、Redshiftと連携してデータを取り込むことができます。データをインポートしたらモデル上でデータを選択します。
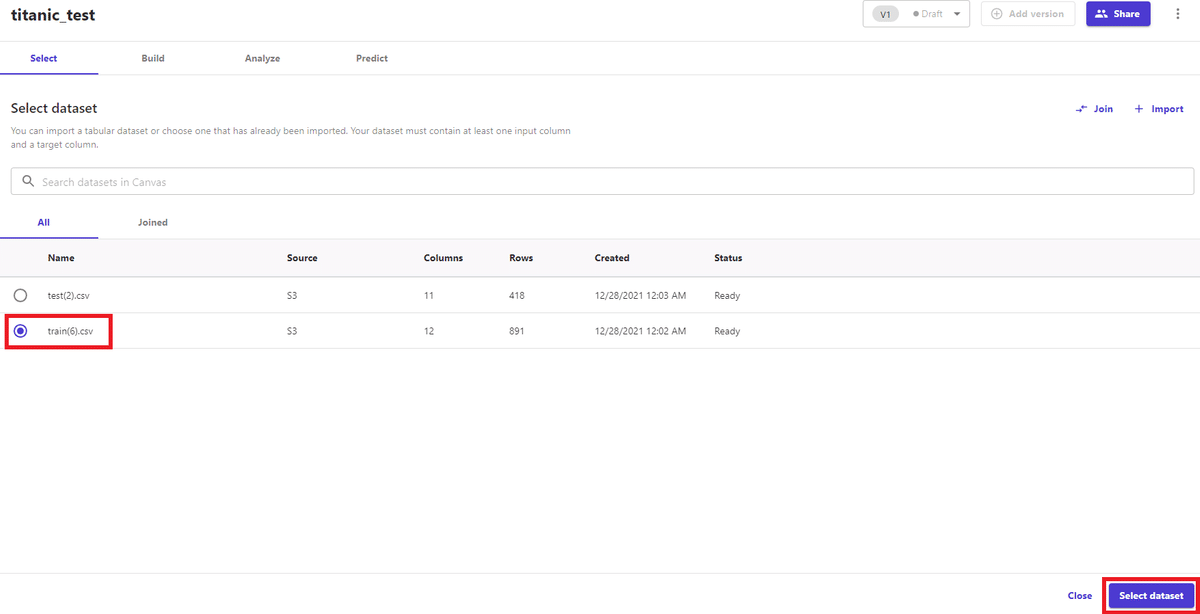
すると下記のようなダッシュボードが表示されます。画面左のアイコンを操作することで簡易的な集計が表示されます。
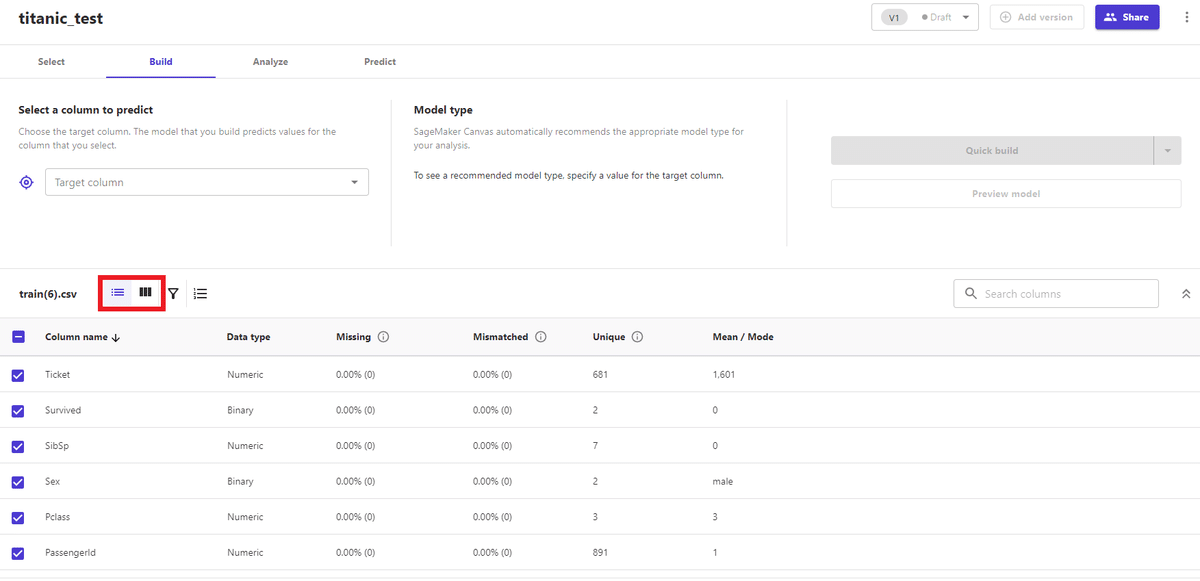
目的変数(column to predict)としてSurvivedを選択し特徴量から不要なカラム(PassengerId)のチェックを外すと、画面右側のモデル作成のモードを選択できるようになります。モデル作成はstandard buildとquick buildの2種類があります。

