
【詳細解説】ローカル版YuEで曲を作る【GUIあり・量子化モデル付き】

しぴぴぴ!
Vtuberのしぴちゃん (https://www.youtube.com/@CP-chan) です。
YouTubeではゲームとか麻雀とかの話しかしてませんが、今回はローカルAI関連の連載企画の第6回です。
これまで、DeepSeek R1などの言語系モデルや、AIコーディングツールのClineなどについて紹介してきました。
今回は音楽を生成するモデルであるYuEについての紹介です。
必要に迫られたので、自分が量子化したモデルも公開しています。
音楽生成モデル YuE
YuE (乐)は2025/1/26に最初のバージョンがgithubに公開された音楽生成のAIです。歌詞を入力して歌を出力する (lyrics2song) の深層学習モデルで、オープンソース (Apache2.0 license) で公開されています。
ボーカルトラックと伴奏トラックを含む最大数分間の楽曲を生成することができるとされており、 デモページが公開されています。
ちなみに、YuEの読み方はユエだそうですが、英語圏などでユエが発音しにくい人はYeahと発音してね…だそうです。
出力はモノラルトラックで、「いい音」「素晴らしい楽曲」とは言いづらい出来ではありますが、歌詞はほとんど入力通りに発音できており、リズムが崩壊していたり大きなノイズが乗っているということもなく「ちゃんと楽曲として聴ける」曲がAI生成で出てくるのは驚くべき進歩です。
また、YuEは既存の楽曲を入力としてそれに近い雰囲気の曲を生成する機能(Audio Prompt) を実装しています。これも興味深い機能です。
せっかく公開されているわけですから、ローカルで動かしてみましょう。
YuEはかなり大きいモデルで、オリジナルのモデルでは長い楽曲の生成には数十分~数時間かかります。そこで別のグループから、exllamav2という推論エンジンを使い、量子化されたモデルで高速に推論を行う方法が公開されています(下記)。
また、2025/1/30、歌詞などをGUIから入力できるようになったバージョンが別のグループから公開されました。これがYuEのリリースから4日程度で出ていることもすごいですね。
今回はこのYuE-exllamav2-UIを利用して、歌詞の入力などをGUIからできるようにします。
これまでの連載と異なる推論エンジンを使うので、Docker経由でインストールを行います。
インストールの推定所要時間は2時間程度(ほとんどモデルのダウンロード時間)、生成は1楽曲あたり10分程度です。
動作環境
括弧内は筆者の環境です。
Windows 11 PC
メインメモリ 16GB以上 (32GB)
GPU RTX 3060 mobile 6GB以上 (RTX 3080 10GB)
ちょっとしたゲーミングPCくらいから動作します。
VRAMは多ければ多いほど長い楽曲の生成ができます。
VRAM 10GBでは1分程度の楽曲まで快適な速度で生成できました。
1. 環境構築
以下の順でインストールします。すでにインストールしている人は項目ごとに飛ばしてください。
1-1. WSLのインストール
WSL (Windows subsystem for Linux)は、Windows コンピューター上で Linux 環境を実行できる機能です。WindowsとLinux間でファイルのやりとりもできます。
今回はUbuntuを利用します。このあたりの記事を参考にして、WSL2のUbuntuをインストールします。
1-2. git, git lfsのインストール
sudo のコマンドを実行する際にはパスワードの入力が必要です。パスワードの文字は表示されませんが入力されています。
sudo apt install git
sudo apt install git-lfs1-3. WSL版CUDAのインストール
以下のページなどを参考にインストールします。
1-4. dockerのインストール
WSLを起動して、
sudo apt install docker
sudo systemctl enable docker
sudo systemctl start docker
