
Google Colabで統計的因果探索手法BMLiNGAMを動かしてみた

電通デジタルでデータサイエンティストをしている中嶋です。
前回の記事は「GoogleColabで統計的因果探索手法LiNGAMを動かしてみた」でした。
Advent Calendar 11日目となる本記事では前回に引き続いて因果探索手法の紹介です。今回はBMLiNGAM(Bayesian Mixed LiNGAM)の解説及び、こちらの実装を参考にしたGoogle Colabでの分析例について紹介します。
この記事は前記事「Google Colabで統計的因果探索手法LiNGAMを使う方法」の続編です。LiNGAMとは何かをまず知りたい方は先にご一読されることをお勧めします。
また、最初にLiNGAM自体の復習をしていますが、既知の方は読み飛ばしていただいてもかまいません。
LiNGAMの復習
LiNGAMとはLinear Non-Gaussian Acyclic Modelの略で、下記の条件を仮定した構造的因果モデルのことを指します。
・変数間の関係が線形
・外生変数として非ガウス分布を仮定
・非巡回なグラフ構造
具体的には下記のような式で定式化されます。

xiは観測変数を表しp個あり、eiは外生変数でモデル式で表現されない変動要素を表します。
LiNGAMは因果探索手法のうちセミパラメトリックな手法に属します。LiNGAMではありませんが因果探索の枠組みでは他にもパラメトリックな手法、ノンパラメトリックな手法も存在します。
BMLiNGAMについて
定式化
通常のLiNGAMとの違いを踏まえながらBMLiNGAMの考え方について解説します。
まずそもそもの問題としてLiNGAMでは未観測共通原因がある場合、それを切り分けて因果係数の値を推定することができません。そのため未観測共通原因がある場合にはモデルの拡張を考える必要があります。その一般的な形は下記の式で定式化されます。

ここでxjは観測変数、fℓは未観測共通原因を表しており、これらの変数はどちらも非ガウスな連続分布に従うものと仮定します。LiNGAMの時と比べて未観測共通原因を想定しているため、第二項の和が追加されています。この式の因果係数bijの推定には独立成分分析を用いるアプローチと混合モデルに基づくアプローチがあります。今回扱うBMLiNGAMは後者の方のアプローチになります。前者のアプロ―チについて説明は割愛しますが、興味がある方は参考文献[1]のP131以降を読まれるといいと思います。
混合モデルに基づくアプローチ
ここからは混合モデルに基づくアプローチでのbijの推定方法を説明します。そもそもの話として上記の式でbijの推定を難しくさせているのは何かというとそれはもちろん未観測共通原因があるためです。なので未観測共通原因がないようにモデルをとらえなおすことを考えます。そのために上記で書いた式を(n個の)観測ごとに添え字mを使って書き、未観測変数の和を表す第二項をμiとします。

このように書くと第二式はμiを切片とする未観測共通原因のないLiNGAMとして捉えなおすことができます。ただしここで出てくるμ^(m)_iはmが異なっていても同じ分布に従いますが、観測ごとの値は異なるものになります。とはいえこのようにすることで未観測共通原因の個数を表すLや、未観測共通原因から観測変数への直接因果効果を表すλiℓを推定することなく、目的のbijの推定を行うことができます。ただし代わりに導入したμ^(m)_iの推定を行う必要がありこれはnp個と元のデータ数n個よりも多く存在します。そこでこれらの変数に対して事前分布を設定しベイズの枠組みでモデル選択を行うことで推定を行います。具体的には構造的因果モデルの候補を用意して、それぞれの周辺尤度を計算して比較することで正しいモデルにより近い方を判定し、そのあとに係数bijを推定します。
2変数の場合
上記の説明の最後の部分に関して観測変数を2変数x1,x2のみとした場合を考えてみます。この場合因果の方向としてはx1→x2とx2→x1のどちらかになります。因果がないモデルも考えられますがこれは因果のあるモデルと比較するより、x1→x2とx2→x1それぞれの周辺尤度が互いに近いかや推定された係数bijが0に近いかで判断することが多いようです。さて先ほどの因果の向きごとにモデルA、モデルBとしたときに、得られた観測データXから背後の因果モデルがモデルAである対数事後確率logp(MA|X)、モデルBである対数事後確率logp(MB|X)の比較を考えます。ここでMA,MBはそれぞれモデルA、Bを表しています。これに対してベイズの定理を用いて計算すると、詳細は割愛しますが、

