
良いコードとは何か - エンジニア新卒研修 スライド公開

CyberZ CTO室のメンバーの森 (@at_sushi_at) です。
先日、株式会社サイバーエージェントの2021年度 エンジニア新卒研修でコードの品質に関する講義を行いました。
そこで話した内容とスライドを完全公開します。
45分の内容のため、かなり長いですが、個人的にぜひ一読して欲しい内容になっています。
はじめに

こんにちは、森 篤史と言います。2019年度入社で今年で3年目になります。株式会社CyberZのOPENREC.tvというプロダクトでAndroidアプリチームのリーダをやっています。
最近はプログラムを書く仕事以外に、次世代マネジメント室という全社横断組織でDevelopers Blogの改善プロジェクトを実行したり、CyberZ CTO室で組織活性化に取り組んでいます。
あと、2019年度の未踏スーパークリエータにも認定されました。

メインの仕事としては、入社してすぐからAndroidアプリのリアーキテクチャプロジェクトを主導しています。JavaからKotlinに、MVCからMVVMとClean Architectureを意識したアーキテクチャに書き換えを行っています。
機能開発も並行して行っており、段階的なリアーキテクチャを実施しています。現在も進行中で、数ヶ月前にプロジェクト内のKotlin率が50%を超えました。

そのプロジェクトを遂行する上で気がついたことが一つあります。良いコードが何かを知らなければ、たとえ書き直したとしても良いコードにならない、ということです。
こう書けば当たり前のように感じますが、私はプロジェクトを開始した当初、モダンなKotlinという言語で最新のライブラリ群を使って書き直せば、前より良くなると思っていました。でも実際は、新しいツールで書かれた汚いコードが出来上がるだけだったんです。
リファクタする際は、ただ書き直すだけでは意味がなく、より良いコードについて深く考える必要があります。

今回のゴールとしては、良いコードとは何か、深く考えるきっかけになれば良いと思っています。

そこで、今回この4つのアジェンダを用意しました。最初は、品質とスピードはトレードオフかという比較的キャッチーな話題から入り、その後、技術的負債に絡めたお話をします。後半は、凝集度や結合度、Clean Architectureの具体的なコードの話に入っていきたいと思います。
![]()
品質とスピードはトレードオフか

それでは、1つ目のトピックス「品質とスピードはトレードオフか」という話題についてです。

しばしば、私達は締切に追われたプロジェクト等で「今は急いでいるので品質より速度優先で!」といったメッセージを見かけます。お偉いさんに言われるケースもあれば、エンジニアが言っているケースもあるでしょう。

ここで一つの疑問が生まれます。果たして、品質とスピードはトレードオフなのでしょうか?
これが正しくなれば、たとえ品質を犠牲にしてもスピードは上がらないことになります。

その前に、品質について深堀りしたいと思います。品質には様々な要素と分類がありますが、ここでは外部品質と内部品質に分けて考えます。
外部品質は、ユーザに見える要素で、例えば仕様どおりに動く、バグがない、高速に動作する等がこれにあたります。
内部品質はユーザから見えない品質で、保守性や柔軟性、可読性、一貫性が当てはまります。

「品質より速度優先」で往々にして犠牲になるのは、ここで言う内部品質の方でしょう。
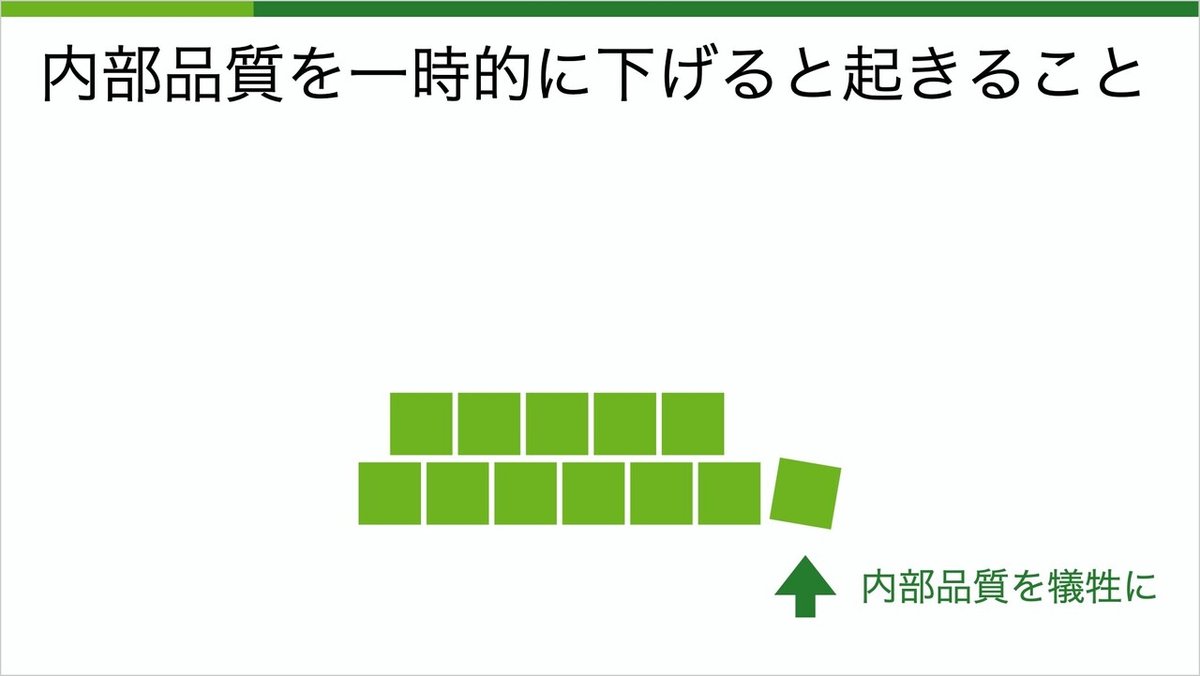
内部品質を一時的に下げるとどうなるのでしょうか?
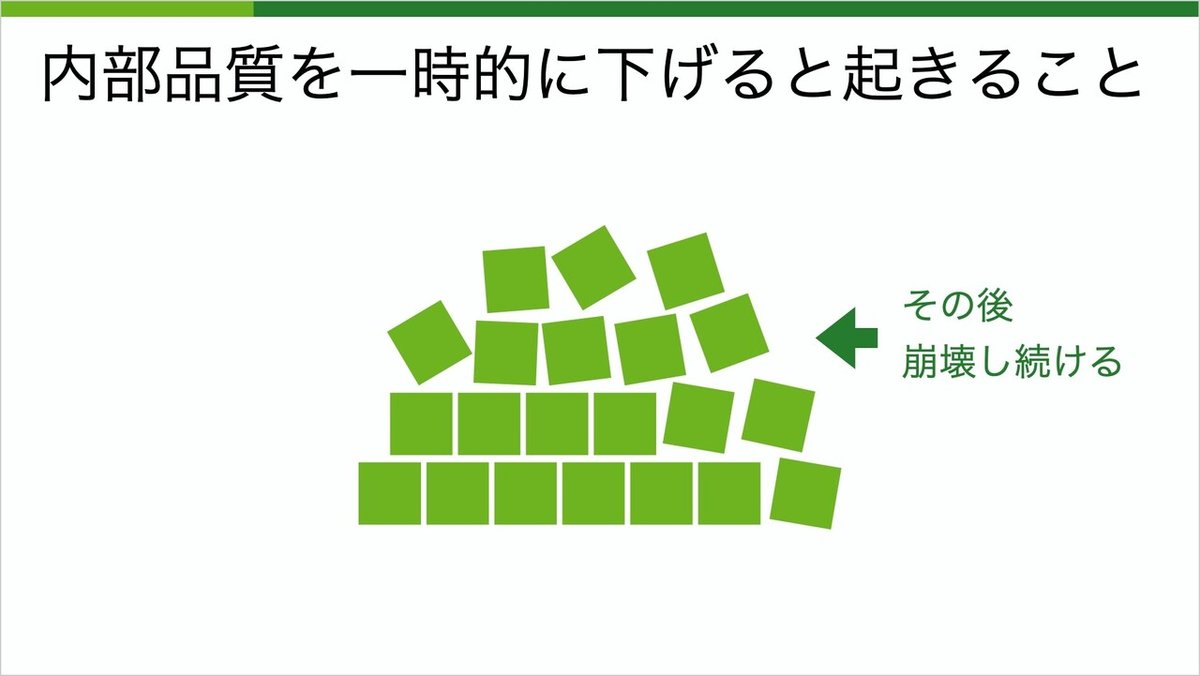
これは非常に抽象的なイラストですが、その後崩壊し続けることになります。おそらく皆さんも一度は体験したことがあるでしょう。

