
Azure OpenAI Service におけるデータ保存について

AI - AI Platform Blog が良かったのでまとめてみた。
Data Storage in Azure OpenAI Service | Microsoft Community Hub
🚀この記事のポイント
Azure OpenAI は特定の機能を利用するとデフォルトでデータを保存する.
ベースモデルはステートレスで標準 API 呼び出しのプロンプトや完了は学習や改善には使われない.
ファインチューニングやベクターストアなどを使うと、ユーザーの Azure リソース内にデータが永続的に保存される.
データはユーザーのテナント内で暗号化され、削除もユーザー自身で自由に行える.
コンテンツフィルタリングはプロンプトや出力を永続的には保持せず、アビューズモニタリングを無効化すればログの保存もされない.
“Chat on your data” は Azure Search や Blob Storage にユーザーデータをインデックス化して保存する.
取り込まれたファイルやチャットスレッドなどは自動では削除されないため、必要に応じて手動で削除する.
削除はチャットスレッド (Assistants API)、検索インデックス、Blob Storage のファイル単位で実行できる.
リソース全体を削除するとまとめてデータが消去されるが、他の用途がある場合は慎重に行う.
削除後はデータが検索されなくなるため、以降のチャットで参照されない.
デフォルトで保存されるデータ
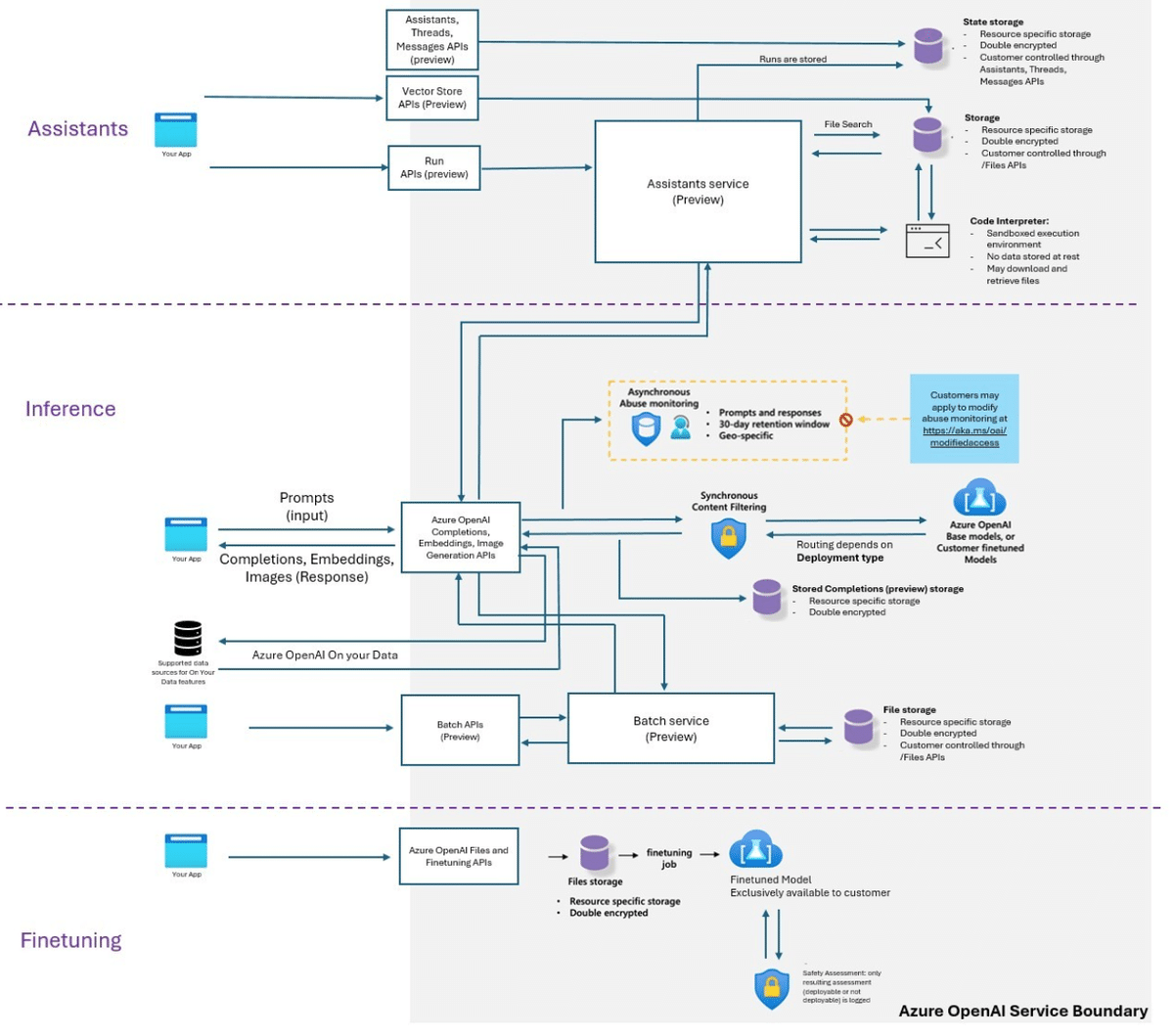
Azure OpenAI は特定の機能を使用するとデフォルトで一部のデータを保存する
ベースモデル自体はステートレスであり、通常の API 呼び出しによるプロンプトや完了 (completion) は保持されない (学習やモデル改善にも使われない)
ただし、ファインチューニング用のファイルアップロードやベクターストアの利用、Assistants API Threads や Stored Completions のようなステートフル機能を有効にすると、そのデータが永続的に保存される
たとえば学習データセットや埋め込みデータ、会話履歴、各機能の出力ログなどが含まれる
これらはすべてユーザー自身の Azure テナント内 (Azure OpenAI リソース) に保存され、同じ地理的リージョンにとどまる
要するに、上記のステートフルな機能を使用するとデフォルトでデータが保存される仕組みになっている
一方、単純な Completions を利用するだけなら、これらの機能を使わないかぎり、プロンプトや出力は永続的に保存されない (一時的な処理を除く)
保存データの場所と削除
保存場所
ユーザーの Azure リソース内: Azure OpenAI が保存するデータは、ユーザーのサブスクリプション/テナント内の Azure OpenAI リソースのストレージに置かれる
同じリージョンでの保管: デプロイしたリージョンに配置され、AES-256 によって暗号化されている
オプションで CMK を使用可能: 一部のプレビュー機能を除き、カスタマー管理キー (CMK) によるダブル暗号化もできる
他のユーザーや OpenAI (企業) がアクセスできないように完全に隔離された状態
データの削除
ユーザーが自由に削除可能: 公式ドキュメントにも、ユーザーがいつでも削除できると明記されている
ファインチューニングや学習データ: ユーザー専用のカスタムモデルやアップロードしたファイルは、必要に応じて削除できる
会話スレッドやバッチ処理データ: Azure ポータルや API を通じて削除できる
基本的にユーザーが管理: Azure OpenAI の各種機能で永続化されたデータはユーザーの管理下にあり、不要になれば削除可能