ちなみに画面真ん中のModel typeを選ぶと下記のように他の推論タイプを選ぶこともできます。

モデリング実行前にPreview modelを押すと簡易的な予測精度(正解率)と特徴量インパクトが数分で表示されます。

上記の画面右にある青いオブジェクトをクリックするとモデリングが開始されます。画面が切り替わり推定待ち時間が表示されます。
モデル作成と結果の確認
ここからはquick build/standard buildでそれぞれ実行した結果を説明します。
quick build
モデリング実行中の待ち時間はKaggleのタイタニックデータでは2~15分と表示されましたが、実際に測ってみたところ1分未満で完了しました。
学習が終わると下記のように結果の概要が表示されます。最初のOverviewタブでは特徴量インパクトと、目的変数の値ごとの特徴量分布が表示されます。縦軸はImpact to predictionという指標のようですがどのように算出しているかは分かりませんでした。

Scoringタブに切り替えるとサンキーダイアグラムで可視化されたモデルの予測精度を確認することができます。件数も確認でき、trainセットの80%で学習、残りの20%のホールドアウトデータで予測がされているようです。

右側のAdvanced metricsを押すとおなじみの混合行列形式でのモデル精度が表示されます。

最後にテストデータでの精度検証のために上部のpredictタブに切り替え、testデータセットを選択します。testデータは予めS3などにアップしておく必要があります。
予測にはtestデータ全体に対して予測値を付与するBatch predictionと一サンプルごとに予測を返すSingle predictionの2種類があります。予測ファイルをDLして中身を見ると、予測ラベルだけでなく確率値も併せて出力されていることが確認できます。
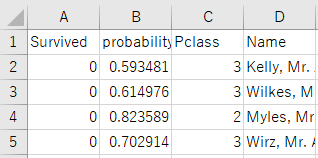
Kaggleで実際に提出したときの精度(正解率)は下記のようになりました。

standard build
比較として、モードをquick buildからstandard buildに切り替えた場合も試してみました。モデリングにかかった時間は推定待ち時間が1時間45分と表示され、実際に計測したところ1時間22分ほどかかりました。精度はvalidation foldでの正解率スコアが86.3%と2.5pt向上しました。ただしvalidation foldのデータ数が205件と全体891件中の23%となっておりなぜこの数値になっているかは不明でした。
モデルアウトプットとしては特徴量インパクトや精度のビジュアライゼーションはquick buildと同様に表示されます。更にstandard buildではShare with SageMaker Studioを行うことが可能になります。