私はこれを、割れ窓理論に似ていると思っています。割れ窓理論は、割れた窓ガラスを放置しておくと、やがて地域全体が崩壊していくという犯罪理論です。コードにおいても、一箇所の汚れが全体に影響を及ぼしていきます。
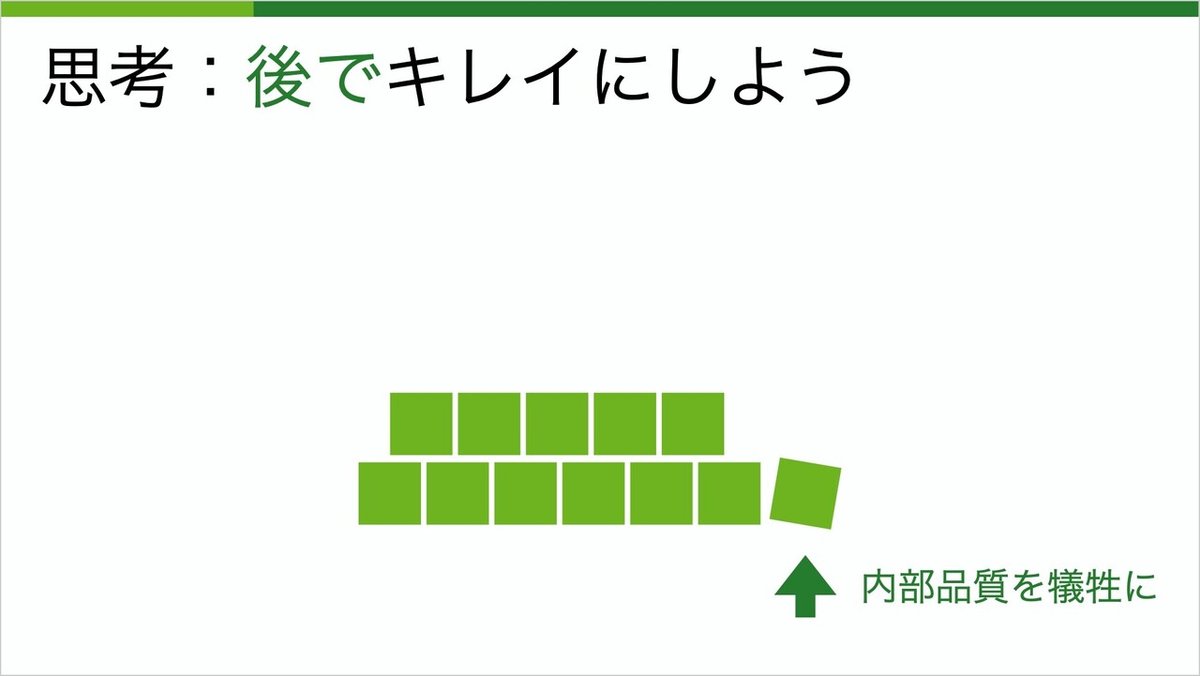
我々は内部品質を犠牲にする際、こう考えるわけです。後でキレイにしようと。

でも、残念ながらその後では来ません。既に締切に追われているということは、市場から求められている、もしくは市場に早く出さないといけないという状況でしょう。その市場からのプレッシャーは、一度出した後も止まることはありません。また、既にある競合他社や今後生まれてくる競合他社に追い抜かれないようにするため、今後も走り続ける必要があります。
そうやって放置された内部品質の犠牲は、崩壊を引き起こし、生産性がゼロに近づいていきます。

品質とスピードはトレードオフか?という質問に対しては、ごく短期的には得られるかもしれない。という回答になると思います。一方、中期的には逆効果になり、長期的には致命的な問題を引き起こします。

ここでいう短期、とはどれくらいなのでしょうか?ここに関しては、人によって言及が異なり、数週間や数日、もしくはその日中に問題になると様々です。
私個人の経験則から言えば、だいたい1週間で問題が発生します。これは、再びそのコード、もしくは関連するコードに触れた際、直ちに問題になります。
思ったより短いと感じたのではないでしょうか。
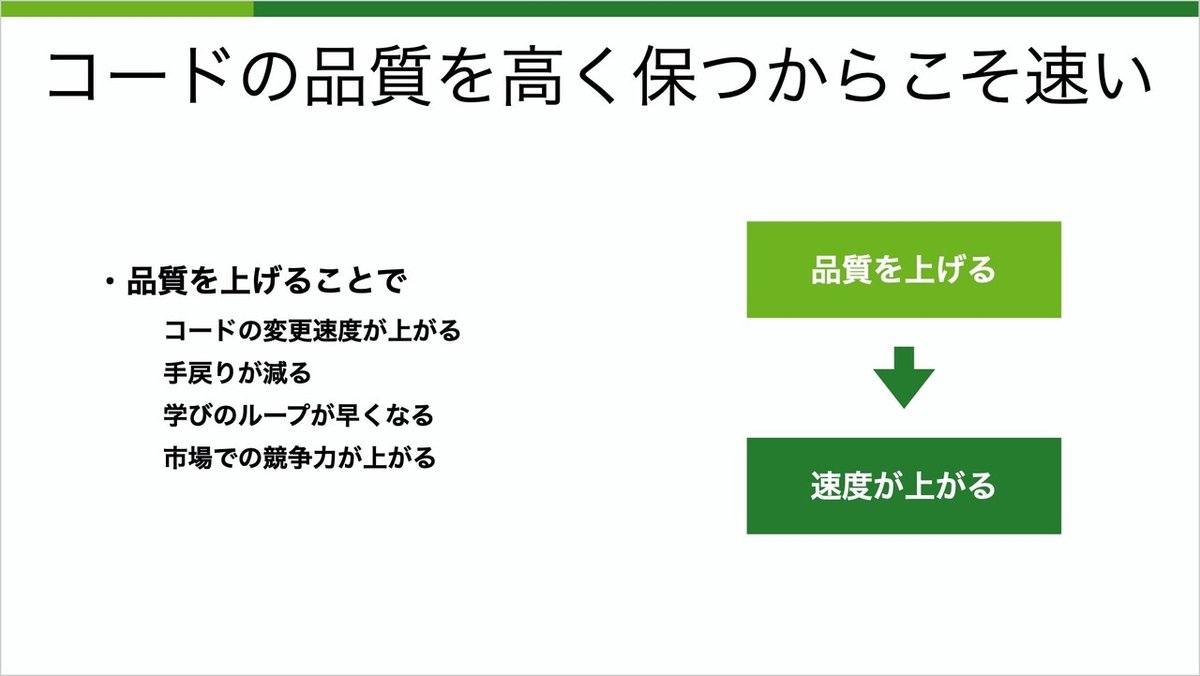
品質とスピードはトレードオフではなく、むしろ正の相関があることがわかりました。品質を上げることで、速度が上がるわけです。
品質を上げることで、コードの変更速度が上がり、手戻りが減り、学びのループが早くなり、市場での競争力が上がります。
ここまで順番に説明すれば当然のことのように感じられるかもしれませんが、私は以前、汚いコードを書き続けたほうがずっと早いと思っていました。また、たとえ理解していたとしても我々は意図的に品質を落とすという判断をしがちです。改めて、この関係について学ぶことは重要です。

ここまで聞いて、なるほどわかったと。品質を下げても速度が上がらないのであれば、じっくり時間をかけてコードを書けば良いのか。そう思う方もいるかもしれません。果たしてそれは正しいのでしょうか?

