Kaggleのチュートリアル輪読会1回目の発表内容を公開します。

===
以下の勉強会で発表者をやることになったので、資料をつくっています。発表スライドを作りながら公開していきます。
→【5/15更新】以下の勉強会で発表者をやりました。発表資料の内容を公開します。
もし読んでいて質問があれば、質問箱までどうぞ。すぐに答えます
スライドの目次(案)
・1. 自己紹介
・2. はじめに
・3. 1章 Kaggleについて
・4. 2章 コンペのページの翻訳など
・5. 3章 まずは、サブミットしてみる
・6. 4章 タイタニックデータの概要
・7. pandas-profilingについて

1. 自己紹介

2. はじめに




はじめに、目次
1章 Kaggleについて
2章 コンペのページの翻訳など
・資格で囲んである文章は、Kaggleのページを翻訳した箇所
・2224人の乗客と乗組員のうち1502人が死亡しました。
生存者は722人、死亡者67.5%、生存者32.5%だということがわかる。
・Evaluation (評価) を読んでおくのは重要。
・タイタニックコンペのスコアは、accuracy (精度)。
・Praivate Leaderboard (非公開スコア) とPublic Leaderboard (公開スコア)の違い

・チュートリアル
http://www.currypurin.com/entry/2018/04/17/102140 にリンクがあります。
3章 まずは、サブミットしてみる
・カーネル環境のNotebookでやる方は、3.2のカーネル環境のノートブックを用いる方法
・ローカル環境でやる方は、3.4のろーかるPCで作成したデータをサブミットする方法
を読んで、サブミットしてみましょう。
4章 タイタニックデータの概要
・4章のコード(nbviewer)
http://nbviewer.jupyter.org/github/currypan/tb4-datarefinement/blob/master/tb4_kaggle_book_ch4.ipynb
・4章のコード(kaggle)
https://www.kaggle.com/currypurin/kaggle-ch4/code
4.1 ライブラリのインポートとデータの読み込み
4.2 データの概要を確認する
4.2.1 データフレームについて
4.2.2 データフレームの行数と列数を確認
print(df_train.shape) # 学習用データ
print(df_test.shape) # 本番予測用データ
print(df_gender_submission.shape) # 提出データのサンプル・ df_train : 891行×12列
・ df_test : 418行×11列
・ df_gender_submission : 418行×2列
・学習データであるdf_trainには、891人分のデータが含まれる
・本番予測用のデータであるdf_testには、418人分のデータが含まれる
・学習用データにより学習したモデルで、本番予測用のデータの生存予測をする。df_testは1列少なくなっている。
・参考 → https://qiita.com/terapyon/items/8f8d3518ee8eeb4f96b2
4.2.3 列の名前の確認
print(df_train.columns) # トレーニングデータの列名
print('-'*10) # 区切りを挿入
print(df_test.columns) # テストデータの列名df_testには、Suvived列がない。 (当然)
4.2.4 df.info()で概要の確認
df_train.info()float型が2つ、int型が5つ、object型が5つであることがわかる
df_test.info()df_testはint型が1つ少ない
4.2.5 df.head()で概要の確認
df_train.head()・Embarkedには1文字の大文字のアルファベットが入っていること、
・Nameには、Mr、Mrs、Missという敬称が含まれること、
・Ticketには、アルファベットや数字が含まれそうなこと
などがわかる (正確にはこの5つのデータから全体を予測)
4.2.6 欠損値がいくつあるか確認
df_train.isnull().sum() 欠損値の数は、多い順にCabinが687、Ageが177、Embarkedが2、であることがわかります。
df_test.isnull().sum()df_testの欠損値は、Cabinが327、Ageが86、Fareが1であることがわかります。
4.2.7 要約統計量の表示
df_train.describe()により、数値データのみの、データ数、平均値、標準偏差、最小値、最大値、四分位数 (データを大きさ順に並べた時に25%、50%、75%の位置にくる値)が表示されます。
df_trainとdf_testをpd.concat()により縦に連結し、df_fullを作成してから、要約統計量を表示してみます。
# df_trainとdf_Testを縦に連結
df_full = pd.concat([df_train, df_test], axis = 0, ignore_index=True)
print(df_full.shape) # df_fullの行数と列数を確認
df_full.describe() # df_fullの要約統計量df.describe(include = 'all')と書くと全てのデータについての要約統計量を表示することができます。
df_full.describe(include = 'all')df.describe(include=['O'])と書くと、オブジェクト型のみを表示できる。
train_df.describe(include=['O'])df.describe(percentiles=[.1, .2, .3, .4, .5, .6, .7, .8, .9, .99])と書いて、表示するパーセンタイルを指定可能。(このようにかくと、10%刻みと99%の値が表示される。
df_train.describe(percentiles=[.1, .2, .3, .4, .5, .6, .7, .8, .9, .99])4.2.8 死亡者と生存者の可視化
sns.countplot(x='Survived', data=df_train)
plt.title('死亡者と生存者の数')
plt.xticks([0,1],['死亡者', '生存者'])
# Survived列の値を集計
df_train['Survived'].value_counts()