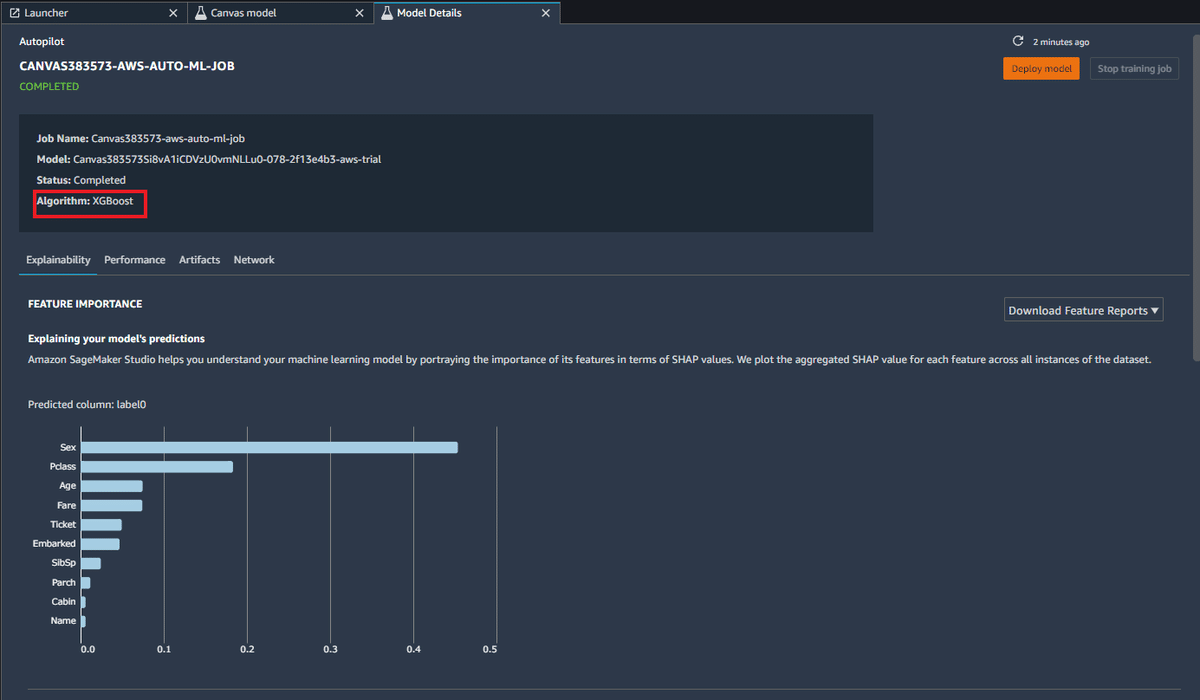
これを実行するとURL Linkが発行され、それにアクセスするとJupyter Lab環境が立ち上がります。Model overviewのBest modelをクリックするとより詳細なモデル情報を参照することができます。モデルのアルゴリズムとしてはXGboostが使われているようです。
更に下に画面をスクロールすると設定されたハイパーパラメーターの一覧も確認できます。

最後にtestデータでの精度ですが下記のようになり0.045ptほど向上しました。

モデル作成後の本番環境での使用
standard buildでは通常のSageMakerと同様にモデルを本番環境にデプロイして予測を行うことができます。
例えばエンドポイント設定は最初のAWSコンソールからSageMakerのページに移動し「推論」の「エンドポイント設定」からモデルを選び「エンドポイント設定の作成」を押して行います。
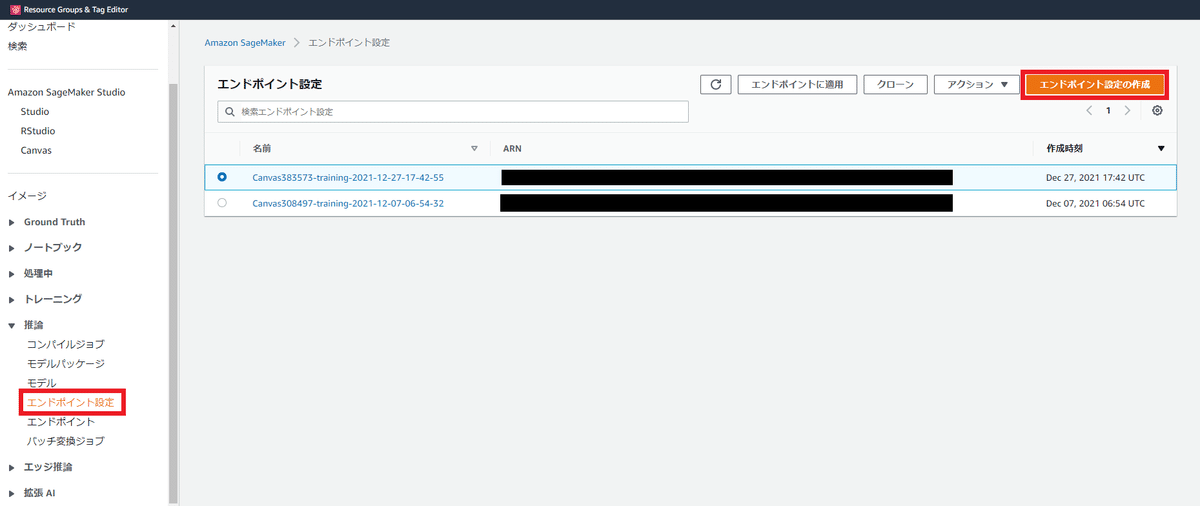
細かい設定方法は公式のマニュアルなどをご参照下さい。
なお、quick buildではこのような機能は執筆時点(2022/01/07)では無いようでした。
DataRobot
データの準備
最初に画面右上のデータセット名が表示されている箇所をクリックし「新プロジェクトを作成」を選択します。
画面上にtrainデータをドラッグ&ドロップすると設定画面が表示され、目的変数やその他の高度なオプションの設定を行うことができます。(ここでは導入用に最も簡易的な使用ケースを示していますが、機能としては他クラウドサービスで管理しているデータを読み込むこともできます。)

