
Distillation (蒸留): 小型モデルを高性能でコスト効率の高いソリューションに変える技術

Microsoft community blog が良かったので翻訳してみた。
Distillation: Turning Smaller Models into High-Performance, Cost-Effective Solutions
モデル蒸留含めて、Fine-Tuning は 2025年トレンドになるので、押さえておくべき技術かと。Azure でも早くModel Distillation を実施するための Stored
Completions APIがきてほしい!
この記事のポイント
大規模LLM(教師)から小規模モデル(生徒)への知識転移である蒸留は、モデルサイズ縮小や推論コスト低減を実現し、高性能を維持しつつニッチなタスクに最適化された効率的なモデル開発・展開を可能にする。有力な解決策として、大規模モデル特有の速度・コスト課題を軽減。
Azure AI Foundryは、要約、対話、NLU、NLI、MATHなど多様なタスクで蒸留をサポート。合成データ生成やChain-of-Thought等の先進手法により生徒モデルの精度・一般化性能を向上し、短いプロンプトで効率的に指示ベースのファインチューニングが行える。
地域要件(米国西部3、米国東部2)に応じたMeta Llama 3.1やPhi 3シリーズモデルの利用が可能で、Azure SDK/CLI・ノートブック例を通じた実装が提供される。CoT蒸留導入で生徒モデルのNLI精度は大幅改善し、実運用で高速応答と最適化性能を両立できる。
Microsoft Ignite 2024 session でも解説されてるので気になる方は 👇

はじめに
大規模言語モデル(LLM)は、人間のようなテキストを理解し生成する能力で、自然言語処理(NLP)の状況を一変させました。しかし、そのサイズと複雑さゆえに、デプロイ、速度、コストの面で課題が生じることがよくあります。通常、特殊なニッチなタスクの場合、利用可能な最高のモデルをデプロイすることになりますが、その能力をすべて活用しているわけではありません。そこで登場するのが蒸留です。これは、大幅に大規模な最先端モデルのパフォーマンスの多くを維持しながら、より小さく、カスタマイズされ、効率的なモデルを作成(ファインチューニング)する方法を提供します。
蒸留とは?
蒸留は、大規模な事前トレーニング済みモデル(「教師」)の知識を、より小さなモデル(「生徒」)に転送するように設計された技術であり、生徒モデルが教師モデルと同等のパフォーマンスを達成できるようにします。この技術により、ユーザーは大規模なLLMの高品質を活用しながら、より小さな生徒モデルのおかげで、本番環境での推論コストを削減できます。
蒸留はどのように機能するのか?
蒸留では、教師から生徒モデルに知識を転送する方法がいくつかあります。ここでは、特に応答ベースのオフライン蒸留について説明します。ここでは、生徒モデルが教師モデルの出力(予測のみ)を模倣することを学習し、教師モデルは蒸留中にトレーニングされません。
教師モデル: 大量のデータセットで事前にトレーニング済みの、大規模で高容量の教師モデル。このモデルは、データから豊富な表現と複雑なパターンを学習しており、これまで見たことのないタスクでもうまく一般化できます。
知識抽出: 教師モデルは、与えられた入力に基づいて出力を生成し、生徒モデルのトレーニングデータとして使用されます。これには、単に出力を模倣するだけでなく、根底にある推論プロセスを理解することも含まれます。
生徒モデルのトレーニング: 抽出された知識をガイドとして使用して、より小さな生徒モデルがトレーニングされます。生徒モデルは、特定のタスクでの教師モデルの動作と予測を模倣することを学習します。
利点
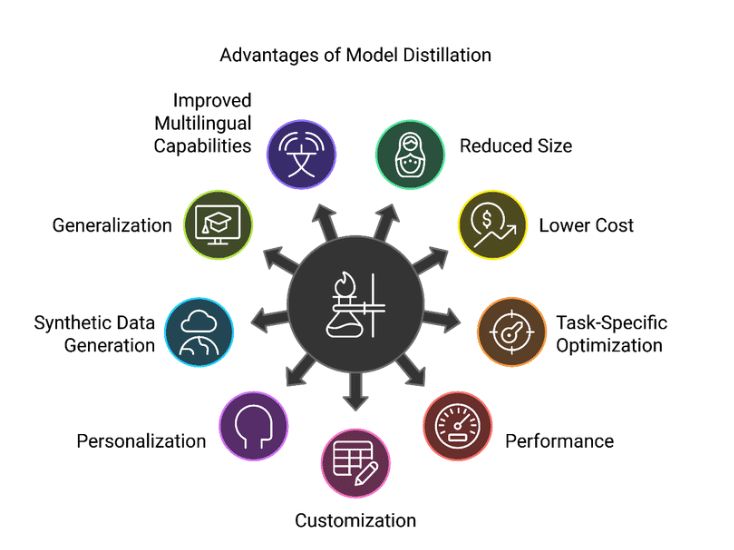
サイズの縮小: 結果として得られる生徒モデルは大幅に小さくなり、リソース制約のある環境へのデプロイが容易になります。
コストの削減: より小さなモデルを実行すると、競争力のあるパフォーマンスレベルを維持しながら、運用コストが低くなります。
タスク固有の最適化: 蒸留は特定のアプリケーションに合わせて調整でき、効率と精度が向上します。
パフォーマンス: より小さなモデルは、より大きなモデルと比較して大幅に低いレイテンシを示し、デプロイのスループットを向上させます。
カスタマイズ: 蒸留を使用すると、ユーザーは複数のより大きなモデルから望ましい特性を選択し、それらをより小さなモデルに転送できます。
パーソナライゼーション: 個性特性をモデルに組み込むことができ、モデルの個性について質問されたときに適切な回答で応答できるようにします。
合成データ生成: 大規模なデータ生成は、ラベルのみ、またはシード/メタデータのみを使用してゼロから行うことができます。
一般化: 蒸留は、教師モデルの知識から学習し、過剰適合を回避することにより、生徒モデルの一般化を改善するのに役立ちます。
多言語機能の向上: 小規模モデルの多言語パフォーマンスは、教師モデルの助けを借りて大幅に向上し、グローバルなアプリケーションに適したものになります。
Azure AI Foundry における蒸留
サービスとしての蒸留が Azure でサポートされるようになり、さまざまなタスクタイプがサポートされ、まもなくさらに追加される予定です。次のタスクがサポートされています。
要約: 要約するドキュメント(記事)が与えられた場合、ドキュメントのエンティティ密度の高い要約を生成します。
会話型アシスタント: 単一ターンおよび複数ターンの会話データセットに関するAIアシスタント応答を生成します。各応答を生成するために、利用可能なチャット履歴と現在のユーザープロンプトが利用されます。
自然言語理解(NLU)
MATH: 数学の問題に対する数値回答を生成します。
自然言語推論(NLI): 前提と仮説が与えられた場合、前提が仮説を意味するか、仮説と矛盾するか、または中立(つまり、仮説を意味も矛盾もしない)かを判断します。
多肢選択問題の回答: 問題と回答の選択肢が与えられた場合、正しい回答の選択肢を決定します。
蒸留プロセス

