
スケーラブルで効率的なFine-Tuning of LLM on Azure ML

AI - Machine Learning Blog が良かったのでまとめてみた。
Scalable and Efficient Fine-Tuning of LLM on Azure ML | Microsoft Community Hub
🚀この記事のポイント
Azure ML上での分散学習手法としてDDPとFSDPを活用.
1台のGPUノードから3台にスケールさせることで、ファインチューニング速度が3倍に向上.
V100(16GBメモリ)を複数ノードで組み合わせ、70BパラメータのモデルをFSDPでフルシャーディングしファインチューニングに成功.
NDシリーズはInfinibandによる高速通信により、大規模な分散学習に適している.
NCシリーズは小規模から中規模のワークロード向け.
Mixed Precision TrainingやGradient Checkpointing、Quantization、Offloadingなどのメモリ最適化技術も重要.
大規模言語モデル(LLM)は、その拡大し続ける機能によって業界を変革し続けているが、それらを効率的かつ大規模にファインチューニングすることが重要な課題になっている. ファインチューニングとは、これらの汎用モデルを特定のタスクに最適化するプロセスを指す. 例えば、法的文書の要約、クリエイティブな文章作成、または顧客レビューの感情分析など. しかし、LLMの巨大なサイズと計算負荷は、ファインチューニングを容易なものとはしない. このブログでは、Azure Machine Learning(Azure ML)で大規模ファインチューニングを行うための戦略を深掘りし、分散学習によるパワフルな実験結果を共有する. さらに、興味をそそる実験結果を用意している:
1台から3台にスケールアップすることでファインチューニングが3倍速になった.
古いV100 GPUを使って70Bパラメータのモデルをファインチューニングできた. これは効率的な分散学習技術のおかげ.
自分で試してみたくなる?
https://github.com/james-tn/llm-fine-tuning/tree/main/opensource_llm/single_step
なぜスケーラブルかつ効率的なファインチューニングが重要か
素早いイテレーションと短い価値実現時間
今日の競争が激しいAIの世界では、時間が極めて重要. モデルをより早くファインチューニングできれば、アイデアの検証、仮説のテスト、ソリューションの市場投入を早めることができる.
高額なGPUマシン
高性能GPUやコンピュートクラスターは安くはなく、利用可能枠も限られる. モデルシャーディングや分散学習などの効率的なファインチューニング手法は、これら貴重なリソースの利用率を最大化し、インフラ投資から最大限の価値を引き出す.
Azure MLのGPU Computeを使うときはNCか NDか
すべてのGPUコンピュートが同じわけではなく、正しいSKUの選択が学習効率を左右する.
NDシリーズ: 複数ノードをまたぐ分散学習に最適. IB(Infiniband)接続により、高速なノード間通信が必要な事例で役立つ. たとえば巨大LLMの事前学習や非常に大きなモデル(〜70Bパラメータ)のファインチューニングに適している.