また画面を下にスクロールすると各特徴量のEDAを見ることができます。

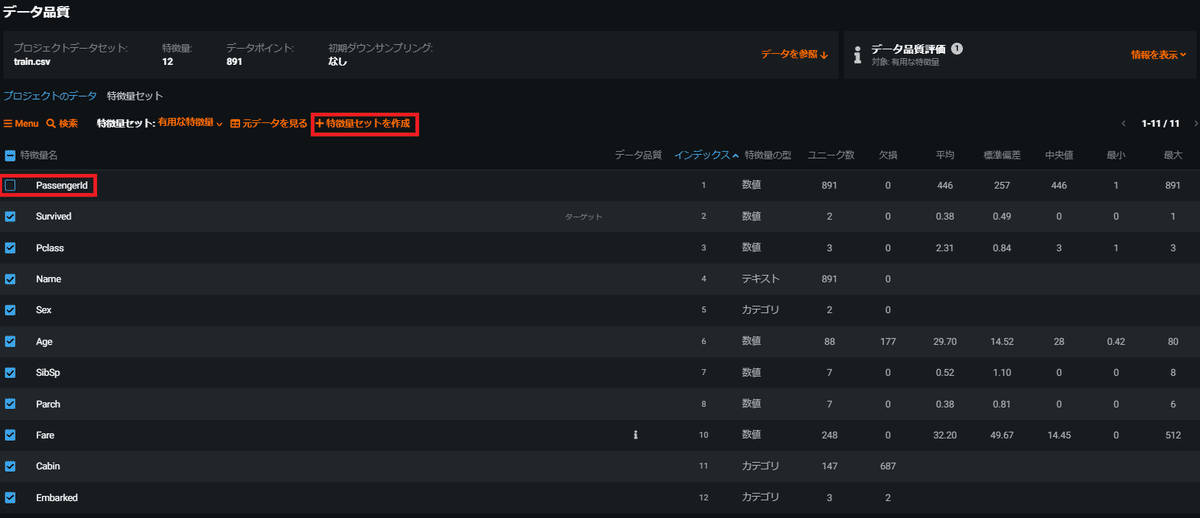
ここでは特に高度な設定は変更せずそのままにしておきます。特徴量は自動でDataRobotが判断した有用な特徴量(Ticket列を除いた11特徴量)でモデリングするようになっていますが、SageMaker Canvasとの比較のためPassengerIdも取り除いた10特徴量で実行してみます。下記のようにチェックボックスで残す特徴量を指定して新たに特徴量セットを作成します。
モデリングのタイプは4種類から選ぶことができますがここではSagemaker canvasとの比較からまずはクイックを選択します。