の比較に帰着できます。この式は各モデルの尤度p(X|θ,M)をモデルパラメータθで周辺化して対数を取ったものとなっており、対数周辺尤度と呼びます。ここでθは因果を表す係数bijと観測ごとの切片項μ^(m)_i、そして外生変数eiの標準偏差をベクトルとしてまとめたものとなります。また、ηはθのハイパーパラメータベクトルを表しています。(説明の都合上モデルの区別を表す添え字は省略しています。)
この対数周辺尤度の大きい方から小さい方を引いた差を2倍した値を因果モデルの判定に用い、経験的にこの値が10より大きいと対数周辺尤度の大きい方のモデルが「非常によい」と考えます。この考え方の背後にはベイズ因子という指標が関係していますが詳細は下記の記事を参考にしてください。
Bayes Factors Robert E. Kass &Adrian E. Raftery
ちなみにベイズ因子(ベイズいんし、英: Bayes factor)とは周辺尤度の比のことを指し、ベイズ統計の枠組みで仮説検定を行う際の指標として使われています。前述の因果探索で使う指標はベイズ因子Kを用いると2logKと表すことができます。
3変数以上の場合
観測変数が3変数以上の場合は、未観測共通原因があってもよいという仮定から、2変数を選びそれ以外の観測変数を未観測共通原因に含めて因果探索を行うことで因果を推定できます。観測変数の中から変数の組ごとに上述の方法で因果探索を行い、抽出された因果を元に観測変数全体での因果グラフを描くことで、全体の因果モデルを推定します。ただし、最終的な因果グラフは適宜冗長な有向辺を削除します。
BMLiNGAMの利点
ここでは上記で紹介したBMLiNGAMについて通常のLiNGAMと比較したときの利点について私が考えるものを紹介します。
・未観測共通原因を考慮した因果グラフを生成できる
通常のLiNGAMでは冒頭に述べた3つの条件に加えて未観測共通原因が無いことを仮定していますが、BMLiNGAMは混合モデルに基づくアプローチで未観測共通原因がある場合でも使える手法になります。
・推定された因果の信頼度を表す指標が得られる
上記でも説明しましたが、この指標があることで推定した因果がどれくらいの信頼性があるか分かり、より妥当な因果推定を行うことができます。
BMLiNGAMの欠点
・計算に時間がかかる
BMLiNGAMでは周辺尤度の計算にモンテカルロ積分を用いるため、高速な計算方法が利用できる独立成分分析のアプローチに比べて、計算に時間がかかる可能性があります。
利用方法
ここでは冒頭のBMLiNGAMの紹介ページにある実装をGoogle Colab上で行うときの方法について説明します。
環境準備
1. BMLiNGAMライブラリのDL
からDLできるBMLiNGAM-0.1.5-py2.py3-none-any.whlをColabNotebookを作成するGoogle Driveフォルダにアップロードします。
2. Google Colab上での設定
下記の要領でColab Notebook上のフォルダ指定や一部ライブラリのバージョンを変更します。適宜コピペして実行してください。
from google.colab import drive
drive.mount('/content/drive')
# Gdriveにアップしたwhlファイルを実行してBMLiNGAMをインストールする
!pip install "/content/drive/My Drive/projects/BMLiNGAM/BMLiNGAM-0.1.5-py2.py3-none-any.whl"
# ライブラリのバージョン指定
!pip install scipy==1.2.1scipyのversionですが、後述の
!bmlingam-make-testdata --csv_file=sampledata.csvのテストデータ生成時にImportError: cannot import name 'logsumexp'というエラーが出る場合に指定してみて下さい。
3. 一部コードの修正
BMLiNGAM-0.1.5-py2.py3-none-any.whl内のコードはgithub上に公開されているコードですが最新の修正が反映されていないため、下記のようにnotebook上から手動で変更を加えます。
# コマンドライン実行のコード修正
!sed -i -e '278 s/df.as_matrix()/df.values/g' /usr/local/lib/python3.6/dist-packages/bmlingam/commands/bmlingam_causality.py
# BMLiNGAMの因果係数推定のコード修正
!sed -i -e '11 s/estimate_coeff_posterior/bmlingam_coeff/g' /usr/local/bin/bmlingam-coeff
!sed -i -e '17 s/estimate_coeff_posterior/bmlingam_coeff/g' /usr/local/bin/bmlingam-coeff
!sed -i -e '412 s/Model(verbose=verbose)/Model()/g' /usr/local/lib/python3.6/dist-packages/bmlingam/bmlingam_pm3.pyテストデータでの動作確認
上記の準備によりコマンドラインの実行は動くようになっているため、参照先のtutorialに沿って実行してみます。
# 人工的にデータを生成する。動作確認用なので、実データで試すときは不要。
!bmlingam-make-testdata --csv_file=sampledata.csvここでは理論上の式を基に人工的にデータを生成しています。具体的には実装サイトのこちらでデータを生成しています。観測変数の数を2としているので式としては下記のようになります。