NCシリーズ: ノード間の重い通信が不要な小〜中規模ワークロードに向いている. たとえばLLM推論や中規模LLMのファインチューニングなど

シナリオ別Azure GPUマシンの選択肢
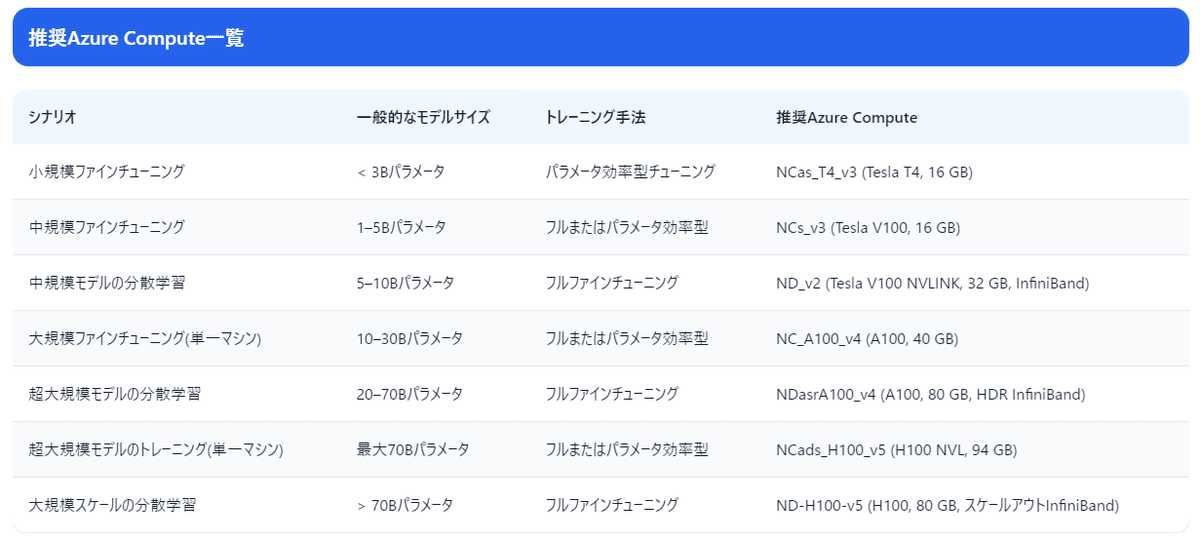
分散かつ効率的な学習: クイックガイド
ファインチューニングをスケールさせる際、適切な分散学習手法の選択が鍵となる.
DDP(データ並列化): モデル全体が単一GPUに収まる場合に有効. モデルを複数GPUに複製し、データを分割して並列処理する. 以下のセクションの実験1を参照.
DDP(Distributed Data Parallel、分散データ並列)は、PyTorchにおけるデータ並列化手法の一つで、複数のGPUやマシンを活用してモデルの学習を高速化するための仕組みです。
モデル並列化: 単一GPUに収まらない巨大モデルには画期的. データだけでなく、モデルのパラメータやオプティマイザステートを複数GPUに分割し、LLaMA-70Bのような大規模モデルを低メモリGPU上でも効率的に学習できる. FSDPやDeepSpeedは、高度なモデル並列化とメモリ最適化を実装するのに優れている.
FSDP (Fully Sharded Data Parallel) は、PyTorch における分散データ並列トレーニングのための機能の一つで、非常に大規模なモデルを効率的にトレーニングするために設計されています。FSDPは、モデルの重み(パラメータ)を 完全シャーディング(分割) し、GPUメモリ使用量を最小化しつつ、大規模モデルの学習を可能にします。
DeepSpeedはChatGPTのようなモデルのトレーニングをワンクリックで可能にし、最新のSOTA(最先端)RLHFシステムと比較して15倍の高速化を実現します。さらに、あらゆるスケールでこれまでにないコスト削減を提供します。
メモリ最適化手法
Gradient Checkpointing: バックワードパス時にアクティベーションを再計算することでメモリを削減. 計算量増とのトレードオフ.
Mixed Precision Training: FP16やBF16を使ってメモリ使用量を削減しながら、学習速度を高め数値安定性を保つ. 両フレームワークでサポート.
Quantization(DeepSpeed限定): ウェイトやアクティベーションをINT8で扱い、メモリと計算量を劇的に削減.
Offloading(DeepSpeed限定): オプティマイザステートやモデルパラメータをCPUやNVMeに退避し、GPUメモリを計算に使いやすくする.
実験: スケーラビリティの限界に挑戦
実験1: DDPを使った複数ノードの分散学習
Llama-3.1-8BモデルをLoRA(Low-Rank Adaptation)を用いてファインチューニングする実験をAzure ML NDv2-V100ノード上で行った. 1, 2, 3ノードとノード数を変えながら学習時間とスループットの変化を観察することが目的.