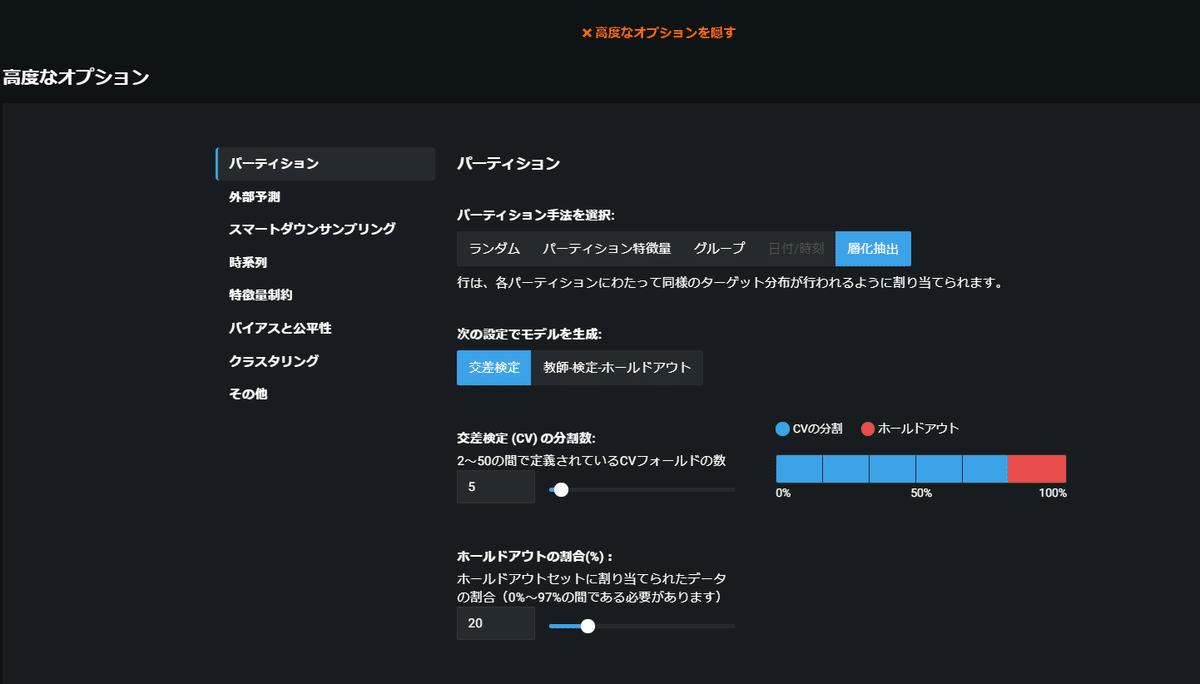
ちなみに、高度な設定では下記のような項目を設定することができます。ビジネスユーザーには使いこなすのが難しいものもありますが、ある程度モデリングに習熟した人であればかなりかゆいところまで手が届く設定ができます。
モデル作成と結果の確認
上記の開始ボタンを押すとモデリングが開始されます。
クイックモード
実行中はワーカーごとに並行して異なるモデルでの学習が行われ、随時結果がリーダーボードに追加されていきます。下記の画面左側のリストが学習の完了したモデルのリストとなっており、デフォルトで精度の良い順に並んでいます。画面右側の帯ではワーカーの実行状況を確認することができます。
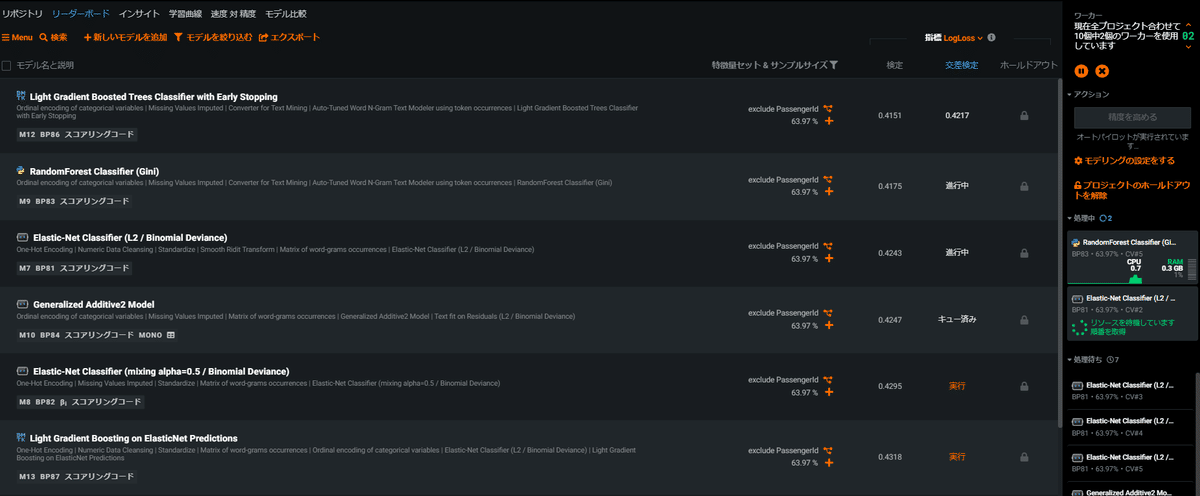
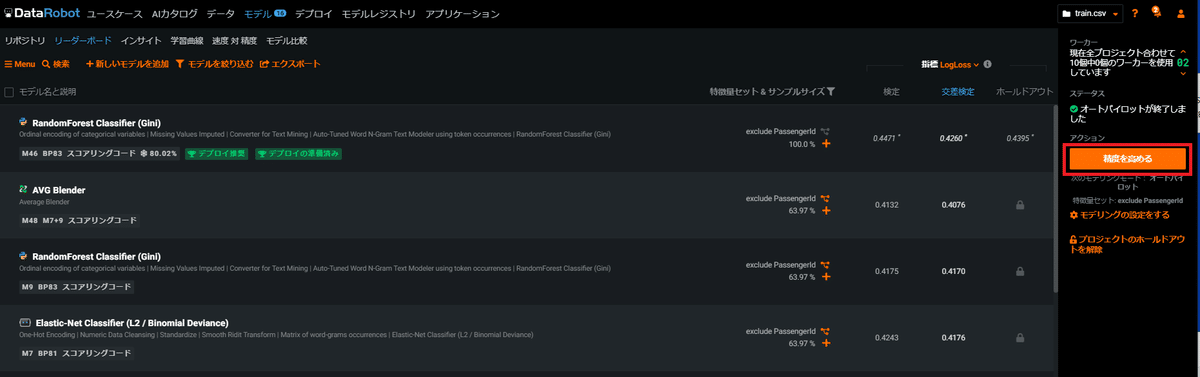