sudo usermod -aG docker $USERWSLを再起動し、
docker run hello-worldが成功したらインストールできています。
docker daemonが起動してないと言われる場合は以下を一回実行します。
sudo update-alternatives --set iptables /usr/sbin/iptables-legacy
sudo update-alternatives --set ip6tables /usr/sbin/ip6tables-legacy
sudo service docker restart2. YuE-exllamav2-GUI のインストール
WSLを起動し、適当なディレクトリに行きます。
以下の内容のファイルを docker-compose.yml というファイル名で保存します。
version: '3.8'
services:
yue-exllamav2:
image: alissonpereiraanjos/yue-exllamav2-interface:latest
container_name: yue-exllamav2
restart: unless-stopped
ports:
- "7860:7860"
environment:
- DOWNLOAD_MODELS=all_bf16
volumes:
- /path/to/models:/workspace/models
- /path/to/outputs:/workspace/outputs
deploy:
resources:
reservations:
devices:
- capabilities: [gpu]このファイルのうち、
DOWNLOAD_MODELS=all_bf16
を使いたいモデルに合わせて変更します。他の値はそのままで問題ありません。
デフォルトでは量子化されていないものがダウンロードされるので、量子化後のモデルに変更します。YuEは2ステップのモデルで、1ステップ目は言語やAudio promptの有無によって使うモデルが異なりますが、2ステップ目は共通です。
2025/2/8 現在、exllamav2側の互換性の問題でint8, int4, nf4モデルが動きません。exl2形式なら動くので、
YuE-s1-7B-anneal-en-cot-exl2-5.0bpw と YuE-s2-1B-general-exl2-5.0bpw を一旦ダウンロードします。DOWNLOAD_MODELSは以下になります。
DOWNLOAD_MODELS=YuE-s1-7B-anneal-en-cot-exl2-5.0bpw,YuE-s2-1B-general-exl2-5.0bpw既存の楽曲を参照する機能(Audio Prompt)を使う場合、CoT (chain-of-thought) 版ではなくICL (in-context learning) 版をダウンロードしてください。起動後に選べるので両方ダウンロードしてもよいです。
書き込んだら、.ymlファイルのあるディレクトリで
docker compose up -dでインストールが開始(dockerコンテナが起動)されます。
セットアップに10分くらいかかります。
docker psを実行して、 yue-exllamav2 というコンテナがあれば起動に成功しています。
Ubuntuのシェルを落としても立ち上がったままです。終了する場合、.ymlファイルのあるディレクトリで
docker compose stop yue-exllamav2を実行するとコンテナが終了します。
2回目以降の起動も同じくdocker compose up -dで、初回よりは速いです。
3. 日本語量子化モデルのダウンロード
さて、YuE公式は日本語と韓国語のモデル (jp-kr) を公開してくれていますが、YuE-Exllamav2-UI では正しく動作する日本語と韓国語の量子化モデルを提供してくれていません。(int8やnf4はexllama2側の互換性の問題で動きません。英語版はあるのに…)
そこで、筆者が量子化したものを公開しました。
