
LLMを構成する要素技術と活用方法のマインドマップ

大規模言語モデル(LLM)は、自然言語処理(NLP)の分野で革新的な技術として注目されています。これらのモデルは、膨大なテキストデータを学習し、人間の言語を理解・生成する能力を持っています。例えば、OpenAIが開発したGPT-3は、1750億個のパラメータを持ち、多様なタスクに高い精度で対応できることで知られています(GPT-4はパラメータ数を公表していませんが、数兆パラメータと言われています)。
LLMの構築には、トークナイゼーションや埋め込み、トランスフォーマーアーキテクチャなどの高度な技術が組み合わされています。これらの技術により、モデルは文脈を深く理解し、自然な言語生成が可能となります。例えば、トランスフォーマーアーキテクチャは、自己注意機構を活用して、文中の単語間の関係性を効果的に捉えることができます。
LLMの活用方法は多岐にわたり、テキスト生成、翻訳、要約、質問応答、感情分析など、さまざまな分野で応用されています。例えば、ChatGPTはユーザーとの自然な対話を実現し、カスタマーサポートや教育分野での利用が進んでいます。また、翻訳ツールでは、LLMの高度な言語理解能力により、より自然で文脈に合った翻訳が可能となっています。
これらの情報をマインドマップ形式で整理することで、LLMの構成要素と活用方法を視覚的に理解しやすくなります。以下に、LLMの要素技術と活用方法をマインドマップ形式でまとめました。
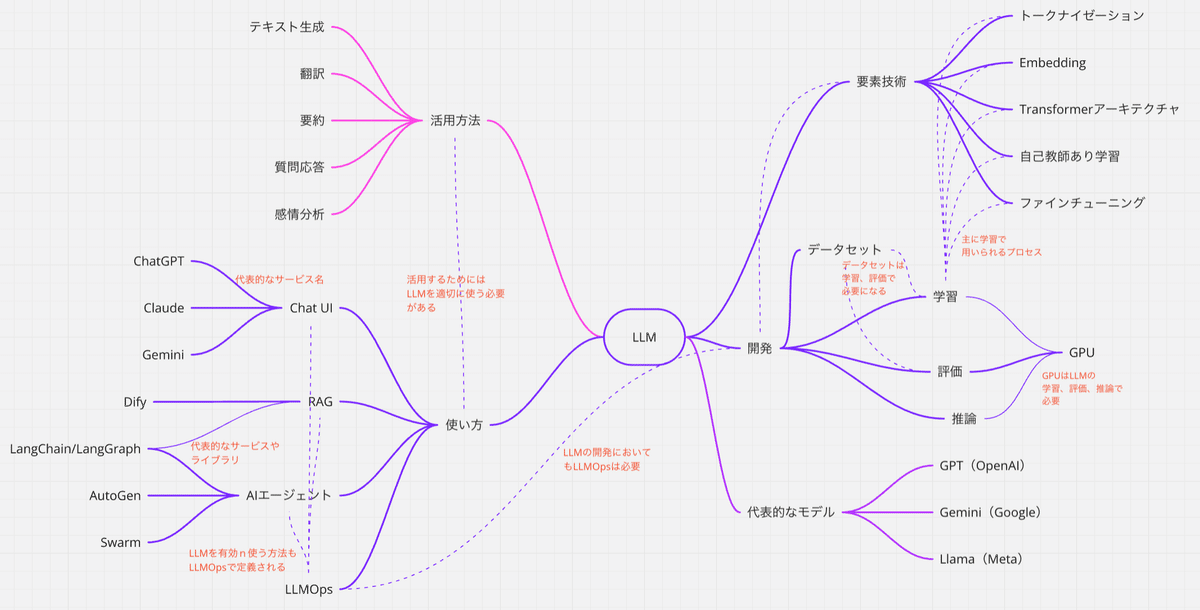
LLMを構成する要素技術
大規模言語モデル(LLM)の開発には、以下の主要な技術が組み合わされています:
トークナイゼーション(Tokenization):文章を単語やサブワードなどの単位に分割する処理です。これにより、モデルはテキストを数値データとして扱えるようになります。特に日本語のように単語間にスペースがない言語では、形態素解析やSentencePieceなどの手法が用いられます。トークナイゼーションは、自然言語処理(NLP)において、テキストデータをモデルが理解・処理できる形式に変換するための重要な前処理ステップです。具体的には、以下の理由から必要とされています:
テキストの構造化:自然言語は連続した文字列で構成されており、そのままではモデルが意味を解釈することが困難です。トークナイゼーションにより、文章を単語やサブワード、文字などの単位(トークン)に分割することで、テキストの構造を明確化し、モデルが各要素を個別に学習・解析できるようになります。
数値データへの変換:モデルは数値データを入力として処理します。トークナイゼーションを行うことで、各トークンに固有のインデックスやベクトルを割り当て、テキスト情報を数値形式に変換します。これにより、モデルはテキストデータを効果的に処理・学習できます。
語彙の管理と未知語への対応:トークナイゼーションは、モデルが扱う語彙(ボキャブラリー)を定義する役割も担います。特に、未知の単語や新語に対しては、サブワード単位での分割を行うことで、未知語を既知のトークンの組み合わせとして表現し、モデルの柔軟性と適応性を向上させます。
言語特性への対応:言語によって単語の区切り方や文字体系が異なります。例えば、日本語や中国語では単語間にスペースがなく、単語の境界を特定するのが難しいため、形態素解析やサブワード分割などの手法が必要です。適切なトークナイゼーションにより、各言語の特性に合わせた効果的なテキスト処理が可能となります。
埋め込み(Embedding):トークン化された単語を高次元のベクトル(数値の集合)に変換します。これにより、単語間の意味的な関係性を数値的に表現できます。例えば、「王」と「女王」のベクトルの差異が「男」と「女」のベクトルの差異に近いなど、意味的な類似性や関係性をモデルが学習できます。Embeddingは、自然言語処理(NLP)において、テキストデータを数値ベクトルに変換する重要な技術です。これにより、コンピュータは言語の意味や文脈を数値的に理解し、処理できるようになります。以下に、Embeddingが必要とされる具体的な理由を詳しく説明します。