コンテンツセーフティ機構 (コンテンツフィルタリング・アビューズモニタリング) との比較
コンテンツフィルタリング
リアルタイムチェック: ポリシー違反を検出するために、プロンプトや生成結果をリアルタイムで確認
データの永続保存はしない: フィルタモデル自体にプロンプトや出力を保持せず、フィルタ改善に利用されることもない
解析は一時的: フィルタリング処理は行われるが、プロンプトや出力を恒久的には保存しない
アビューズモニタリング
不正利用を検出: 違反が検出された場合、プロンプトや完了の一部がログに残される可能性
フラグが立つと安全なデータストアに保管: そこに保存されたデータはモデレーション目的のみで使用される
ヒューマンレビュー: Microsoft のレビュワーが違反内容を検証することがある
アビューズモニタリングを無効化した場合 (申請方法ブログはこちら)
承認を得て無効化すると、ログ保存そのものが行われなくなる
プロンプトや完了はリアルタイムでチェックされるが、データは永続化されない
ヒューマンレビューが発生しない (保存データがないため)
Azure OpenAI の “Chat on your data” におけるデータ保存と削除
“Chat on your data” (Azure OpenAI on your data、Assistants プレビューの一部) は、ユーザーが独自にアップロードしたドキュメントを活用して回答を生成する機能
ここでは、どんなデータが保存されるか、どこに保存されるか、どう削除するか を整理する
どのようにデータが保存されるか
データの取り込み (Ingestion) と保存
ユーザー独自のデータ (ファイルや URL など) のアップロード
Azure Blob Storage に一時保存されたあと、Azure AI Search (Cognitive Search) にインデックスされる
アップロードファイル (プレビュー機能) は Blob Storage に保存され、そこからテキストが解析・分割されて Search インデックスに登録される
Web ページをソースにした場合
指定された URL のページ内容を取得し、Blob Storage の専用コンテナに保存
その後、Azure Cognitive Search にインデックス化される
URL ごとに異なるコンテナが生成され、内容が登録される
既存の Azure データストアとの連携
すでに存在する Azure Cognitive Search インデックスや Cosmos DB、Elasticsearch などのベクターデータベースを参照する場合
そのソースにあるデータを直接利用し、新たにコピーしない形も可能
チャットセッションとスレッド
“Chat on your data” は Assistants 機能 によってステートフルに動作する
チャットの履歴 (スレッドやメッセージ)、アップロードファイル などが Microsoft 管理のストレージアカウントに保存される
これらはユーザーの Azure OpenAI リソースごとに論理的に隔離されている
保管場所と保持期間
ユーザーのテナント内、同じリージョン: インデックスやファイル、チャットスレッドなどはそこで永続的に保管される
ユーザーによる削除がない限り残る: ブラウザを閉じたりセッションを終えても、データは消えない
インデックスやファイルは自動で削除されない: 必要に応じて明示的に削除する必要がある
データの削除方法
チャットスレッド (Assistants API) の削除
会話スレッドを削除して、チャット履歴や添付ファイルなどを一括で消去できる
具体的には、DELETE エンドポイントを呼び出してスレッド ID を指定する例:
ruby
Studio の UI 上で「クリア」や「リセット」をしてもデータは残るため、明示的な削除 API を使う必要がある
検索インデックスやデータソースを削除
