
RのCSV読み込み関数を比較する"より高速・効率的な処理をめざして"~D4cノウハウプレゼン大公開~

D4cグループで年3回行われているイベント「ノウハウプレゼン大会」から発表をピックアップするシリーズ。
今回は2022年4月の回から、わたくし、T.K.が発表した「RのCSV読み込み関数を比較する」をお届けします!
はじめに
大学での研究活動のなかでR言語に触れてから、私はこれまでRを愛用しています。入社後も、小売系・メディア系などさまざまな案件でRを使用してきました。
分析においては「列が非常に多い」「サイズ数が非常に大きい」など一筋縄ではいかないデータにも直面します。こうしたデータの読み込みにおいて、処理が終わらない・処理時間が長すぎるといった問題を回避するためには、高速なコーディング・負荷の軽減などの工夫が必要です。データを読み込まないことには分析はできないため、「読み込み」は非常に重要な処理です。この記事では、そんなR言語プログラミングにおける「読み込み」のパフォーマンス向上に役立つ情報をご提供します。
この記事のターゲット
・R言語でプログラミングの経験がある方
・CSVファイルの読み込みを多用する方
・R言語を使っていて処理の重さに悩んだことがある方
発表者について
学生時代
・心理学系の専攻(文系)
・行動実験データの分析では主にR言語を使用
入社後
・小売やメディアなどマーケティング系の分析案件を中心に担当
・使用言語はPython・Rなど
4種類のCSV読み込み関数
本発表では、R言語におけるCSVファイルの読み込み関数として、4種類を紹介しています。
utilsパッケージの read.csv()
data.tableパッケージの fread()
readrパッケージのread_csv()
vroomパッケージのvroom()
① utils :: read.csv()
こちらは基本Rの関数です。
【特徴】初学者がいちばんはじめに学習する関数ではありますが、これといった取り柄もなく、特に速度の面では明らかに劣っています(※後述)。パッケージのインストールに制限がない環境では以下に挙げるいずれかの関数を使うほうが賢明です。
② data.table :: fread()
高速な読み込みに特化した関数です。
【特徴】fread()は、大規模データの高速な読み込み・書き出しを実現することで名高いdata.tableパッケージに属する汎用の読み込み用関数です。メリットはやはり安定して高速な読み込みができることです。一方で、エンコーディング(文字コード)時に、Shift-JISを明示的に指定することができない、などの使い勝手の悪さもあります。
③ readr :: read_csv()
tidyverse系のCSV読み込み用関数です。
【特徴】readr は、Rの神と称されるHadley Wickham氏を中心に整備されたパッケージ群"tidyverse"のコアパッケージの一つで、そのうち、read_csv()はCSV読み込み専用の関数です。こちらもread.csv()に比べて高速に処理することができる点がメリットで、Hadleyの著書『Rではじめるデータサイエンス』には、約10倍、との記載があります。
④ vroom :: vroom()
read_csv()の強化版読み込み用関数です。
【特徴】vroomは、2019年にリリースされた比較的新しいパッケージです。ひと言でいえば、vroom()はreadr :: read_csv()の強化版です。このため、関数の基本的な振る舞いはreadr :: read_csv() とさほど変わりません。
CSVファイルを最も高速に読み込めるのは?
これら4つの関数を比較検討した資料はすでにないのでしょうか?結論をいうと、存在します。最後に挙げたvroomでは、リリース元が読み込み処理のベンチマークのテストを実施しており、その結果が公式に発表されています。こちらの発表によると、読み込むデータによって優劣が変わるものの、概ね、data.table :: fread() とvroom() が同程度に優れている、という結果でした。
しかしながら、こうしたテストは環境が違えば結果も異なることが多く、自身の環境において同様の結果となるか確認することをおすすめします。実際に検証することで、関数に対する理解はドキュメントを読む以上に深まることでしょう。ということで、私も自らの環境で試してみることにします。
実行環境
・OS : Windows10
・CPU : Intel core i3
・メモリ : 8GB
読み込みデータ
・Webサイト上で作成したダミーデータを使用
・1,000,000行×14列、うち数値11列、文字列3列
・サイズ : 約70MB
・文字コード : UTF-8
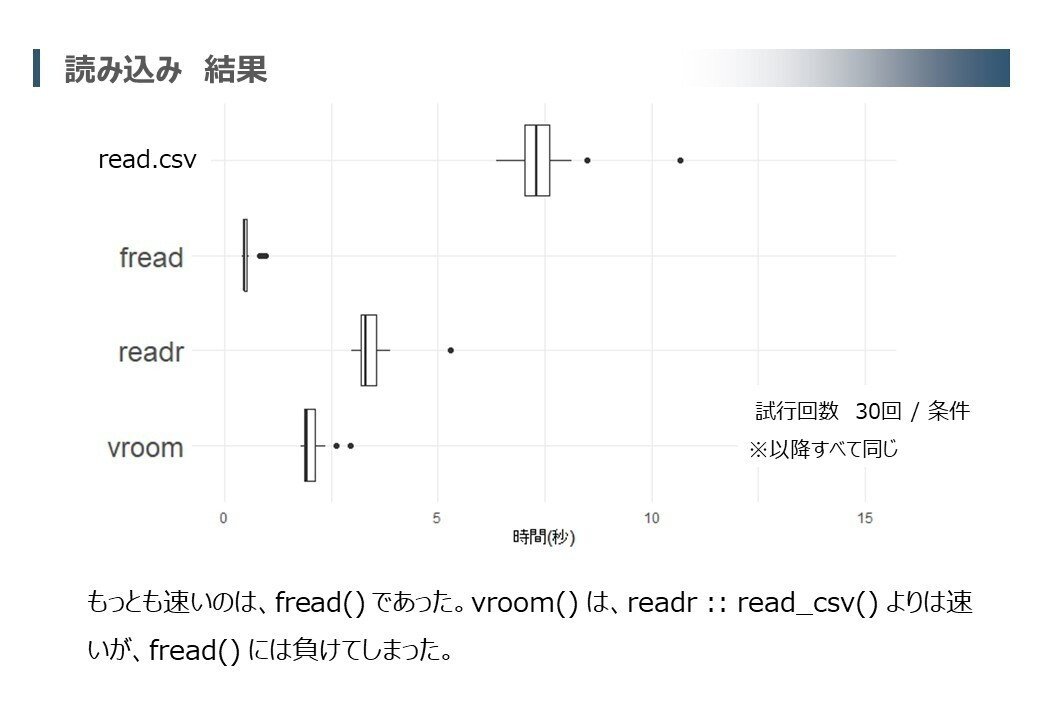
それぞれの関数で各30試行読み込みを実施した結果を箱ひげ図に整理したものです。fread()は最もよいパフォーマンスを見せています。また、基本Rに搭載のread.csv() は、やはり他の関数と比べ明らかにパフォーマンスが劣っています。このあとの検討では、read.csv()を除いた3種類で比較をします。
vroomの公式記事を参照すると、vroom()で読み込んだテーブルに対して集計(aggregate)の操作を施す場合は、実体化したテーブルを参照するため処理速度が遅くなる、という説明があります。そこで、上記のただテーブルを読み込むだけのread条件に加えて(=上の結果と同じ)、読み込んだテーブルに対して集計関数を実行するcalc条件を別に設け、比較してみました。