今回は2ワーカーで試し全体の学習時間は33分程度でした。(ライセンスに応じてワーカー数を増やすこともでき、その場合はより短い時間で終わります。) SageMaker Canvasのquick buildと比べると長く感じますが、学習が終わったモデルはリーダーボードからすぐに確認できるようになっているので先に出来上がったモデルを見ながら体感的にはすぐ終わりました。最終的には16個のモデルが作られ最も精度が良かったのはRandom Forestとなりました。
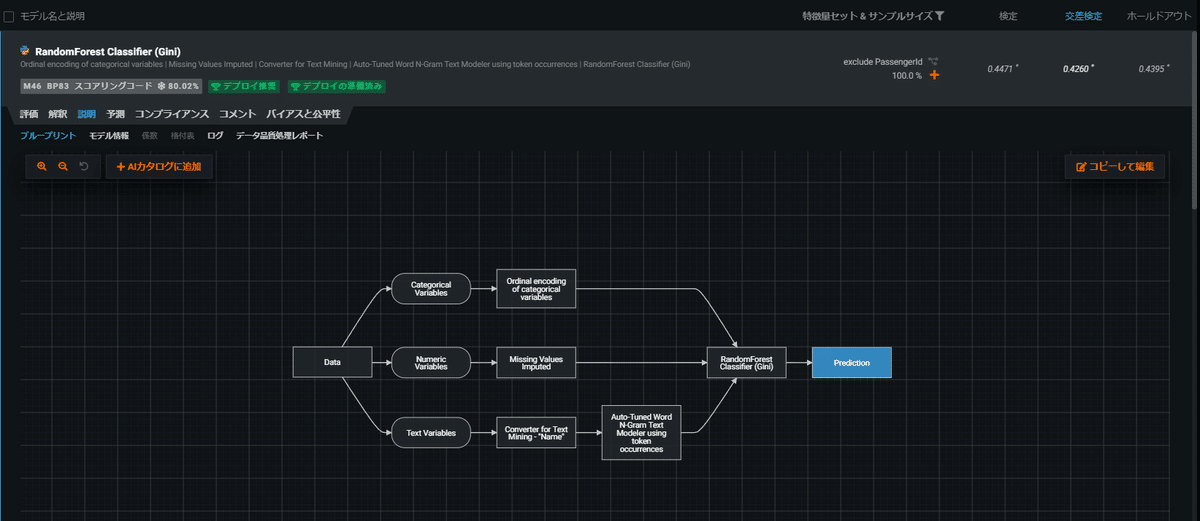
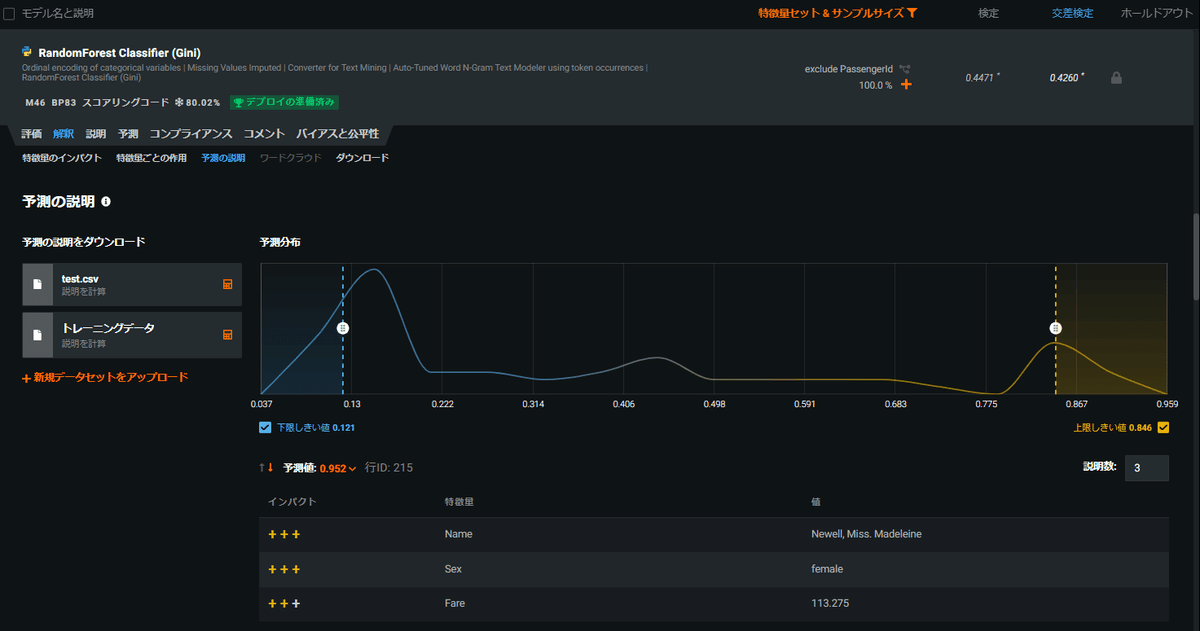
ダッシュボードからモデルを選択すると色々な観点からモデリング結果を見ることができます。一つ一つの項目を列挙するだけでもとても多いのですが、精度では評価タブのROC曲線等が、説明性では解釈タブの特徴量のインパクトや説明タブのブループリント、予測の説明が参考になります。

