
[競馬予想AI] LightGBMで着順を予想してみよう

今回はLightGBMを使って予想をしてみたいと思います。
競馬予想AIの一番初めに使ったのはXGBoostでしたが、LightGBMとXGBoostは決定木でブースティングを用いる点は同じですが詳細な仕組みは少し異なります。詳細な仕組みについては割愛します。XGBoostとの精度比較や将来的なアンサンブルを考慮して今回はLightGBMで予想を行ってみようと思います。
LightGBMはランク学習の時に既に使用していますが、分類のアルゴリズムが異なります。
XGBoostを使った場合
はじめに、競馬予想AIで一番初めに使ったアルゴリズムでもあるXGBoostの性能についておさらいしておこうと思います。以下はハイパーパラメータチューニング済みのものです。XGBoostのチューニングはhyperoptを使用しました。
正解率:79.20%
F1:0.3411
適合率(Precision):0.5621
再現率(Recall):0.2449
ROC-AUC:0.7650
LightGBMによる予想
続いてLightGBMによる予想を行ってみます。今回はいっきにハイパーパラメータのチューニングまでやってみましょう。
LightGBMのハイパーパラメータチューニングですが、今回はOptunaのLightGBMを使用してチューニングしています。Optunaに含まれているLightGBMを使うと通常通り学習させるだけでパラメータをチューニングしてくれます。つまり、どのパラメータをどの範囲で探索するか設定する必要がないのでとても簡単です。Optunaをインストールしてimport文を次のように置き換えるだけでOKです。
#このimportを
import lightgbm as lgb
#このように書き換える
from optuna.integration import lightgbm as lgbパラメータには最低限、次の2つを指定しておくだけで大丈夫です。
param = {
'objective': 'binary',
'metric':'auc',
}'objective'は'binary'(二値分類)を指定しています。'metric'は評価指標で'auc'(ROC-AUC)を指定しています。例によって、扱っているデータは不均衡データですので評価指標に'acc'(正解率)を指定してしまうとすべて'0'と答えてしまう使えないモデルが出来てしまいます。
別途アーリーストッピングも設定しておいた方がよいでしょう(アーリーストッピングの値はチューニングされません)。
あとは通常通りモデルを学習させます。
# モデルの学習
model = lgb.train(params,
lgb_train, #トレーニングデータ
valid_sets=lgb_eval, #検証データ
early_stopping_rounds=20 #アーリーストッピング
)10分弱でチューニングが終わりました。
チューニングされたパラメータは次のようにして確認できます。
model.paramsチューニングされるパラメータには次のようなものがあります。主に正則化や葉の数、バギングに関するパラメータになります。
'feature_pre_filter'
'lambda_l1'
'lambda_l2'
'num_leaves'
'feature_fraction'
'bagging_fraction'
'bagging_freq'
'min_child_samples'最も良かったイテレーション数は次のようにして確認できます。
model.best_iteration最も良かったスコア(最適化した指標)は次のようにして確認できます。
model.best_sccoremodel.best_sccoreはパラメータで指定した評価指標の最もよかったスコアですので、今回'metric'に'auc'を指定しているのでROC-AUCの最もよかった値になります。'metric'には'binary_logloss'(交差エントロピー誤差)なども指定できます。
予測精度の確認
最適化したモデルを使って実際にテストデータを予測した結果は次の通りです。
各種指標
正解率:85.97%
F1:0.2940
適合率(Precision):0.2331
再現率(Recall):0.3976
ROC-AUC:0.7755
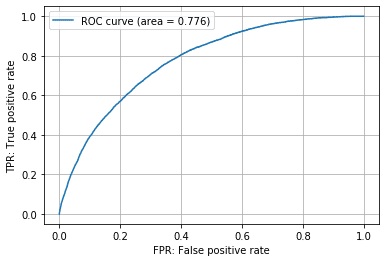
ROC-AUCは0.7755とまずまずの結果ではないでしょうか。XGBoostとほぼ同等の精度が出ており、深層学習モデルのROC-AUCは約0.73でしたのでそれよりも性能はよいと言えそうです。
2値分類なので最終出力値の閾値の調整によって適合率と再現率の調整は可能です。
最後に単勝と複勝の回収率も見ておきましょう。
単勝
的中率:27.17%
回収率:76.53%
複勝(1着と予想したものが複勝圏(1~3着)だった場合)
的中率:57.94%
回収率:82.06%
単勝馬券よりも複勝馬券のほうが回収率で上回る結果となりました。
モデルの最終出力は各馬の1着になる確率ですので、これが馬の強さだと仮定し降順に並び替えれば最終的に着順が予想できることになります。よって、全馬券の回収率について計算も可能です。ちなみに一番高かった回収率は3連単の100.9%でした。
まとめ
今回はLightGBMによる着順予想を行ってみました。
今まで作ったモデルと同等かそれ以上の精度が出たと思います。Optunaによるパラメータチューニングが便利すぎたのもあり、簡単にモデルを作成することができました。最適化も数分で終わるのでとりあえず試してみるモデルとしてLightGBMはおすすめです。
最後に
今回も久しぶりのnote更新となりました。
何をしていたかというと、データ処理のためのモジュールを作っていました。機械学習では試行錯誤はつきものでついついコードが煩雑になりがちですが、この度ついにコードの整理を行いました。
データの前処理や予測、回収率を計算する処理は同じなのでその部分をまとめてモジュール化しました。これで少しはストレスなく作業ができることでしょう。
次回からは、モデルの精度に大きく影響する「特徴量の選択と作成」を予定しています。
特徴量の選択と作成はAI・機械学習のキモとなる部分で、この工程次第で使えるAIになるかならないかが決まると言っても過言ではありません。またドメイン知識も必要になりAI作者の腕の見せ所となります。と、ハードルを上げましたがどのように作業を行ったか、性能は向上したのかも含めて次回紹介できたらと思います。
もし今後も競馬予想AI開発を応援していただける場合はサポートいただけますと幸いです。
いいなと思ったら応援しよう!