結論から言うと、不要に時間をかけても品質は上がりません。速度とスピードはトレードオフではない、むしろ正の相関があるわけですから、時間をかけても品質は上がらないわけです。
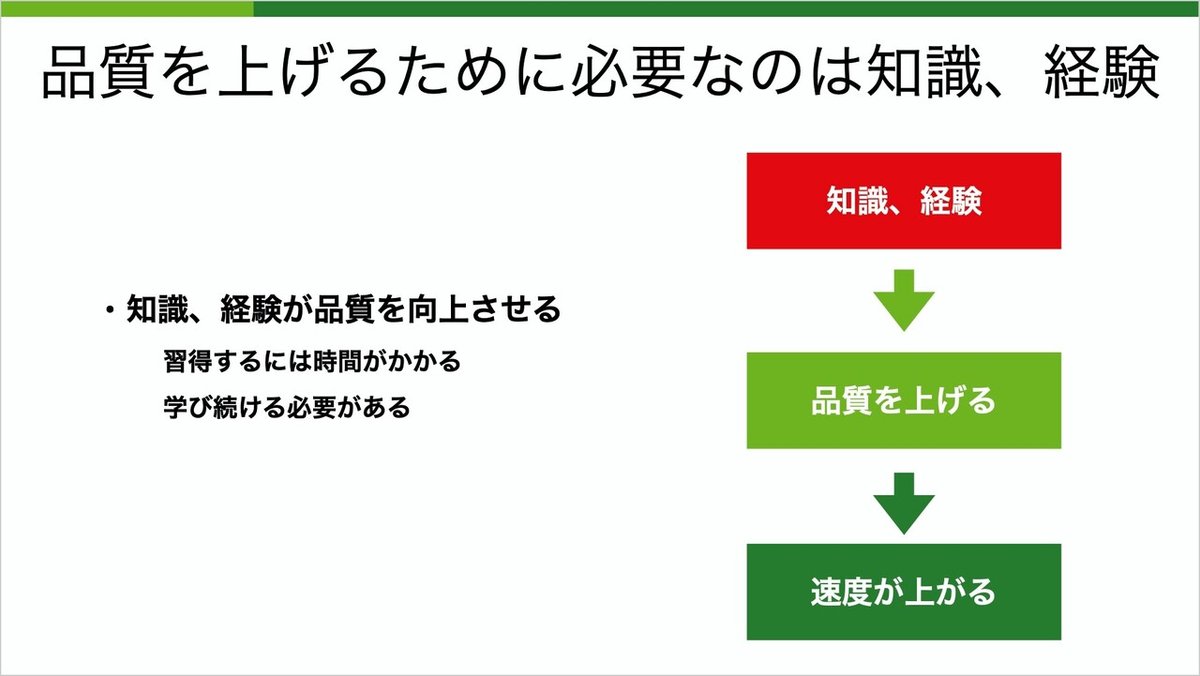
品質を上げるため必要なのは、知識、経験です。少しがっかりされる方もいるかも知れませんが、これは事実です。
知識、経験が品質を向上させ、その結果速度が上がり、市場で成功することが可能になります。この知識、経験を習得するためには長い時間がかかり、また変わりゆく環境に合わせて学び続ける必要があります。
![]()
技術的負債の発生と解消

品質とスピードはトレードオフか?というキャッチーなフレーズから解説してきましたが、次も技術的負債という人気のキーワードを深堀りしていきます。

品質を上げるためには、知識・経験が重要であることを説明しました。では、一体どんな知識・経験が必要なんでしょうか?

品質について考えるため、品質が下がっている状態について考えます。それはすなわち、技術的負債が溜まっている状態、と言えるでしょう。

技術的負債の発生理由を分類してみました。
発生する領域について、大きく2つに分けて技術知識の問題とドメイン知識の問題があります。技術知識の問題は使っている言語やフレームワーク、ライブラリ等で発生する問題です。もう一方のドメイン知識とは、プログラミングの対象の知識を指します。例えば、出前/宅配サービスを開発するためには、お店や配達員に関する知識が必要ですし、送金サービスを開発するためには、お金に対して詳しくなければいけません。
また、発生するタイミングとして、3つのポイントがあります。1つ目は意図的な負債、2つ目は変化による負債、3つ目が学びによる負債です。それぞれ順に説明します。

1つ目の意図的な負債とは、先程の「品質より速度優先で!」によって発生する負債です。技術的負債と言われてこれを思い浮かべる人も多いでしょう。
より良いコードの書き方を知っているのにそれとは異なる書き方をしたり、ドメイン知識を無視して挙動だけを合わせた書き方を行うことを指しています。
これらは、必ず避けられる負債になります。このような場合、品質を削るのではなく、ターゲットを削るか、リリース日を延長すべきと言われています。

2つ目は変化による負債です。こちらも主な技術的負債としてイメージがあるかもしれません。
当初は存在しなかった技術が登場したり、使っていた技術が古くなった、ドメイン知識が仕様変更等に伴い変化した場合に発生します。
こちらは先程の負債とは異なり、比較的予測しにくい技術的負債になっています。一方で、経験を積むことで、想像することは可能になっていきます。例えば、Githubのスター数を見て、継続的にメンテナンスされるかどうかを見極める等です。
こういった負債は、発生後放置すると銀行の利息のように影響範囲が膨れ上がっていきます。負債と呼ばれる所以ですね。発生したタイミングで、早期に改修することが望まれます。

最後は学びによる負債です。こちらはあまりイメージはないかもしれませんが、非常に重要な考え方になっています。
プログラミングを勉強することによって新たに技術知識を得たり、開発を進める上で異なるドメイン知識や、より良いドメイン表現を学ぶことはよくあります。これにより現実と理想で乖離が生じ始め、負債となることがあります。
こういった技術的負債が発生することはむしろポジティブです。一方で、変化による負債と同様、放置していると多大な悪影響を生じさせます。早期に改修することが望ましいとされています。

技術的負債という概念の生みの親とも呼ばれる、Ward Cunninghamは、このように説明しています。
たとえ理解が不完全だとしても目の前の問題に対する現時点での理解でコードを書くことは良いことです。一方で、現時点での理解を可能な限り反映させることが重要です。すなわち、意図的な負債を紛れさせるなと。そうすることで、リファクタリングするときに、新しく学んだ理解に合わせて容易にリファクタリングすることが出来ます。

学びによる負債があることを説明しました。これは、予め学んでおくことである程度避けることができます。これからは、より良いコードとは何か、具体的な指標について話していきます。
![]()
凝集度と結合度

