
[悪戦苦闘の記録]何が現場の生産性をより効率的にするのか[データ分析]

目的
業務の効率を上げる、というテーマはあらゆる職場で求められることです
データ分析を3ヶ月間勉強したので、Pythonを用いて「どんな要素が生産性向上に寄与するのか」を考えて行きたいと思います。
作成者のスキル
プログラミング初学者(Pythonを勉強し始めて2ヶ月)
やったこと
0.データの取り込み
1.【取り急ぎの仮説】アイディアを出したワーカーの資質について中央値を算出し、全体と比較することによってどんな資質がアイディアの創出に役立つのか分析
2.データの加工
3.【精度が低い問題】回帰モデルを作成し、各項目の偏回帰係数を算出
4.【相関の概要の把握】相関係数を算出し作業効率に関係のある項目を確認
5.【精度が低い問題】相関係数に基づいて特徴量の項目を追加
6.【続・精度が低い問題】StandardScalerを用いてデータスケールの標準化
7.【続続・精度が低い問題】one-hotエンコーディングを用いてカテゴリ型データのダミー変数化
8.【続続続・精度が低い問題】新しい分析モデル「LightGBM」
まとめ
データはKaggle上のデータを利用、言語はPython、環境はGoogle Colaboratoryを使用しました。
0.データの取り込み
Kaggleからデータ”Factory Workers’ Daily Performance & Attrition”をダウンロード
KaggleページURL
”https://www.kaggle.com/datasets/gladdenme/factory-workers-daily-performance-attrition-s/data”
1.【取り急ぎの仮説】アイディアを出したワーカーの資質について中央値を算出し、全体と比較することによってどんな資質がアイディアの創出に役立つのか分析
まず全ワーカーの資質(器用さ、強靭さ、社会性など)について要約統計量を算出しました。
import pandas as pd
# data:csvファイルを読み込む
data = pd.read_csv('/content/drive/My Drive/Factory.csv', encoding="UTF-8")
#data2:検証に必要な列のみ抽出
data2 = data[["sub_ID","sub_health_h","sub_commitment_h","sub_perceptiveness_h","sub_dexterity_h","sub_sociality_h","sub_goodness_h","sub_strength_h","sub_openmindedness_h","actual_efficacy_h","behav_comptype_h"]]
#sub_IDが重複する行を削除
data3 = data2.drop_duplicates(subset='sub_ID')
display(data3.describe())全体のワーカーの資質の中央値は以下の通り
health"健康" 中央値:0.765
commitment”献身” 中央値:0.761
perceptiveness”知覚力” 中央値:0.759
dexterity”器用さ” 中央値:0.757
sociality”社会性” 中央値:0.755
goodness”善良さ” 中央値:0.754
strength”強靭さ” 中央値:0.745
openmindedness”寛容さ” 中央値:0.777
次に作業を効率化するアイデアを提案した記録のあるワーカーに絞って中央値を算出しました。
health"健康" 中央値:0.765 →Ideaを出したワーカー 中央値:0.760
commitment”献身” 中央値:0.761 →Ideaを出したワーカー 中央値:0.747
perceptiveness”知覚力” 中央値:0.759 →Ideaを出したワーカー 中央値:0.800
dexterity”器用さ” 中央値:0.757 →Ideaを出したワーカー 中央値:0.762
sociality”社会性” 中央値:0.755 →Ideaを出したワーカー 中央値:0.738
goodness”善良さ” 中央値:0.754 →Ideaを出したワーカー 中央値:0.764
strength”強靭さ” 中央値:0.745 →Ideaを出したワーカー 中央値:0.760
openmindedness”寛容さ” 中央値:0.777 →Ideaを出したワーカー 中央値:0.778
結果、全ワーカーと比べてアイデアを提案したワーカーは知覚力の中央値が高くなっていることがわかりました。まず最初のざっくり仮説として『perceptiveness(知覚力)が効率に影響する』と考えます。
2.データの加工
本格的に分析を開始するためにデータを加工します。具体的には下記2つを実施。
1.項目にNoneを含む行を削除(結果的に工場長の行のみ削除されました)
2.集計したい項目のデータ型をobjectからfloatに変換(Noneの影響でobject型になっていました)
# 欠損値の補完
#data2:検証に必要な列のみ抽出
data2 = data[["actual_efficacy_h","sub_sex","sub_shift","sub_team","sub_role","sub_workstyle_h","sup_sex","sup_role","sub_age","sub_colls_same_sex_prtn","sup_ID","sup_age","sup_sub_age_diff","sup_commitment_h","sup_perceptiveness_h","sup_goodness_h","event_week_in_series","event_day_in_series","event_weekday_num","sub_health_h","sub_commitment_h","sub_perceptiveness_h","sub_dexterity_h","sub_sociality_h","sub_goodness_h","sub_strength_h","sub_openmindedness_h","behav_comptype_h"]]
print(data2.info())
print()
#df_Efficacy:behav_comptype_h列がEfficacyの行のみ抽出
df_Efficacy = data2[data2['behav_comptype_h'].isin(['Efficacy'])]
df_Efficacy = df_Efficacy.reset_index()
#欠損値のカウント
df_Efficacy2 = df_Efficacy.replace(['NaN', 'None', ''], float('nan'))
print(df_Efficacy2.isnull().sum())