蒸留プロセスには、教師モデルを使用して高品質の合成データ(ラベル)を生成し、その後に生徒モデルの指示ベースのファインチューニングを行うという、主に2つのステップが含まれます。
データ生成
高品質のデータ生成は、生徒モデルのパフォーマンスにとって非常に重要です。Azureは、Chain of Thought(CoT)やChain of Density(CoD)などの手法や、その他のベストプラクティスを活用して、サポートされているすべてのタスクに対して高品質の合成データを生成する、独自の高度なプロンプトライブラリを提供しています。このオプションは、蒸留パイプラインを呼び出す際に `enable_chain_of_thought` パラメータを渡すことで有効にでき、推論ベースの回答、したがって蒸留用の高品質のデータを保証します。
指示ベースのファインチューニング
次のステップは、タスク固有の生成データを使用して、より小さなモデルをファインチューニングすることです。これには、簡潔でタスク固有のプロンプトを使用し、入力と生成された出力(推論ステップを除く)を使用してトレーニングすることが含まれます。これらのイノベーションは、ユーザーのコスト(トークンの数)を最小限に抑えながら、特定のタスクで大幅なパフォーマンス向上を保証します。ユーザーが提供したプロンプトを使用する場合、同じプロンプトがデータ生成とファインチューニングの両方に適用されます。
蒸留コードスニペット
蒸留は、Azure SDKとCLIでサポートされています。このサポートは、azure-ai-mlのバージョン1.22.0で追加されました。以下のコードスニペットを使用する前に、azure-ai-mlパッケージが>= 1.22.0であることを確認してください。
from azure.ai.ml.model_customization import (
distillation, EndpointRequestSettings, PromptSettings
)
from azure.ai.ml.entities import ServerlessConnection
# Create Distillation Job
distillation_job = distillation(
experiment_name="llama-distillation",
data_generation_type=DataGenerationType.LABEL_GENERATION,
data_generation_task_type=DataGenerationTaskType.MATH,
teacher_model_endpoint_connection=ServerlessConnection(
name="My-Llama",
endpoint="https://My-Llama.westus3.models.ai.azure.com/chat/completions",
api_key="example_key"
),
student_model="azureml://registries/azureml-meta/models/Meta-Llama-3.1-8B-Instruct/versions/2",
training_data="azureml:train_data:1",
validation_data="azureml:validation_data:1",
outputs={"registered_model": Output(type="mlflow_model", name=output_name)}
)
# Set teacher model settings
distillation_job.set_teacher_model_settings(
inference_parameters={"max_tokens": 200},
endpoint_request_settings=EndpointRequestSettings(
min_endpoint_success_ratio=0.8,
)
)
# Set prompt settings
distillation_job.set_prompt_settings(
prompt_settings=PromptSettings(enable_chain_of_thought=True)
)
# Set finetuning settings
distillation_job.set_finetuning_settings(
hyperparameters={"n_epochs": "3"}
)
モデルの提供
教師モデル
現在、蒸留の教師モデルとしてMeta Llama 3.1 405B Instructがサポートされています。
生徒モデル