長い長い前置きを経て、ようやく良いコードとは何かの具体的な話に入っていきたいと思います。1つ目のトピックスは凝集度と結合度です。

よくコードレビューなどで、このコードより、こっちのコードのほうが好ましい、といった議論が行われます。

ちょっと性格が悪いようにも感じますが、こういったとき、より良いコードであるという根拠が気になりますよね?
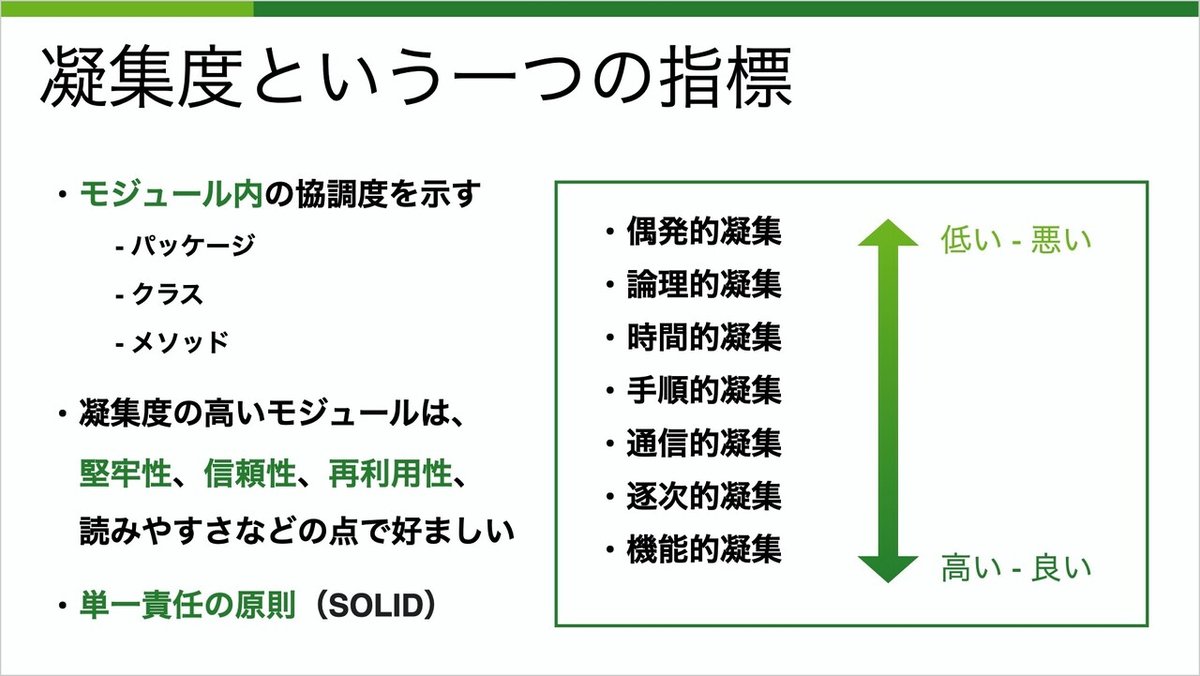
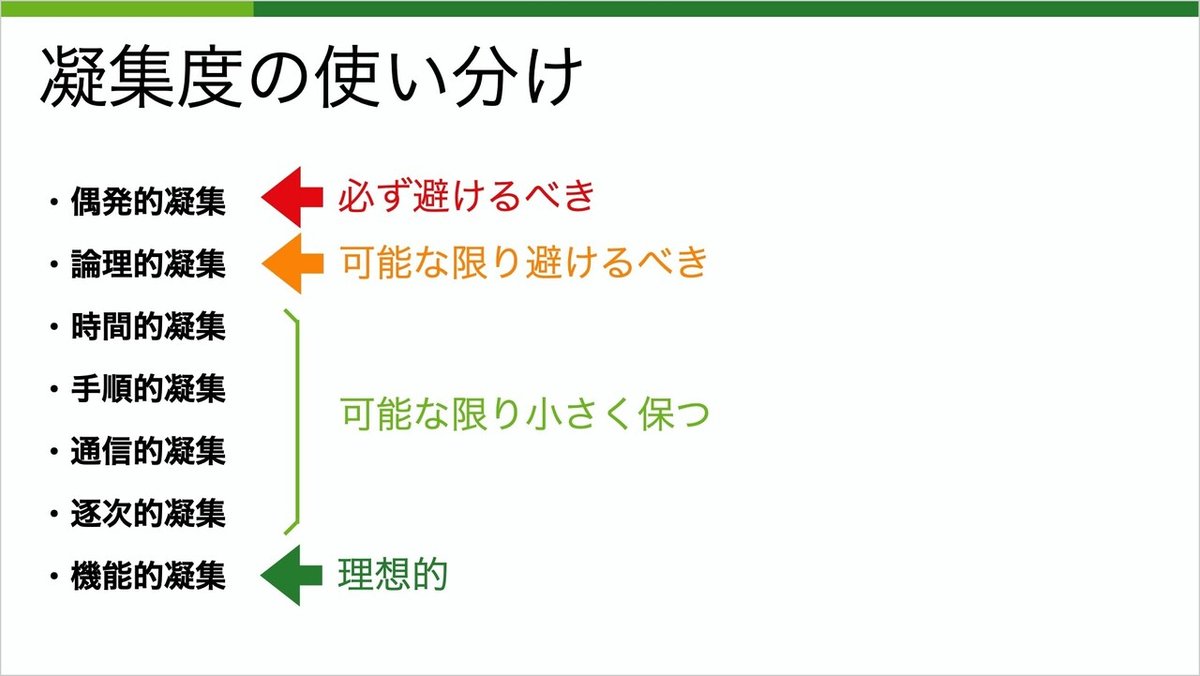
ここでは、凝集度という一つの指標を紹介したいと思います。あくまで、一つの指標であり、全てではないことに注意してください。
凝集度はパッケージ、クラス、メソッドなど様々な粒度のモジュールに対して考えることが出来ます。ここでは、小さい粒度のメソッドで説明を進めていきます。
全部で7つのレベルがあり、それぞれ高い低い、良い悪いが決まっています。凝集度が高いモジュールは、堅牢性、信頼性、再利用性、可読性などの点で良いとされています。SOLIDの中の単一責任の原則と似たような考え方でもあります。
順番に説明をしていきます。

まず最初に紹介するのは、一番悪い偶発的凝集です。適当に集められたものがモジュールになってるもので、「なんかわからんがとりあえず動く」みたいなものがこれに当たります。サンプルコードを作るのが一番難しかったです(笑)

2つ目は論理的凝集です。こちらは論理的に似たものを集めたモジュールで、例えばフラグを渡すことで動作を変えるものがこれに当たります。共通化という名目でよくやってしまいがちな記述ですが、保守性が低く、好ましくないとされています。

3つ目、時間的凝集です。時間的に近くに動作するものを集めたモジュールです。中身の実行順序を入れ替えても動作するという特徴があります。例えば初期化の処理やUIフォアグラウンド時等の処理は時間的凝集になります。
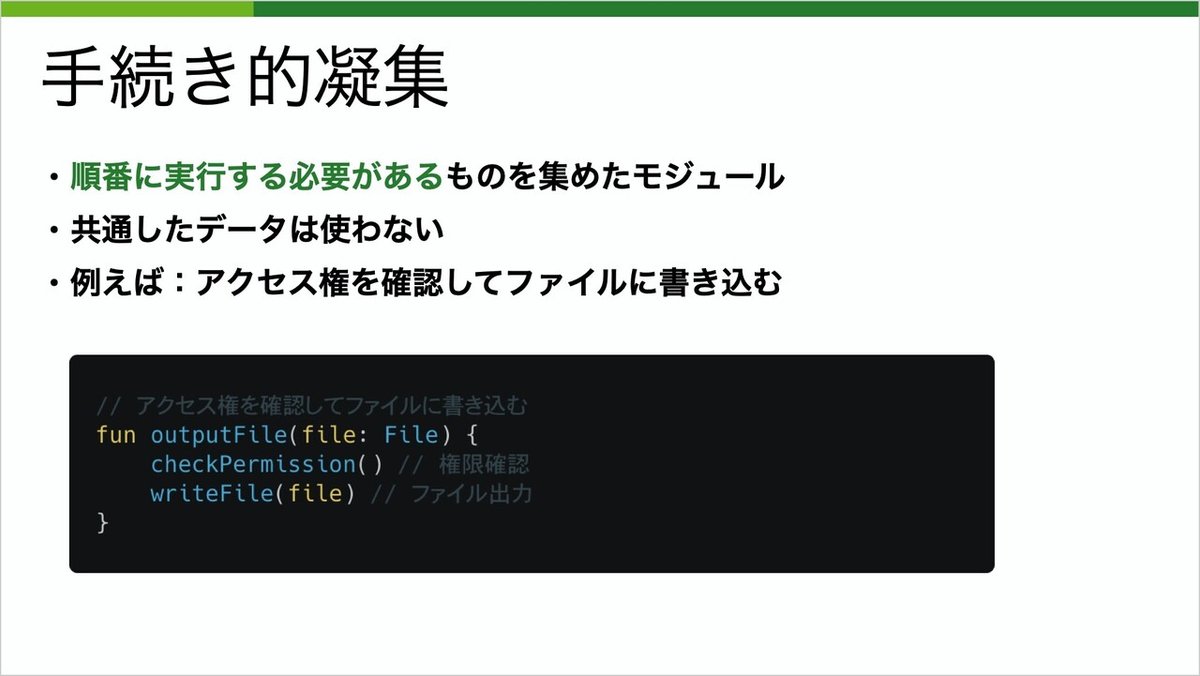
4つ目は手続き的凝集です。先程の時間的凝集とは異なり、順番に意味があります。例えば、ファイルのアクセス権を確認してファイルに書き込む、といった操作がこれになります。

5つ目は通信的凝集です。こちらは同じデータを扱う部分を集めたモジュールです。ここでは、順番は重要ではありません。
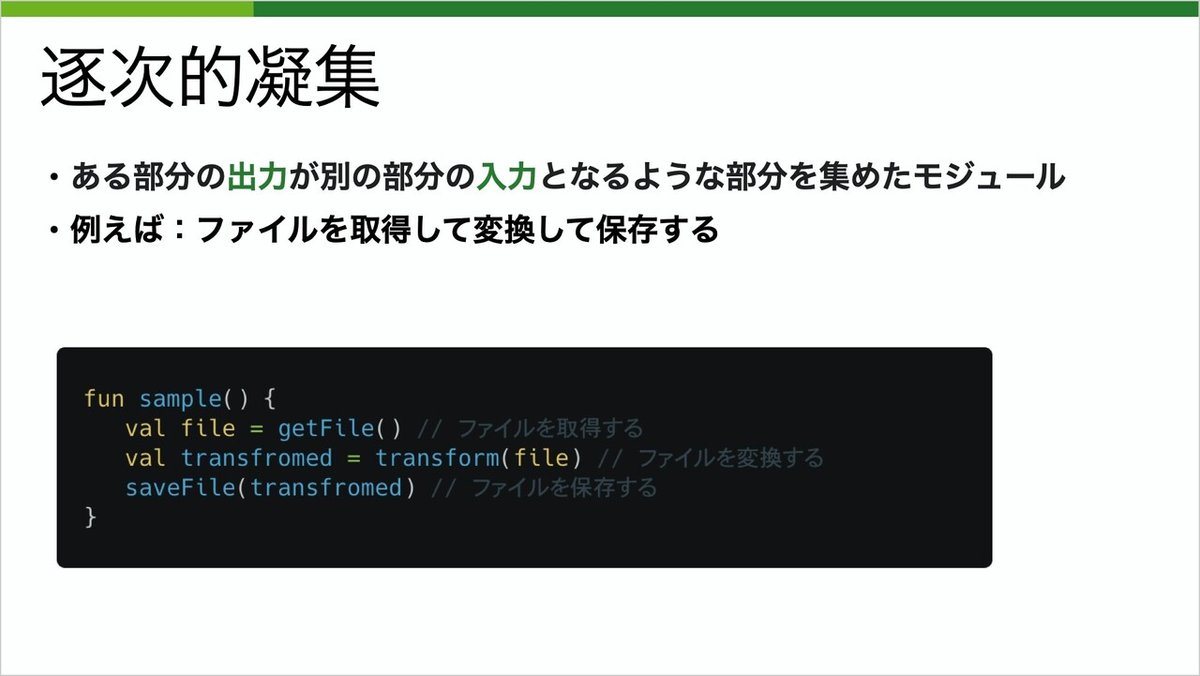
6つ目は逐次的凝集です。ある部分の出力が、次の入力となるような部分を集めたモジュールです。例えば、ファイルを取得し、変換して保存する等がこれに当たります。