意味的関連性の表現:Embeddingは、単語やフレーズを高次元のベクトル空間にマッピングし、意味が類似する単語同士を近い位置に配置します。例えば、「猫」と「犬」はペットとしての共通点が多いため、ベクトル空間上で近接します。これにより、モデルは単語間の意味的な関連性を数値的に捉えることができます。
次元削減と計算効率の向上:従来のワンホットエンコーディングでは、語彙数に応じて非常に高次元なベクトルが生成され、計算資源を大量に消費します。一方、Embeddingは低次元のベクトルで単語を表現するため、計算効率が向上し、モデルの学習や推論が高速化されます。
文脈情報の保持:高度なEmbedding手法(例:BERT)は、単語の前後の文脈を考慮してベクトルを生成します。これにより、同じ単語でも文脈に応じて異なる意味を持つ場合、その違いを適切に表現できます。例えば、「銀行」という単語が「川の銀行」と「金融機関の銀行」で異なるベクトルとして表現されます。
非構造データの処理:テキストデータは非構造データであり、そのままでは機械学習モデルで直接扱うことが困難です。Embeddingを用いることで、テキストを数値ベクトルに変換し、モデルが処理可能な形式に整形します。これにより、分類やクラスタリングなどのタスクに適用できるようになります。
多言語対応:Embeddingは、異なる言語間での単語の意味的な類似性を捉えることができます。例えば、英語の「apple」と日本語の「りんご」を同じベクトル空間上で近接させることで、多言語翻訳やクロスリンガルな情報検索に応用できます。
トランスフォーマー(Transformer)アーキテクチャ:LLMの基盤となるモデル構造で、自己注意機構(Self-Attention Mechanism)を用いて文脈を考慮した言語理解を可能にします。これにより、長い文脈の依存関係も効率的に捉えることができ、従来のRNNやLSTMに比べて並列処理が容易で、高速な学習と推論が可能となります。Transformerアーキテクチャは、自然言語処理(NLP)や機械学習の分野で革新的な技術として注目されています。その必要性は、従来のモデルが抱えていた課題を解決する点にあります。
長期依存関係の効果的な学習:従来のリカレントニューラルネットワーク(RNN)や長短期記憶(LSTM)モデルは、シーケンシャルなデータ処理を行うため、長い文脈内での単語間の依存関係を捉えるのが難しいという課題がありました。これに対し、Transformerは自己注意機構(Self-Attention Mechanism)を活用し、文中の全ての単語間の関係性を同時に評価することが可能です。これにより、長距離の依存関係も効果的に学習でき、文脈理解の精度が向上します。
並列処理による高速化:RNNやLSTMは逐次的にデータを処理するため、並列処理が困難であり、学習や推論の速度に制約がありました。一方、Transformerは全ての単語を同時に処理できるため、GPUなどのハードウェアを活用した並列計算が可能です。これにより、大規模データセットでの学習が高速化され、モデルの訓練時間が大幅に短縮されます。
モデルのスケーラビリティ:Transformerは、その構造上、層の深さやモデルのサイズを柔軟に拡張できます。これにより、より大規模なモデル(例:GPT-3など)を構築し、高度なタスクにも対応可能となります。また、エンコーダーとデコーダーの組み合わせにより、さまざまなタスクに適したモデル設計が可能です。
多様なタスクへの適用性:Transformerは、機械翻訳、要約、質問応答、テキスト生成など、多岐にわたるNLPタスクに適用されています。さらに、画像認識や音声処理など、NLP以外の分野にも応用が広がっており、汎用性の高いアーキテクチャとして評価されています。