ηi がxiの平均を表し、リンク先の式ではmus[i]に対応します。これは観測データmごとに変化せず一定となります。μ^(m)_iは未観測共通原因の線形和を表しており、リンク先の式ではconfs[:, i]に対応しています。外生変数e^(m)_iはes[:, i]に対応しています。(i=1,2)
試しにこのデータに対してBMLiNGAMを実行してみます。
# 計算結果を格納するフォルダを作成する。
!mkdir /content/result1
# BMLiNGAMのテスト実行
!bmlingam-causality sampledata.csv --result_dir=result1アウトプットとしては下記のようになります。

上記の出力について説明します。
"2 * log(p(M)) - log(p(M_rev))": "0.8340870058070777"
この値が先ほどBMLiNGAMの説明で出てきたベイズファクターで、この値が大きいほど因果の向きの推定に自信があることを示すものです。p(M)がここで提示された因果の向きとなるモデルの周辺尤度で、p(M_rev)が逆向きの因果となるモデルの周辺尤度を表しています。今回は0.8程度なのでそこまで自信がある結果ではありませんが、その下の"Infered causality"では正しい向きが推定されています。ちなみに2倍しているのは便宜上都合がいいためで本質的な意味はありません。
最後に補足ですが、Google Colabでは変数の数やデータの行数が多すぎたりすると、実行途中でも^Cの表示が出て勝手に停止してしまうことがあるため、実データで試す際はサンプリングしたものを用いるとよいと思います。
上記の出力以外にresult配下には下記のファイルが出力されます。
/content/result1/
┣ causality.csv
┗ x1_src_x2_dst.bmlm.pklzcausality.csvでは推定された因果の組と推定された向き及び、逆向きの事後確率が出力されます。x1_src_x2_dst.bmlm.pklzはBMLiNGAMの出力をpklzファイルにまとめたものです。
最後に因果効果を表す係数の推定を行います。
# 因果効果を表す係数の事後分布を計算する。
# この係数は、原因変数を1増加させたときの結果変数の増加量を表す。
!bmlingam-coeff result1/x1_src_x2_dst.bmlm.pklzアウトプットは下記のようになります。

先ほどのInferred causality : x1_src -> x2_dstの因果係数が
Posterior mean : -1.520275
95% Credible interval: (-1.894511, -1.148403)として出力されています。この部分は分布として下記のように可視化できます。
# 因果効果を表す係数の事後分布の可視化
from IPython.display import Image,display_png
display_png(Image('./result1/x1_src_x2_dst.bmlm.png'))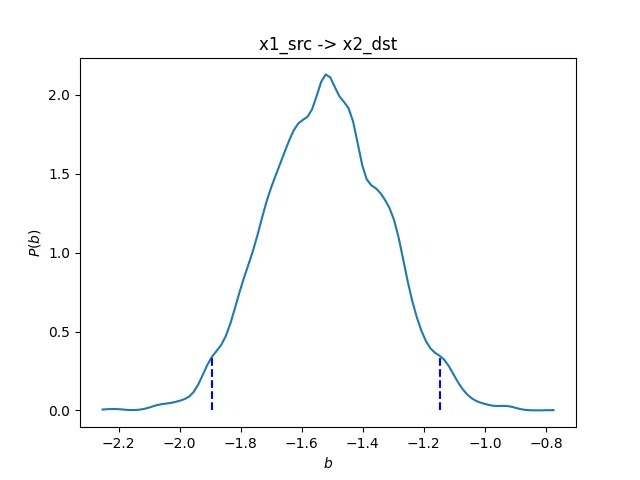
上記のように因果効果を表す係数(この場合はb12)の事後分布をサンプリングすることで因果効果の変動を直感的に把握することができます。これもBMLiNGAMの利点の一つと言えると思います。
最後に
因果推論はデータサイエンス領域において最近色々な書籍が出版されたり、企業でも因果推論のソリューションが出てきたりしてかなり注目を浴びているテーマだと思います。
個人的には因果探索も可能性はあると考えていますが、産業領域での応用は現状は因果推論ほどではないと感じています。この記事を見てLiNGAMやBMLiNGAMを試してみてくれる人が増えてくれるといいなと思います。
次回の記事は「データサイエンティストでもできるサーバーレスなWebフォーム開発 」です。
参考文献
・統計的因果探索(機械学習プロフェッショナルシリーズ)著者:清水昌平
[1] https://www.kspub.co.jp/book/detail/1529250.html
・BMLiNGAM github
[2] https://github.com/taku-y/bmlingam