# 男女別の生存割合を表示する
df_train[['Sex','Survived']].groupby(['Sex']).mean() Survived Sex
female 0.742038
male 0.188908
男女別の死亡者数と生存者の数
sns.countplot(x='Survived', hue='Sex', data=df_train)
plt.xticks([0.0,1.0], ["死亡","生存"])
plt.title("男女別の死亡者と生存者の数", fontsize = 20)

4.2.9 チケットクラス
# チケットクラス別の生存者数を可視化
sns.countplot(x='Survived', hue='Pclass', data=df_train)
plt.xticks([0.0,1.0], ['死亡','生存'])
# チケットクラス別の生存割合を表示する
df_train[['Pclass','Survived']].groupby(['Pclass']).mean()
# チケットクラス別の生存割合を表示する
df_train[['Pclass','Survived']].groupby(['Pclass']).mean() Survived Pclass
1 0.629630
2 0.472826
3 0.242363
次の4.2.10から、4.2.15については、ここでは説明を省略します。コードについては、公式サイトを参照ください。
4.2.10 年齢の分布
4.2.11 タイタニック号に乗っている兄弟・配偶者の数
4.2.12 タイタニック号に乗っている両親・子供の数
4.2.13 1人で乗船しているか2人以上で乗船しているか
4.2.14 運賃の分布
4.2.15 名前
pandas-profilingについて
上記のqiitaを参考にやってみた。たしかにめちゃくちゃ便利!!
import pandas as pd
import pandas_profiling as pdp
df = pd.read_csv('train.csv')
pdp.ProfileReport(df)これだけ!(google colaboratoryの場合はもう少し必要)
一番上には次のような概要が表示されます。

表示される内容
・Datasetinfo:データ数、欠損値数、データサイズなど
・Variables types:型の情報
・Warnings:欠損値、要素が大きい、ゼロが多いなどの警告
特徴量ごとの情報
すべての特徴量について要素数、ユニーク数、欠損率、平均、min、maxとヒストグラムなとが表示されます。
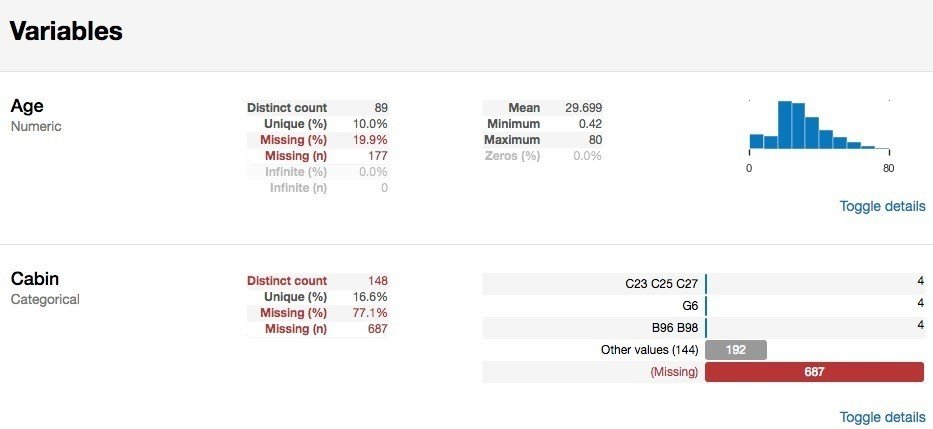
右下にあるtoggle detailsをクリックするとさらに詳細を確認できる。
Statistics

Histogram

Common Values

Extreme Values

コメントお待ちしています。匿名の質問はマシュマロから→https://marshmallow-qa.com/currypurin