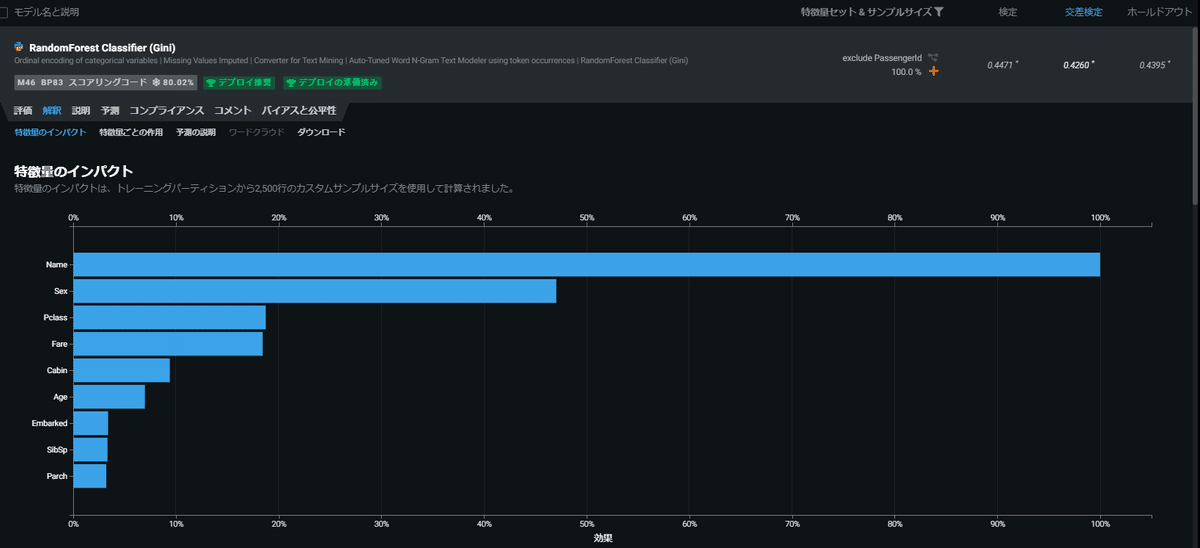
このほか、学習曲線や速度 対 精度等のモデル自体の品質を把握するための可視化も用意されています。
予測を行う際は予測タブからモデル予測を選びます。DataRobotでは予測時に閾値を選択できます。SageMaker Canvasの方では0.5を閾値にしているようでしたので、ここでは比較のためにそのままにしておきます。冒頭でtrainデータをアップロードしたときと同様にドラッグ&ドロップで簡単にデータを取り込むことができます。