最後は機能的凝集です。これは少し理解が難しいかもしれませんが、単一の定義されたタスクを実現するモジュールで、一番良いとされています。例えば、2点間の距離を計算するモジュールは、これ以上意味のある部分に分解することが出来ないので、機能的凝集となります。
7つの凝集度をざっと説明してきました。
機能的凝集が一番良いとは説明しましたが、全てを機能的凝集で書き表すことは出来ません。どうやってこの指標を使うかというと、凝集度が低いモジュールをできるだけ小さく保つようにしていきます。また、偶発的凝集は必ず避け、論理的凝集も可能な限り避けるべきでしょう。
具体的なコードを見ながら説明していきます。

例えば、このようなアプリ初期化時に行う処理があったとします。設定ファイルを見に行ったり、UIを描画したりと、一目見てこのコードを良くないと言い切ることができるでしょう。
一方で、みなさんは凝集度を勉強しましたので、このコードを単に良くないコードではなく、時間的凝集のされている良くないコードであると表現できるようになりました。少し賢くなった気がしますね。
ちなみに、内部で逐次的な処理等は見られますが、凝集度はモジュール内の一番低いレベルで評価するため、この関数は時間的凝集とされます。

それではリファクタしていきましょう。例えばこのように、逐次的凝集や手続き的凝集の関数に分けることで、時間的凝集の箇所を小さくすることが出来ます。ルートの関数は2行になり、先程よりは格段に読みやすくなったのではないでしょうか。
ここでは説明のため関数で分けていますが、UIとロジック等は本来クラスやパッケージなど、より大きいモジュールで分けるべきだと思います。

次のサンプルです。こちらは、購入または以前購入したものを復元する、という処理で、レシートを送る処理が同じため、一つの関数にしてしまいました。
一見良さそうにも見えますが、こういったフラグで制御する関数は論理的凝集と呼ばれ、良くありません。機能追加や変更があった際に、条件が増えたり複雑になる可能性があります。
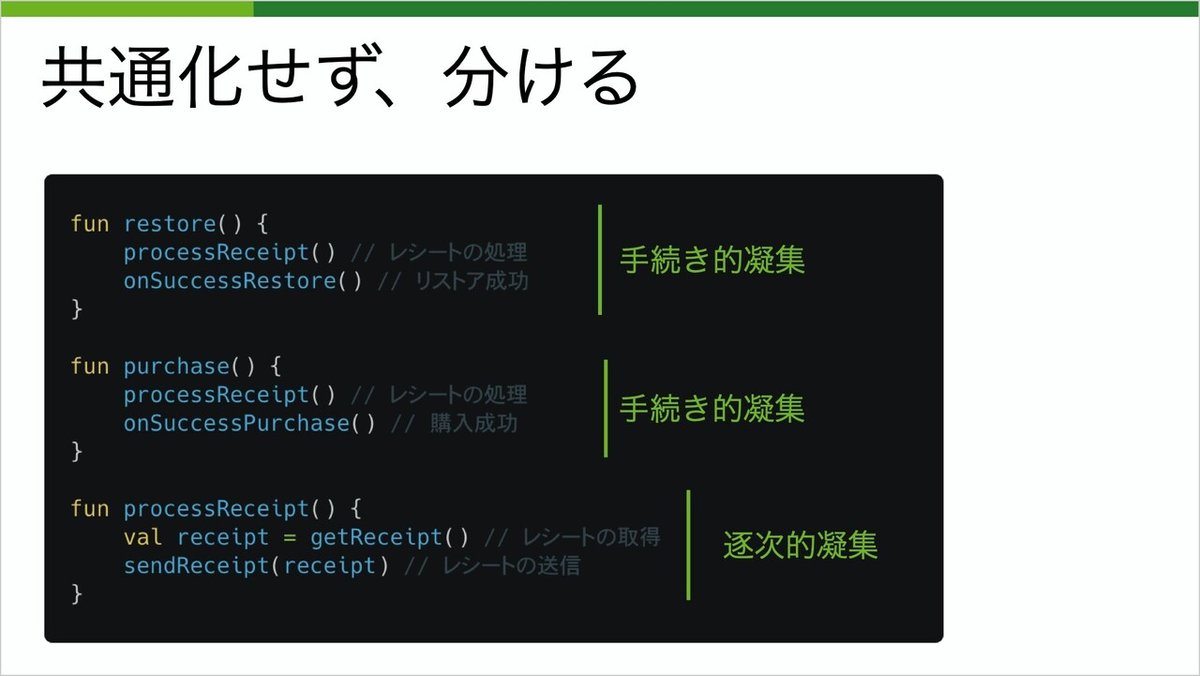
こういったものは、共通化せず、分けることが重要です。同じ操作の箇所はそこを関数化することで、重複した処理を書かずに済みます。全体的に凝集度が上がりましたね。