それぞれCoT版とICL版です。これらをダウンロードして使えるようにします。CoT版のコマンドを記載します。ICL版は適宜cotをiclに置き換えてください。
まず、動いているコンテナ名を調べます。
docker psで、コンテナの一覧を取得します。各行の末尾にコンテナ名があります。
例えば "e50a10112bcc_yue-exllamav2" です。この名前をメモして、
docker exec -it e50a10112bcc_yue-exllamav2 /bin/bashを実行するとコンテナ内のシェルにアクセスできます。コンテナ内で、
cd /workspace/models
git clone https://huggingface.co/cpchan/YuE-s1-7B-anneal-jp-kr-cot-5.0bpwでダウンロードできます。10分程度かかります。
コンテナを再起動しないと反映されないので、再起動します。
docker compose stop yue-exllamav2
docker compose up -d4. ブラウザからアクセス
docker compose up -d を実行後、ブラウザから、localhost:7860 にアクセスします。"接続がリセットされました" などが表示される場合、起動が終わっていません。
初回起動時はモデルのダウンロードも行っているようなので、30分~1時間程度かかります。ごはんでも食べて待ちましょう。
モデルのダウンロードが終わっている2回目以降は5分程度です。
正常に接続できたら下のスクリーンショットのような画面が出てきます。
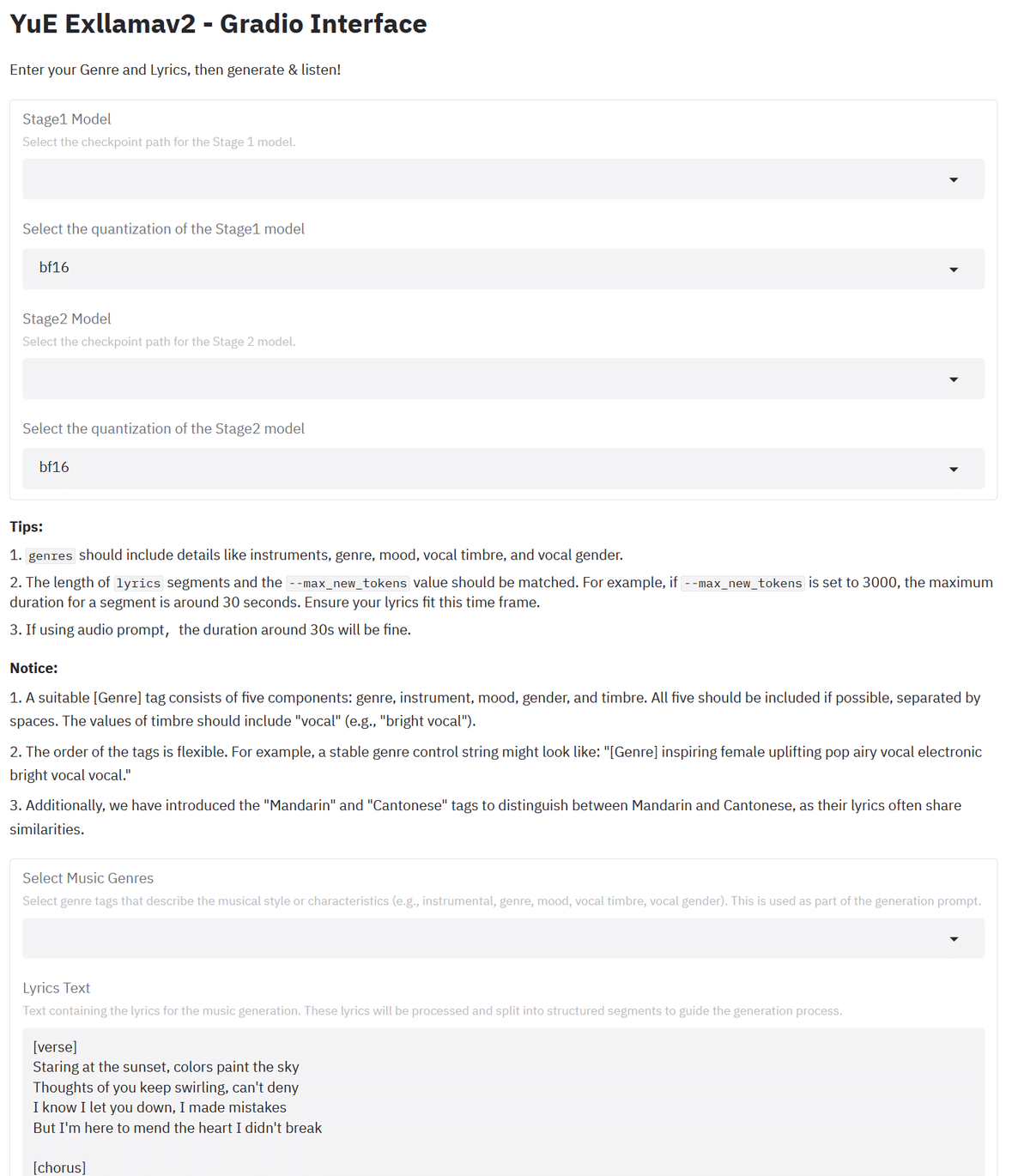
5. 楽曲の生成
全体の流れは以下の通りです。それぞれの詳細を後述します。
Stage1 ModelとStage2 Modelを選択
Select the quantization…で量子化レベルを選択
Select Music Genres に楽曲のジャンルを入力
Lyrics Textに歌詞のテキストを入力
その他数値の設定
Generate Musicボタンで生成開始
今回は、「ねこはかわいい、毎日なでなでしたい」をテーマにした日本語のかわいい歌を作ってみましょう。
5-1. Stage1 ModelとStage2 Modelを選択
ダウンロードしたモデルを選択します。今回は上から順に
/workspace/models/YuE-s1-7B-anneal-jp-kr-cot-5.0bpw
/workspace/models/YuE-s2-1B-general-exl2-5.0bpw
を選びます。Audio promptを利用する場合はICL版のモデルが必要です。
5-2. Select the quantization…で量子化レベルを選択
今回はbf16でそのまま進めます。
5-3. Select Music Genres に楽曲のジャンルを入力
ジャンルといっても、画像生成AIのプロンプトに近いものです。
Genresのテキストエリアをクリックすると候補が出てきます。クリックすると選択されます。また、この候補にないものでも入力できるようです。
Genresの詳しい説明はAppendixにあります。
今回は、
Happy, Electro pop, female, synthesizer, drum machine, bass, optimistic, young vocal
でいきましょう。kawaii pop系ですね。
5-4. Lyrics Textに歌詞のテキストを入力
歌詞の入力です。しぴちゃんに歌詞を考える能力はありませんので、歌詞もLLMに考えさせてみましょう。以下のプロンプトでClaude-3.5 Sonnetに依頼します。Lyricsのフォーマットに合わせてタグも付けさせます。詳細はAppendixにあります。
皆さんが試す場合は好きなプロンプトで好きなAIに依頼してみるのが良いでしょう。
「ねこはかわいい、毎日なでなでしたい」をテーマにした歌の歌詞を考え てください。 10行程度で、ポップでキュートなメロディーにする予定です。