予測が完了すると「予測をダウンロード」で予測データを取得できます。SageMaker Canvasと同様に予測ラベルとスコアが出力されます。

Kaggleでsubmitすると精度は下記の通りとなりました。SageMaker Canvasのstandard buildの結果(78.0%)と比べても良い結果となりました。

オートパイロットモード
ここからは上記のクイックモードとの比較でオートパイロットモードを試してみます。DataRobotの結果画面ではクイックモードが完了すると、画面右側の帯にオートパイロットモードがサジェストされるのでそのまま実行します。
実行時間は2ワーカーで53分ほどかかり、追加で29個のモデル学習が行われクイックモードと合わせると45個のモデルが作られました。最終的なモデルは勾配ブ―スティングツリー分類器が選ばれました。下記はそのモデルのブループリントです。モデル自体のタイプだけでなく、各説明変数の特徴を踏まえた前処理(ワンホットエンコーディング、欠損値補完、テキストデータのN-グラム特徴量化)も行われていることがうかがえます。

先ほどと同様に予測を行いKaggleでsubmitしてみたところ精度は下記のようになりました。予想に反してクイックモードよりも精度は低下してしまいました。SageMaker Canvasのquick buildよりは良いですが、standard buildの78.0%を若干下回る結果となりました。

恐らく、学習に使えるデータ量がそこまで多くないにも関わらず複雑なモデルを構築してしまい過学習してしまったか、もしくはquick buildがたまたま高くなってしまったかもしれません。
ちなみに、オートパイロットモードでの実行が終わると更に精度を高めるために包括的モードのサジェストが出ますが、今回は比較が目的のためここで終わりにしたいと思います。
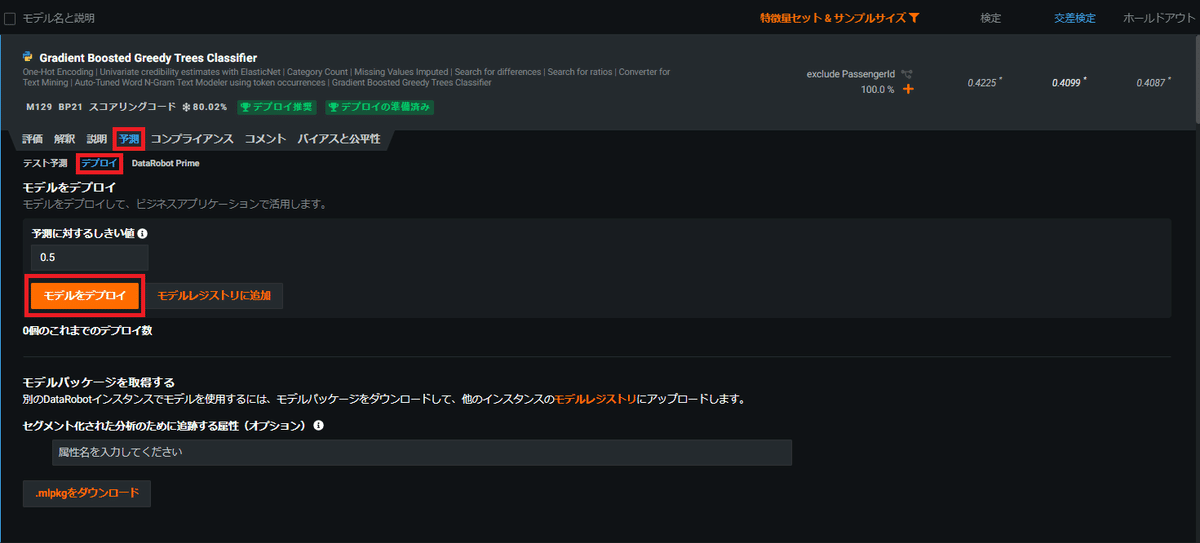
モデル作成後の本番環境での使用
構築したモデルを本番環境へデプロイする機能もDataRobotには搭載されています。 下記のように当該モデルの予測タブからデプロイと選ぶことで簡単にモデルを本番環境での実稼働に移行することができます。 またDataRobotには精度監視やリーケージ検出の機能も搭載されています。
最後に
本記事ではAWSとDataRobotを両方使えるという自社の環境を活かして両サービスの比較をしてみました。今回ハンズオンを通して感じたのは導入するにあたっては単純にモデル精度の良し悪しだけでなく会社の環境や人材を考慮してサービスがうまくワークするかを考える必要があるということです。
具体的にはSageMaker Canvasは自社のデータ基盤をAWSで構築している場合やAWSエンジニアがいる場合にはモデルのデプロイや運用まで同じクラウドプラットフォーム内で行えるという利点があります。一方DataRobotは説明性が求められる際に複数モデル間の比較や各種XAIのアウトプットも見ることができる他、AzureやGCP等との連携、デプロイ・運用まで見据えた機能が搭載されています。
この記事がサービスの導入を検討されている方の参考になれば幸いです。
注釈
予測精度については細かいチューニングを行うことでスコアを向上させることも可能だと思いますが、ここではあえてデフォルトのままで比較しています。また予測精度は今回扱ったデータセットの場合はこうなったという一つの事例に過ぎませんのでこの結果が一般化できるものではないことをご留意ください。
純粋なモデリング機能以外の部分は記事の分量の関係から割愛したところも多いため、詳しく比較したい方は各サービスの公式ドキュメント等をご参照ください。