自己教師あり学習(Self-Supervised Learning):ラベル付けされていない大量のデータからパターンを学習する手法です。例えば、文章の一部を隠してその部分を予測させるマスクドランゲージモデル(Masked Language Model)などがあります。これにより、モデルは人手によるラベル付けなしで高い性能を発揮できます。自己教師あり学習は、ラベル付けされていないデータから有用な特徴やパターンを学習する手法であり、特に以下の理由から重要視されています:
ラベル付けコストの削減:従来の教師あり学習では、大量のラベル付きデータが必要ですが、これらのラベル付けには専門知識や時間が求められ、コストがかかります。自己教師あり学習は、データ自体の構造を利用して学習を行うため、手動のラベル付け作業を大幅に削減できます。
大量の未ラベルデータの活用:インターネット上や企業内には、ラベル付けされていないデータが膨大に存在します。自己教師あり学習は、これらの未ラベルデータを効果的に活用し、モデルの性能向上に寄与します。
特徴表現の学習:自己教師あり学習は、データの内在する構造やパターンを捉えることで、高品質な特徴表現を学習します。これにより、分類や回帰などの下流タスクにおいて、モデルの精度向上が期待できます。
新たなタスクへの適応:自己教師あり学習で事前学習されたモデルは、転移学習を通じて、新たなタスクやドメインへの迅速な適応が可能です。これにより、少ないラベル付きデータでも高性能なモデルを構築できます。
データの多様性への対応:自己教師あり学習は、データの多様な変換や摂動に対しても頑健なモデルを構築することができます。これにより、実世界の複雑なデータにも柔軟に対応できるモデルの開発が可能となります。
ファインチューニング(Fine-Tuning):特定のタスクやドメインに合わせて、事前学習済みのモデルを追加学習させる工程です。例えば、医療分野の専門知識を必要とするタスクには、医療文献を用いてファインチューニングを行います。これにより、モデルの適用範囲を広げ、精度を向上させます。ファインチューニングは、事前学習済みのモデルを特定のタスクやドメインに適応させるための重要な手法です。その必要性は、以下の具体的な理由に基づいています:
特定タスクへの最適化:事前学習済みモデルは一般的なデータで訓練されていますが、特定のタスクやドメインにおける専門的な知識や特徴を十分に捉えていない場合があります。ファインチューニングにより、モデルを特定のタスクに最適化し、精度や性能を向上させることが可能です。
学習時間とリソースの節約:ゼロからモデルを構築・学習させるには膨大なデータと計算資源が必要ですが、事前学習済みモデルを活用することで、これらのコストを大幅に削減できます。ファインチューニングは、既存のモデルの知識を再利用し、効率的に新たなタスクに適応させる手法です。
データ不足への対応:特定のタスクやドメインにおいて、十分な量のラベル付きデータを収集することが難しい場合があります。ファインチューニングは、少量のデータでもモデルを効果的に適応させることができるため、データ不足の状況でも有用です。
モデルの汎用性向上:事前学習済みモデルは一般的な特徴を学習していますが、ファインチューニングを施すことで、特定のタスクに必要な細かな特徴やパターンを学習させることができます。これにより、モデルの汎用性と適応力が向上します。
計算リソースの効率的な利用:ファインチューニングは、全てのモデルパラメータを再学習する必要がないため、計算リソースの節約につながります。特に、計算資源が限られている環境では、効率的なリソース管理が求められます。
これらの技術要素が組み合わさることで、LLMは高度な言語理解と生成能力を持つことができます。
LLMを開発する
大規模言語モデル(LLM)の開発には、以下の主要なプロセスが含まれます:
ここから先は
¥ 300
Amazonギフトカード5,000円分が当たる
この記事が参加している募集
この記事が気に入ったらチップで応援してみませんか?