ここで1点注意してほしいのは、とにかく関数を分ければ良い、というものではありません。関数に分けることで、確かに凝集度を高めることは出来ますが、同時に認知負荷が多少なりとも上昇します。意味のわかる単位で区切ることが重要です。
先程の例も、関数でくくらず一部ベタ書きしたほうが読みやすい可能性があります。
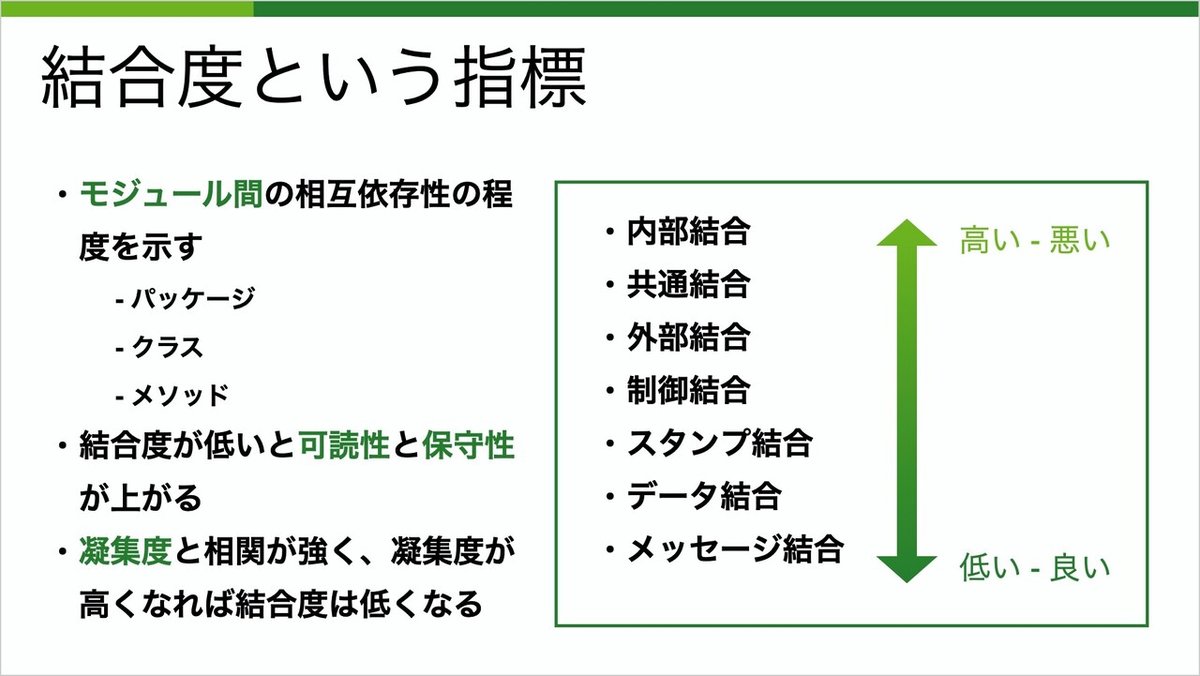
凝集度と一緒に語られることが多い、結合度という指標についても紹介します。
凝集度がモジュール内の評価に使われるのに対し、結合度はモジュール間の相互依存性の程度を示します。同じくパッケージ、クラス、メソッド等で評価可能ですが、再びメソッドで説明を進めていきます。
こちらも7つのレベルがあり、結合度が低いと可読性や保守性が高く、良いとされます。凝集度と相関が強く、凝集度が高くなれば、結合度は低くなる傾向があります。
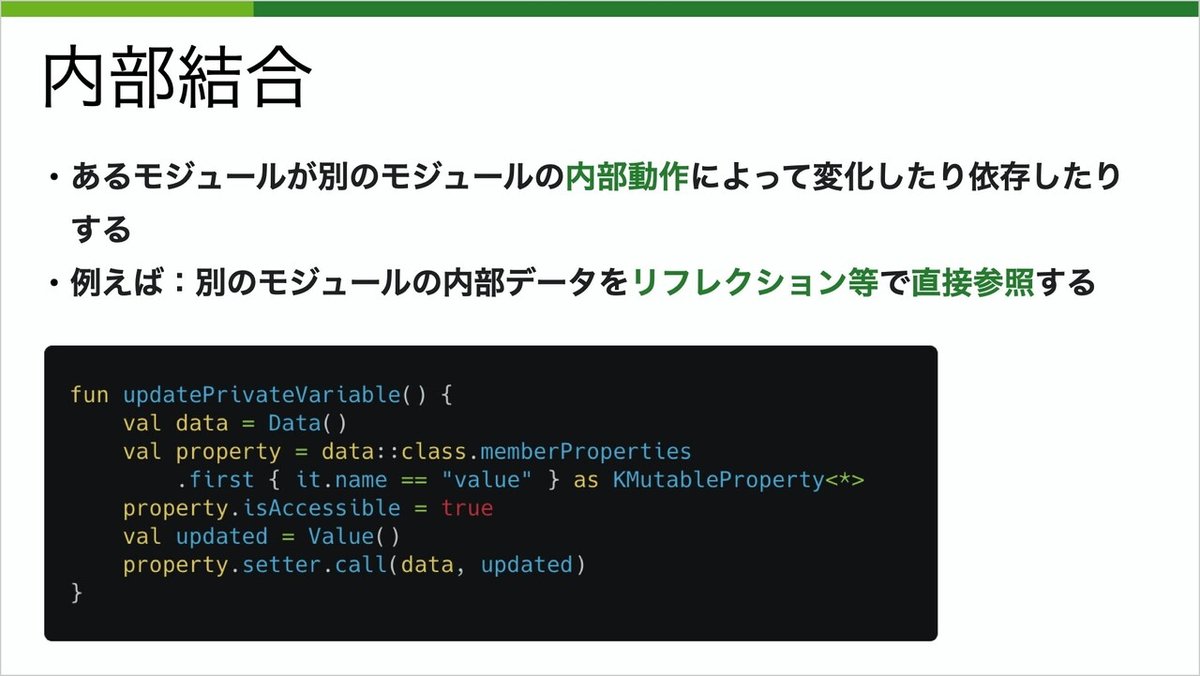
1つ目に紹介するのは内部結合です。リフレクションやC言語でいうポインタ等で、公に宣言されていない内部データを直接書き換えます。
モダンな言語ではあまりできなくなっていますね。私もKotlinのリフレクションを初めて調べました(笑)
当然ですが、一番良くない結合の仕方です。

2つ目の共通結合は複数のモジュールが同じグローバルデータにアクセスできる状態のことを指します。あるモジュールで変更を加えると、他のモジュールで予期せぬ動作をする可能性があります。

3つ目は外部結合です。先程のグローバルデータへのアクセスが、標準化されたインターフェースによって制御された状態です。例えば、外部ツールや外部デバイスへの通信はこのような結合になるでしょう。
この結合度は文献により解釈が一部異なることをご了承ください。

4つ目に紹介するのは制御結合です。あるモジュールに何をすべきかの情報を渡すことで、別のモジュール処理の流れを制御します。凝集度で説明した、論理的凝集ですね。結合度の観点でも、こういった記述は良くないとされています。

5つ目はスタンプ結合です。メソッドの引数等で構造体やクラス等の受け渡しがあります。普通の処理に見えますが、不必要にデータを渡す可能性があり、比較的結合度は高いです。

6つ目はデータ結合です。こちらは数字や文字列等、プリミティブ型と呼ばれる単純な引数でやり取りします。必要最小限のデータを渡すことが出来るため、スタンプ結合よりは結合度が低くなります。

最後はメッセージ結合です。引数のないやりとりで、タイミングのみ等を伝えます。一番結合度としては低いです。
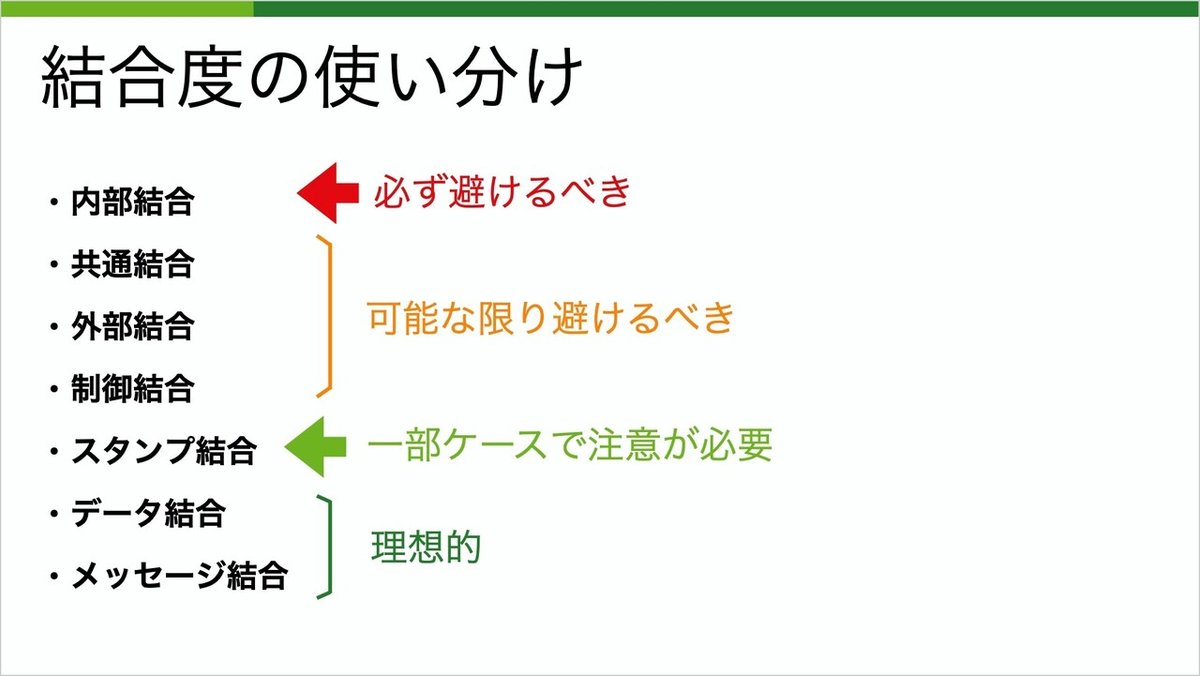
凝集度が機能的凝集のみで完結しないことと同様に、一番結合度が低いメッセージ結合だけでプログラムを構成することは出来ません。内部結合は避け、結合度が高いモジュールはできるだけ小さく分離させるようにしましょう。
![]()
Clean Architecture