現在、蒸留の生徒モデルとしてMeta Llama 3.1 8B Instructがサポートされています。まもなく、MicrosoftのPhi 3および3.5 Instructシリーズのすべてのモデルも蒸留で利用できるようになる予定です。次の表は、現在および今後の生徒モデルの提供状況を示しています。
本稿執筆時点では、Meta Llama 3.1 Instructシリーズのモデルのファインチューニングと、このようなファインチューニングされたモデルのデプロイは、米国西部3リージョンでのみ利用可能です。一方、MicrosoftのPhi 3 Instructシリーズのモデルのファインチューニングと、このようなファインチューニングされたモデルのデプロイは、米国東部2リージョンでのみ利用可能です。選択した生徒モデルに合わせて、AI Foundryプロジェクトが適切なリージョンに設定されていることを確認してください。
ノートブック
Distilling Large Language Models for NLI Tasks: A Practical Guide
このノートブックは、特に自然言語推論(NLI)タスクのために、大規模な教師モデルをより小さな生徒モデルに蒸留する方法に関する包括的なガイドを提供します。教師としてMeta Llama 3.1 405B Instructを使用し、生徒モデルとしてMeta Llama 3.1 8B Instructを使用します。
主なハイライト
教師モデルと生徒モデル: このプロセスでは、教師モデルとしてMeta Llama 3.1 405B Instruct、生徒モデルとしてMeta Llama 3.1 8B Instructを使用します。
前提条件: 必要なモデルをサブスクライブし、Meta Llama 3.1 8B Instruct生徒モデルの蒸留のために、米国西部3リージョンにAI Foundryプロジェクトを設定していることを確認してください。
SDKインストール: azure-ai-ml、azure-identity、mlflowなどの必要なSDKをインストールします。
データセットの準備: トレーニングと検証には、Hugging FaceのConjNLIデータセットを使用します。
蒸留ジョブ: 教師から生徒モデルに知識を転送するために、蒸留ジョブを構成して実行します。
デプロイ: オプションで、蒸留したモデルをサーバーレスエンドポイントにデプロイし、サンプル推論を実行します。
このノートブックは、モデル蒸留という複雑なタスクを簡素化し、NLPとモデルトレーニングを初めて行う人でもアクセスできるようにします。
結果
ConjNLIデータセットとChain-Of-Thought(CoT)蒸留を使用して、次の精度(%)メトリクスを取得します。

Meta Llama 3.1 8B InstructとPhi 3 Mini 128k Instruct生徒モデルを使用した蒸留により、CoTプロンプトを使用して生徒モデルに直接プロンプトを出した場合と比較して、それぞれ約21%と31%の改善が見られます。他のデータセットとタスクに関する詳細な結果については、ユーザーは知識蒸留に関する論文で公開された結果を確認してください。
KNOWLEDGE DISTILLATION USING FRONTIER OPEN-SOURCE LLMS: GENERALIZABILITY AND THE ROLE OF SYNTHETIC DATA
結論
蒸留は、大規模なLLM/SLMの開発とデプロイにおける重要な進歩を表しています。大規模な事前トレーニング済みモデル(教師)から、より小さく、より効率的なモデル(生徒)に知識を転送することにより、蒸留は、高コストや複雑さなどの大規模モデルのデプロイに関する課題に対する実用的なソリューションを提供します。この技術は、モデルサイズと運用コストを削減するだけでなく、特定のタスクに対する生徒モデルのパフォーマンスを向上させます。Azure AI Foundryでの蒸留のサポートにより、プロセスがさらに簡素化され、要約、会話型アシスタンス、自然言語理解タスクなどのさまざまなアプリケーションでアクセスできるようになります。さらに、Azure Githubで提供されている詳細な実践的なサンプルノートブックは、より簡単な導入を促進するのに役立ちます。
要約すると、蒸留は、一般的な理解と特殊なアプリケーションのギャップを埋めるだけでなく、現実世界のシナリオでLLMを活用するための、より持続可能で実用的なアプローチへの道を開きます。
※本ブログは、 “Distillation: Turning Smaller Models into High-Performance, Cost-Effective Solutions” を翻訳してます。気になる箇所があれば、原文を確認ください。
Distillation: Turning Smaller Models into High-Performance, Cost-Effective Solutions | Microsoft Community Hub