曲をいくつかのパートに分割し、必要に応じて [verse], [chorus], [bridge], [outro] などのタグを利用してください。
出力から歌詞部分を抽出し、ちょっと削って以下のように成形しました。
[verse]
まるい目で みつめてくる
もふもふの しっぽ ゆらゆら
毎日が ハッピーだよ
きみと いっしょなら
[chorus]
なでなで すりすり
ごろごろ ぴょんぴょん
ずっとずっと いっしょだよ
きみは わたしの たからもの
かわいいですね。この歌詞で生成してみましょう。
Claudeの元々の出力は2行×5セッション(セッション:YuE 内部の用語で[verse], [chorus]などのタグで区切られた区間のこと)の10行構成でしたが、ものすごく生成時間がかかったので4行×2セッションに減らしました。
VRAM をオーバーすると急激に遅くなるので、セッション数は2以下の方がいいです。(VRAM 16GB以上のGPUを持っているなら3~4セッション行けるかもしれません。試せる環境がありませんが。)
皆さんが実行する場合、最初からLLMには "[verse] [chorus] の2パートで生成してください" と指示した方が良いと思います。
5-5. その他数値の設定
Lyricsの下の数値の設定を行います。
Number of Segmentsは上のLyricsで作成したセッションの数です。今回は2です。セッション数を増やす場合はこの値を増やします。
Stage1 Cache ModeとStage2 Cache Modeは、YuE-exllamav2の例に倣ってStage 1をQ4, Stage 2をQ8にします。
Max New Tokensは1セッションの長さを決定します。
今回はデフォルトの3000にしておきます。詳細はAppendixにあります。
Use Audio Prompt?, Use Dual Tracks Prompt? はAudio promptの設定です。
vocalとinstが混ざった1ファイルを提供する場合、Use Audio Prompt? にチェックを入れてファイルをアップロードします。
vocalとinstが独立した2ファイルを提供する場合、Use Dual Tracks Prompt? にチェックを入れて、上にvocal, 下にinstをアップロードします。
2ファイルにした方が性能がいいようです。
python-audio-separator やUltimate Vocal Remover GUI でvocalとinstを分離する方法が紹介されています。
Seedで乱数のシードを変更できます。
同じプロンプトでもSeedを変えれば違う楽曲ができます。
画像生成AIと同じく、promptを決めたら乱数を振ってガチャを引くことになります。一回10分かかりますが。
5-6. Generate Musicボタンで生成開始
押して待ちます。
RTX 3080 (VRAM 10GB)で、だいたい6分です。
Max New Tokens × Number of Segments が大きいと長い時間がかかります。
突然進まなくなった場合は楽曲の長さがVRAMをオーバーしています。
Max New Tokens × Number of Segmentsを短くしてください。
6. 生成後
Logsに .mp3 が保存されたと書いてあれば、生成完了です。
下のRefresh File Explorerをクリックすると_mixed.mp3 ファイルが生成されているはずです。Stopを押して生成プロセスを終了しておきます。
reconsフォルダの中にvocal trackとinst trackが入っています。

mp3ファイルにチェックを入れると下に波形が出てきます。
再生ボタンから再生ができます。左下のボタンで音量と再生速度を変更できます。
波形の右上に小さくついているダウンロードアイコンを押すとmp3ファイルがブラウザからダウンロードされます。dockerコンテナから直接持ってくることもできますが、こちらの方が楽です。
今回の作例をsoundcloudにアップロードしてみました。
ねこがかわいい/しぴちゃん with YuE by HKUST/M-A-P.