Azure MLジョブのYAML定義例
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
type: command
code: ./ # トレーニングスクリプトや関連ファイルのパス
inputs:
model_dir:
path: azureml://registries/azureml/models/mistralai-Mistral-7B-v01/versions/19
command: >
accelerate launch
--num_processes 16 # gpu per machine * num of machines
--num_machines 2
--machine_rank $NODE_RANK
--main_process_ip $MASTER_ADDR
--main_process_port $MASTER_PORT
compute: azureml:ndv2-cluster
resources:
instance_count: 2 # 分散学習用のノード数
distribution:
type: pytorch
process_count_per_instance: 1 # ノードあたりのプロセス数
結果

実験2: FSDPを使ったモデル並列化
パラメータ数70Bのモデルを、わずか16GBメモリのGPU上でファインチューニングするのは不可能に思えるが、FSDP(Full Sharded Data Parallelism)を用いることで達成した. Azure MLのNDv2-V100ノード複数台を使い、データだけでなくモデルパラメータやオプティマイザステートも分割し、フルシャーディングの力を引き出した.
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
type: command
code: ./ # トレーニングスクリプトや関連ファイルのパス
inputs:
model_dir:
path: azureml://registries/azureml-meta/models/Llama-3.3-70B-Instruct/versions/4
command: >
accelerate launch
--config_file "configs/fsdp_config.yaml"
--num_processes 32
--num_machines 4
--machine_rank $NODE_RANK
--main_process_ip $MASTER_ADDR
--main_process_port $MASTER_PORT
train.py
compute: azureml:ndv2-cluster
resources:
instance_count: 4 # 分散学習用のノード数
distribution:
type: pytorch
process_count_per_instance: 1 # ノードあたりのプロセス数
主なポイント
メモリ効率: フルシャーディングにより、メモリが限られたV100 GPUでもLLaMA-70Bのファインチューニングが可能に.
接続が重要: NDノードのIB接続がGPU間通信を円滑にし、今回のような大規模学習を実現するうえで重要な役割を果たした.
コードにアクセス
llm-fine-tuning/opensource_llm/single_step at main · james-tn/llm-fine-tuning
リポ内の実験結果

主要な観察点
メモリ使用
FSDP: パラメータと勾配をシャーディングすることでピーク時のメモリ使用量を削減し、大規模モデル(例:70Bパラメータ)のトレーニングを可能にする。
DeepSpeed ZeRO-3: オプティマイザの状態をCPUメモリにオフロードすることで、メモリ使用量をさらに削減。
最適化手法
Mixed Precision: すべてのモデルでトレーニングを高速化し、メモリ消費も削減。
Gradient Checkpointing: 大規模モデルをGPUメモリ内に収めるために不可欠。
LoRA: Mistral-7BやLLAMA3.3-70Bなどのモデルを効率的にファインチューニング可能。
スケーリング効率
分散構成を用いると、ノード数を増やすにつれてスループットがほぼリニアに拡大。
ハイライト
FSDPを用いることで、ND40_v2(32 V100 GPU)を2ノード使用した構成で、LoRAによるLLAMA3.3-70B-Instructのファインチューニングが可能。
DeepSpeed ZeRO-3を用いれば、14Bパラメータのモデル(Phi4)のフルウェイトファインチューニングを単一のNC96_A100マシンで実行可能。
結論
スケーラブルかつ効率的なファインチューニングは、大規模言語モデルの真の可能性を引き出す鍵. FSDPやDDPなどの分散学習技術を活用し、Azure ML上でコンピュートリソースを最適化することで、巨大なモデルの学習に伴う課題を克服し、コスト削減や価値実現スピードの向上、AIイノベーションを加速させることができる.
今後の取り組み
第2部では、エンドツーエンドのモデル学習、ハイパーパラメータ最適化、テストなどを含む実際のパイプラインセットアップに焦点を当てる. 第3部では、学習済みモデルを実際に活用するためのデプロイについて掘り下げる. 将来的には、特定のファインチューニングシナリオや手法に関するベストプラクティスも取り上げる予定
楽しみです。