vroomは、集計処理によって実体化テーブルを参照しなければならなくなってしまったためか、手元の検証ではreadr :: read_csv()よりも遅いという結果になってしまいました。
関数により、データの形状に得意・不得意があることもわかってきました。例えばvroom()は、以下のようなデータ形状の場合、優れたパフォーマンスを得られるようです。
文字列が多い
列数が多い(横長)
そこで、文字列が多く列数が多いデータを別途作成し、試してみることにします。

vroom()のパフォーマンスが大きく変化し、fread()との差が小さくなっています。しかしながら、vroom() は依然、集計処理まで含めた場合の時間のロスが大きく響いています。一方fread() は、安定したパフォーマンスの良さを見せており、最も高速でした。このことから、data.table :: fread()は安定的に優れた結果を残すことができる、といえそうです。
※上記のベンチマークテストの結果はあくまで執筆者の手元の環境で実施したもので、ひとつの参考事例としてお考えください。
関数をどう使い分けるか
上記の通り、fread()は安定して高速な読み込みができる関数ではありますが、欠点もあります。fread()の説明部分でも触れた、Shift-JISを明示的に指定することができない点は、実行環境によって異なる文字コードでreadしてしまう危険があることを意味します。一方、readr :: read_csv() や vroom() では、Shift-JISを含むさまざまな文字コードの指定に対応しています。
また、readr :: read_csv() や vroom()はログの出力も親切設計です。列名の補完やread時の型など、その後のデータ操作において重要な情報を、この2つの関数は自動的にレポートします。fread() にはこうした機能はありません。

まとめると、あくまで読み込み速度を重視するならfread() が第一の選択肢になります。しかしながら、readr :: read_csv() や vroom() も、実用に耐えないほど遅いというわけではありません。したがって、先に述べた速度以外のこうした要素を重視する場合には、vroom() やread_csv() を選択するのもよいでしょう。

最後に
データの読み込みは、ほとんどのデータ分析において最初に突き当たる問題であり、この部分を効率よく進められることは、分析フロー全体においても大きな意味を持つでしょう。この記事が、その一助となれば幸いです。
(書き手:T.K.)
少しでもお役に立てましたら、記事の下の♡を押していただく&フォローいただけますと励みになります!
▼採用情報TOP
▼キャリア採用はこちら
▼新卒採用はこちら
▼D4cノウハウプレゼン大会についてはこちら
https://note.com/d4c_premier_m/n/nb724c6c65a55