Azure Cognitive Search インデックスを削除すると、取り込まれたドキュメント情報をまとめて消せる
Azure ポータルや Cognitive Search API で該当インデックスを削除
外部ベクターデータベースを使っている場合は、そちらのインデックスやエントリを消去
Blob Storage に保存されたファイルを削除
ファイルアップロードや URL クロールが行われた場合、Blob Storage にある該当データを消去する
Azure ポータルや Azure Storage Explorer を利用し、関連するコンテナやファイルを削除
たとえば、プレビューの “Upload files” 機能を使った場合は、そのファイルが特定のコンテナに保管されているため、直接削除する
リソース全体を削除 (オプション)
リソースやリソースグループをまるごと削除すると、一括でインデックスやファイルもなくなる
ただし、他の用途があれば影響が出るため注意。不要なインデックスやファイルのみ削除するのが安全
削除後の動作
削除したデータは検索やチャットで再利用されなくなる
新しいクエリ実行時には、現在有効なインデックスやストレージからのみ情報が取得されるため、不要データを消せば回答に影響しなくなる
考慮事項と制限事項
自動削除は行われない: 必ず手動で削除する必要がある
プレビュー機能の制限
現行のプレビュー機能では管理 UI が不十分な場合がある
Azure AI Foundry の UI がデータソースをセッション間で保持しない などの既知の不具合がある
カスタマー管理キー (CMK) がまだサポートされていない などの可能性
データの場所と隔離: すべてユーザーのテナント内の同一リージョンで管理されるため、他のユーザーと共有されることはない
コンプライアンス対応: GDPR や CCPA などに基づき、ユーザーが個人情報を削除することで要件を満たすことが可能
コスト
“Chat on your data” 機能そのものに追加費用はかからない
しかし、Azure Cognitive Search や Blob Storage の通常利用料金が発生する
使い終わったらリソースを削除しないと無駄なコストがかかる可能性
削除後のリファレンス
一度削除したデータは、次回のチャットで参照されない
再度使う場合は、再接続や再アップロードが必要
まとめ
ユーザーが自発的に提供したデータ (ファインチューニング用ファイル、ベクトルデータ、チャット履歴など) は、基本的に Azure OpenAI リソース内に保存される
コンテンツフィルタリングはデータを恒久的に保持しない
アビューズモニタリング (有効な場合) は違反を検知したデータをログに保存するが、無効化すればそこも保存されない
“Chat on your data” 機能は、Azure Cognitive Search や Blob Storage (あるいはユーザーが設定した外部データソース) にデータを保存し、ユーザーが削除を行わないかぎり残り続ける
削除には、Assistants API を使ったチャットスレッド削除、検索インデックス/Blob Storage の削除などが必要
削除を行えば、そのデータは以降の回答で参照されなくなる
不要データを残さないためには、Azure ポータルや API でインデックスやストレージを適切にクリーニングすることが重要
これらのステップを守ることで、ユーザーはデータライフサイクルを管理しつつ、Azure OpenAI の機能を安心して活用できる
🚩最後に
実務で利用される際は、必ずドキュメントを参照してください。
(日々Updateがあるため)
Data, privacy, and security for Azure OpenAI Service - Azure AI services | Microsoft Learn