元気のいい感じを想像していましたが、思ったよりぽやっとした楽曲になりました。"Happy" タグの影響でしょうか。これもかわいいのでOKです。
なお、この楽曲はCC BY-NC-ND 3.0ライセンスです。
7. ライセンス
YuEのモデルそのもののライセンスはApache 2.0ですが、YuEのドキュメント (github, huggingface) によれば、出力を他の自分の作品に利用することを推奨しているとのことです。商用利用も可能です。
制限として、YuE by HKUST/M-A-Pをクレジットすることのみ必要です。
また、生成物をストリーミングサイトなどで公開する場合、“AI-generated”, “YuE-generated", “AI-assisted”, “AI-auxiliated” などのタグをつけることが推奨されています。英語の意味から、AI-generated, YuE-generated はAI生成物をそのまま利用する場合、AI-assisted, AI-auxiliated はAI生成物を素材として利用したり、編曲して公開する場合を指します。
上の「ねこがかわいい/しぴちゃん」にもAI-generatedのタグが付いています。
なお、言うまでもなく
既存の楽曲の歌詞をそのまま利用した生成物
Music promptなどにより既存の素材や作品を剽窃した生成物
などを公開すると著作権に違反し、罰金等が課される可能性があります。絶対にやめましょう。
2025.01.29 🎉: We have updated the license description. we ENCOURAGE artists and content creators to sample and incorporate outputs generated by our model into their own works, and even monetize them. The only requirement is to credit our name: YuE by HKUST/M-A-P (alphabetic order).
以上を守って楽しく音楽生成してください。Happy music AI life!
Appendix
Genresの説明と例
YuEのGenresの説明です。GUIのNoticeにも書いてあります。
Genresに入るものは"genre, instrument, mood, gender, timbre"
5種類のすべてを指定した方がよい
順序はこの順でなくてもよい
Genre: 楽曲のジャンル。例:pop, jazz, rock
Instrument: 使われる楽器。例:alto saxophone, drums
Mood: 楽曲の感情や雰囲気。例: adventure, thoughtful, violent
https://songofamerica.net/wp-content/uploads/2018/08/TONE_WORDS_BY_CATEGORY.doc とかを参考にするGender: 歌う人が男声か女声か。male/female
Timbre: 音色。楽器や音の特性。ボーカルの音色を指定する場合は"○○ vocal"とつける。
ボーカルのtimbreについては"vocal"とテキストエリアに入れると候補が出てくるので、そこから探すとよい。
YuEのデモに使われているGenresの例
Bass Metalcore Thrash Metal Furious bright vocal male Angry aggressive vocal Guitar
female blues airy vocal bright vocal piano sad romantic guitar jazz
rap piano street tough piercing vocal hip-hop synthesizer clear vocal male
inspiring female uplifting pop airy vocal electronic bright vocal vocal
Lyricsの書き方
例はYuEのデモを見るのが一番わかりやすいです。
英語以外に北京中国語、広東中国語、日本語、韓国語に対応している。
英語中国語以外はモデルを切り替えて使う方がたぶん性能が高いLyricsはセッションに分かれて記述し、最初にラベルを付ける
[verse], [chorus], [bridge], [outro], [solo] などのタグがあるセッション間は2回改行する(1行空行を挟む)。
1セッションを長くしすぎない。1セッションは--max_new_tokens 3000なら最大30秒程度。
[intro]ラベルは不安定なので[verse]か[chorus]がよい
超適当に言うと、chorusはサビ、verseはAメロ、bridgeはBメロに対応します。
Max New Tokenの値
1000=約10秒の換算で、デフォルトは3000=約30秒です。
小さくすると1セッションが短くなるかわりに生成が早くなります。
大きくすると1セッションが長くなります。
歌詞がセッションの長さに入りきらない場合ぶち切られてしまうので、長いセッションを作る場合十分な値を入れます。
Seedのデフォルトは42です。
余談ですが、機械学習屋はSeedのデフォルトに42を使う人が多いです。(SF作品『銀河ヒッチハイク・ガイド』が元ネタなので、興味がある人は調べてください)
歌詞なしで曲だけ生成したい
YuEのissue 18にあります。以下のように空の歌詞を入れるのが推奨とのこと。
[verse]
[chorus]
[outro]2セッションで生成する場合は[outro]部分を消します。
また、歌ありの生成でも出力フォルダにinstrumental trackも生成されるので、そこだけ使ってもいいです。
配信BGMなんか作れたら便利ですね。