最後のセクションでは、Clean Architectureの考え方について軽く触れます。
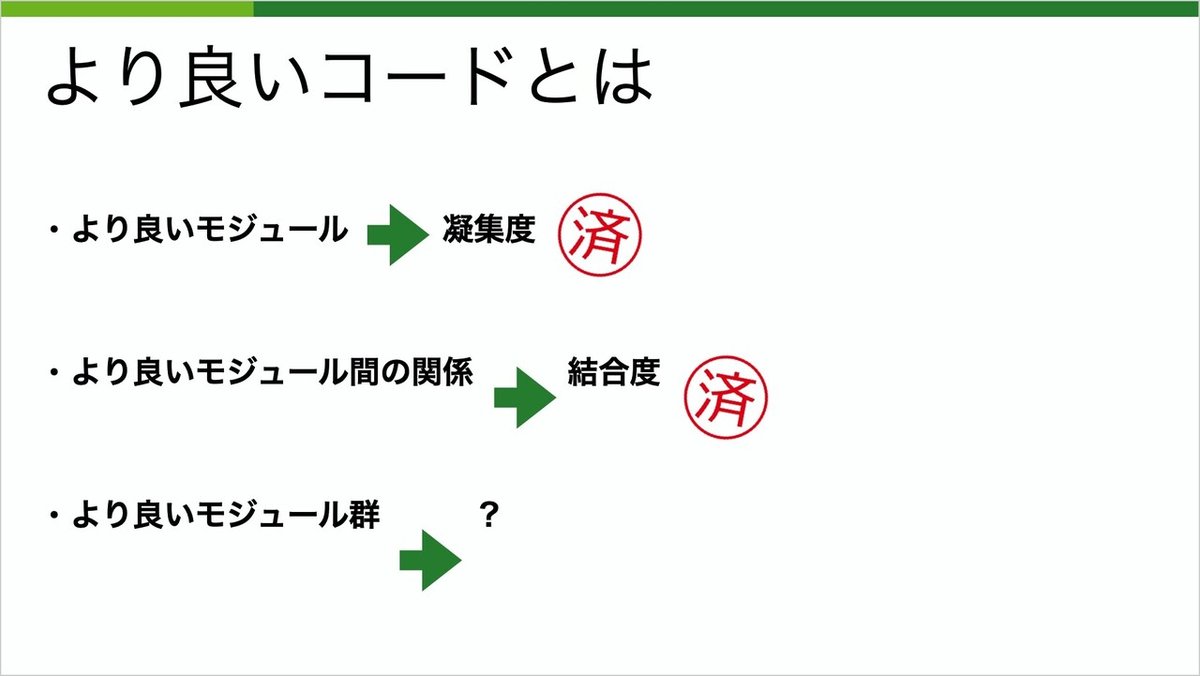
より良いモジュールは凝集度、より良いモジュール間の関係は結合度で評価できることを説明しました。
では、アプリケーション全体のより良い状態とはどのような状態でしょうか?
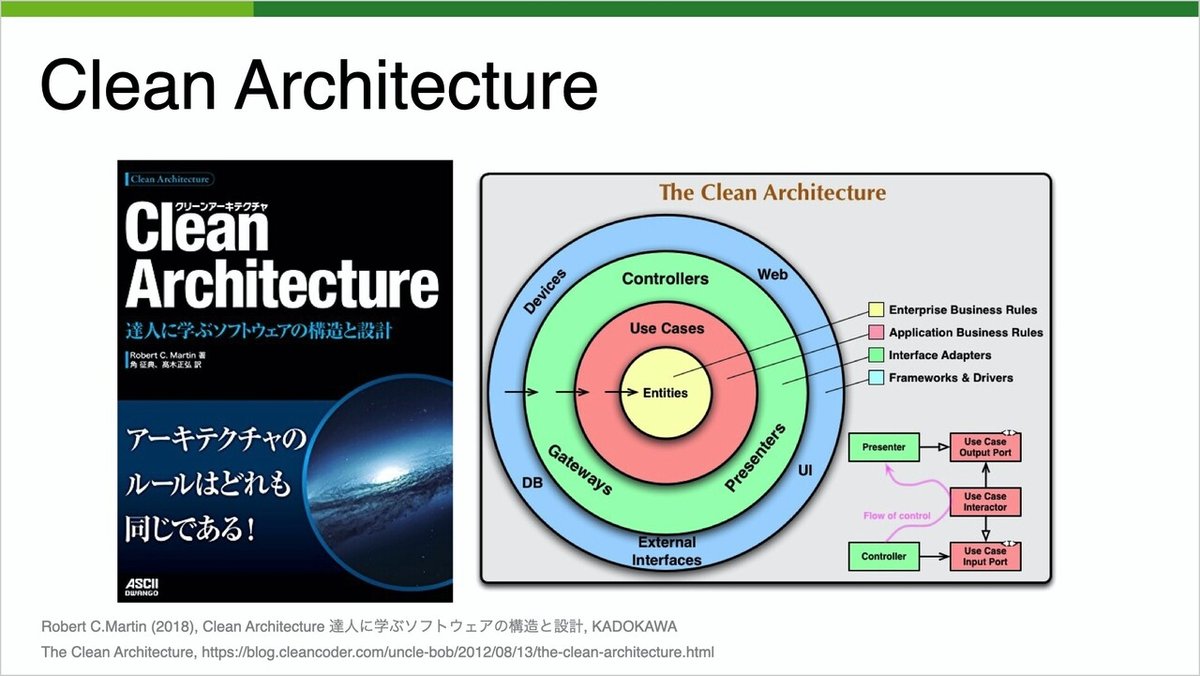
ここでは、Clean Architectureの考え方について紹介します。名前を聞いたり、この同心円の図を見たことがある人も多いと思います。
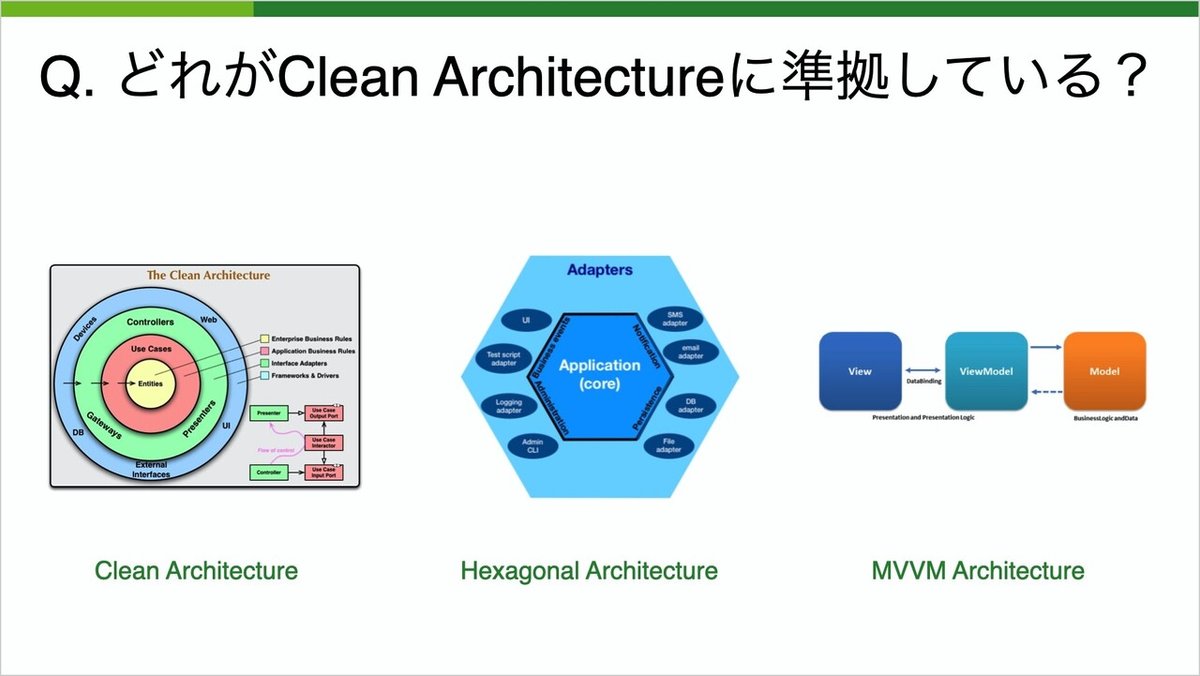
では、そのような人に質問です。ここにいくつかのアーキテクチャは、一体どれがClean Architectureに準拠してると言えるでしょうか?
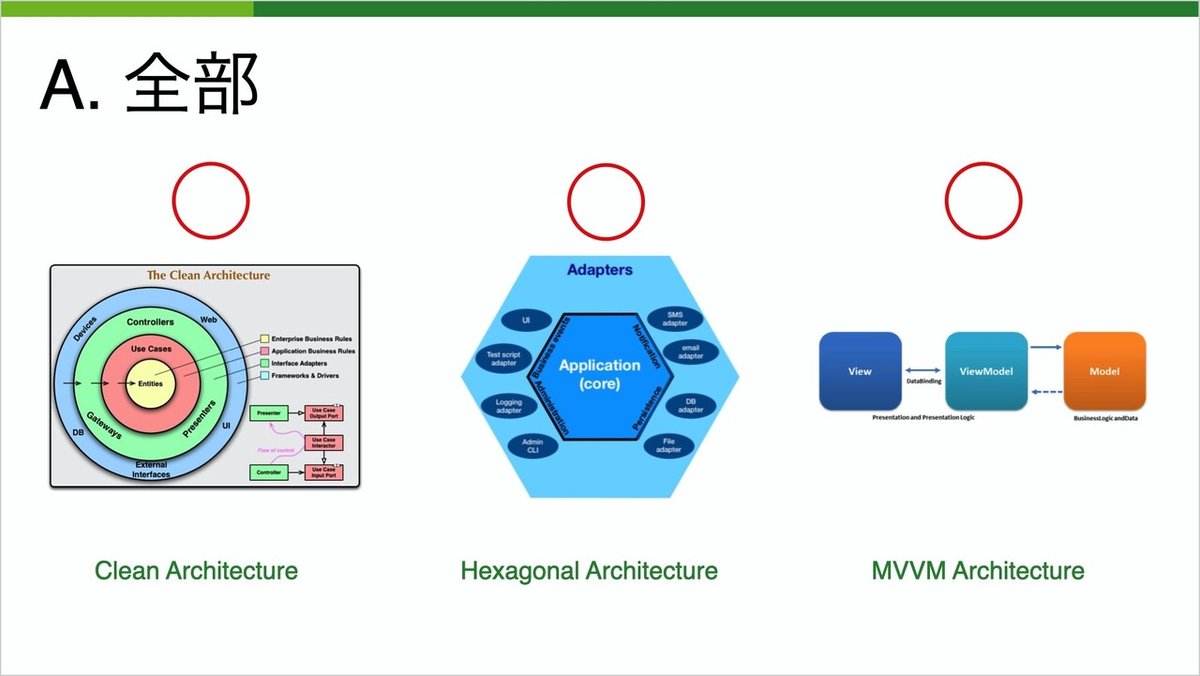
正解は全部となります。MVVMは若干実装方法によっては適合しないことがありますが、基本的な考え方はClean Architectureそのものです。

良く見られる4つの同心円はあくまで例です。Clean Architectureで主張されているのは、この2つのルールだけになります。1つ目は、レイヤーに分離し、関心事の分離を行う。2つ目は、それらの依存性は内側だけに向かっていなければ行けないということです。これらが守られているアーキテクチャが、クリーンなアーキテクチャとされています。

ここで言われる内側/外側とはどのようなことでしょうか?
外側はUIやデータベース、外部システムやフレームワークなどがそれにあたります。内側はビジネスロジックやエンティティ等です。内側に近づくにつれ、ソフトウェアは抽象化され、一般的なものになる必要があります。

これらのルールを守ることで、外側であるフレームワークやUI、データベースに依存しなくなり、テスタブルになります。高い保守性を実現できるわけです。

境界線を超える際は、内側から外側へ依存しないよう細心の注意を払う必要があります。
外側から内側へのアクセスは常に可能です。このように、メソッドを直接呼び出して問題ありません。

問題になるのは、内側から外側に情報を伝えたい場合でしょう。
一つの方法は、RxやFlow等のストリームを使って、内側から外側にイベントを流す方法でしょう。MVVMのDataBindingもこれに当たります。この場合であっても、依存の方向は外側から内側のみになっています。
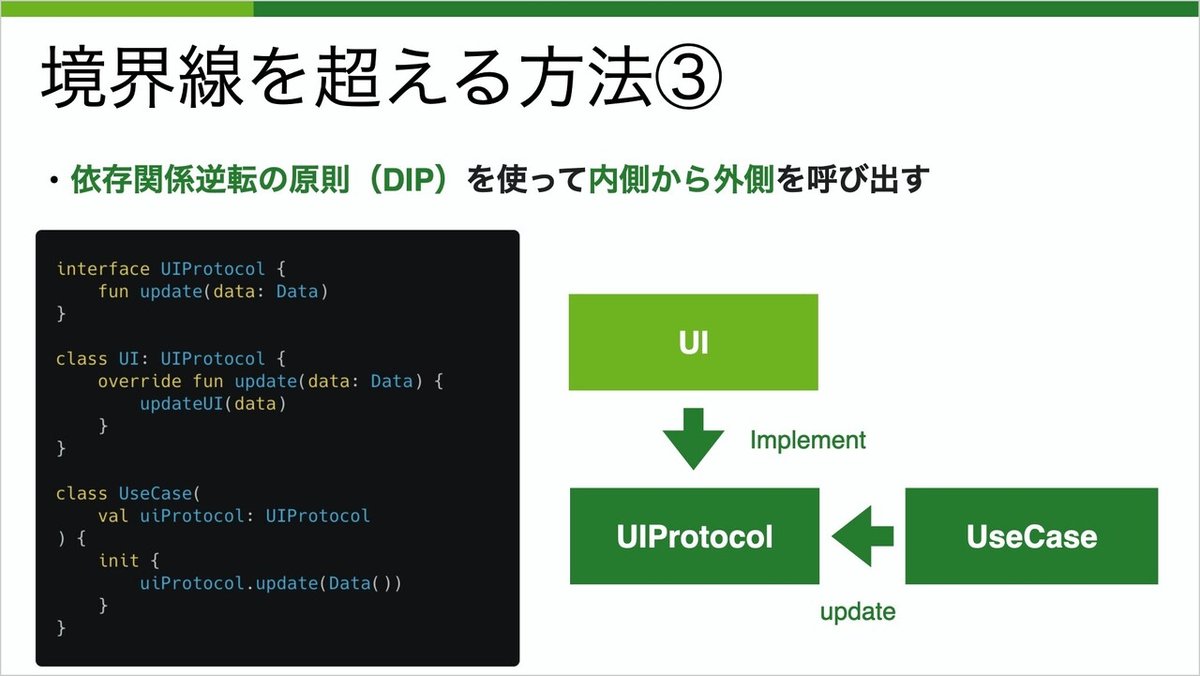
もう一つは、依存関係逆転の法則を使う方法です。
外側であるUIを抽象化したUIProtocolといったインターフェースを用意します。内側からは、そのインターフェースに対して操作を行います。これにより、依存の方向は外側から内側に限定することが出来ます。

境界線を超えるデータに関してもいくつか注意事項があります。
1つ目は単純なデータ構造のほうが好ましいということです。レイヤー間の結合度は低くするという話です。
2つ目は、内側が外側について知るようなデータを渡してはいけません。先程のUIProtocolも、UseCaseレイヤーの知識のみで作成する必要があります。
![]()
まとめ

長々とお話をしてきましたが、まとめになります。
品質とスピードはトレードオフではなく、品質を上げるためには知識/経験が必要であることを説明しました。それらの知識の一例として、凝集度/結合度/Clean Architectureの思想について紹介しました。

公開紹介したもの以外にも、品質を向上させるための知識はたくさんあります。様々な考え方を学ぶことで、より良いコードが書け、各々の開発体験を向上させるでしょう。
最後になりましたが、今回の話を全て聞いたことがあったという人もいれば、あまりピンと来ていない人もいるかも知れません。
学習と経験を繰り返すことで、初めて身についたスキルになります。ぜひたくさん手を動かし、そして繰り返しこの資料やこの後挙げる参考文献を読み返してみてください。
数年後、より深い理解に到達することを期待しています。
![]()
参考文献

・質とスピード(2020秋100分拡大版) / Quality and Speed 2020 Autumn Edition, https://speakerdeck.com/twada/quality-and-speed-2020-autumn-edition
・Robert C.Martin (2018), Clean Architecture 達人に学ぶソフトウェアの構造と設計, KADOKAWA
・オブジェクト指向のその前に-凝集度と結合度/Coheision-Coupling, https://speakerdeck.com/sonatard/coheision-coupling
・【翻訳】技術的負債という概念の生みの親 Ward Cunningham 自身による説明 - t-wadaのブログ, https://t-wada.hatenablog.jp/entry/ward-explains-debt-metaphor
・The Clean Architecture, https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html
・世界一わかりやすいClean Architecture, https://www.slideshare.net/AtsushiNakamura4/clean-architecture-release
・Code readability, https://speakerdeck.com/munetoshi/code-readability
![]()
サイバーエージェントでは、私を含めた20代のエンジニア・クリエータが中心となって創る技術カンファレンス「CA BASE NEXT」を開催します。
若手とは思えない、身の詰まった登壇/コンテンツを誠意用意中です。
開催日時: 2021年5月28日(金) 13:45~19:00
参加費: 無料
開催形式: オンライン(YouTube Live)