#欠損値の補完
df_Efficacy3 = df_Efficacy2.dropna()
print(df_Efficacy3.isnull().sum())
print()
#d"actual_efficacy_h"の値をfloat型に変更
df_Efficacy3['actual_efficacy_h'] = df_Efficacy3['actual_efficacy_h'].astype(float)
df_Efficacy3['sub_colls_same_sex_prtn'] = df_Efficacy3['sub_colls_same_sex_prtn'].astype(float)
df_Efficacy3['sup_ID'] = df_Efficacy3['sup_ID'].astype(float)
df_Efficacy3['sup_age'] = df_Efficacy3['sup_age'].astype(float)
df_Efficacy3['sup_sub_age_diff'] = df_Efficacy3['sup_sub_age_diff'].astype(float)
df_Efficacy3['sup_commitment_h'] = df_Efficacy3['sup_commitment_h'].astype(float)
df_Efficacy3['sup_perceptiveness_h'] = df_Efficacy3['sup_perceptiveness_h'].astype(float)
df_Efficacy3['sup_goodness_h'] = df_Efficacy3['sup_goodness_h'].astype(float)
print(df_Efficacy3.info())
3.【精度が低い問題】回帰モデルを作成し、各項目の偏回帰係数を算出
加工したデータについて作業効率を求める回帰モデルを作成しました。
今回は線形回帰、リッジ回帰、ラッソ回帰を全て実施して結果を比較しました。
#各ワーカーの資質から線形回帰、ラッソ回帰、リッジ回帰の比較
# sklearn.linear_model.LinearRegression クラスを読み込み
import numpy as np
from sklearn.linear_model import Ridge
from sklearn.linear_model import Lasso
from sklearn.linear_model import LinearRegression
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
#data2:検証に必要な列のみ抽出
data2 = data[["sub_health_h","sub_commitment_h","sub_perceptiveness_h","sub_dexterity_h","sub_sociality_h","sub_goodness_h","sub_strength_h","sub_openmindedness_h","actual_efficacy_h","behav_comptype_h"]]
#df_Efficacy:behav_comptype_h列がEfficacyの行のみ抽出
df_Efficacy = data2[data2['behav_comptype_h'].isin(['Efficacy'])]
#df_Efficacy3:説明変数にsub_ID、actual_efficacy_h(作業効率)" 以外全てを利用
df_Efficacy3 = df_Efficacy.drop("actual_efficacy_h", axis=1)
df_Efficacy4 = df_Efficacy3.drop("behav_comptype_h", axis=1)
X = df_Efficacy4
# 目的変数に "actual_efficacy_h(作業効率)" を利用
y = df_Efficacy['actual_efficacy_h']
# 「X_train, X_test, y_train, y_test」にデータを格納します。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 線形回帰
model_Linear = LinearRegression()
model_Linear.fit(X_train, y_train)
# ラッソ回帰
model_Lasso = Lasso()
model_Lasso.fit(X_train, y_train)
# リッジ回帰
model_Ridge = Ridge()
model_Ridge.fit(X_train, y_train)
# X_test, y_testに対する決定係数を出力
print("Linear regression:{}".format(model_Linear.score(X_test, y_test)))
print("Lasso regression:{}".format(model_Lasso.score(X_test, y_test)))
print("Ridge regression:{}".format(model_Ridge.score(X_test, y_test)))
実行結果は以下の通り。ここで問題発生。作成したモデルの精度が低すぎました。(0.8以上が精度の高いモデルとされるそう)
決定係数
Linear regression:0.005551224975523961
Lasso regression:-0.0004301234075503313
Ridge regression:0.005552188872217312
4.【相関の概要の把握】相関係数を算出し作業効率に関係のある項目を確認
そもそも仮説が大きく違っており、各ワーカーの資質と作業効率に相関が薄そうなことが判明しました。
そこで今更ですが作業効率に対する全項目の相関係数を求めてみました。
#各列の相関を分析
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
df_Efficacy3_corr = df_Efficacy3.corr()
y_corr = df_Efficacy3_corr['actual_efficacy_h']
print(y_corr)
#y_corrには特定の列の相関係数を格納
fig, ax = plt.subplots(figsize=(10, 10))
#横棒グラフ作成
sns.barplot(x=y_corr, y=y_corr.index, ax=ax)
#X,Y軸とグラフタイトル
ax.set_xlabel("Correlation Coefficient")
ax.set_ylabel("Features")
#表示
plt.show()
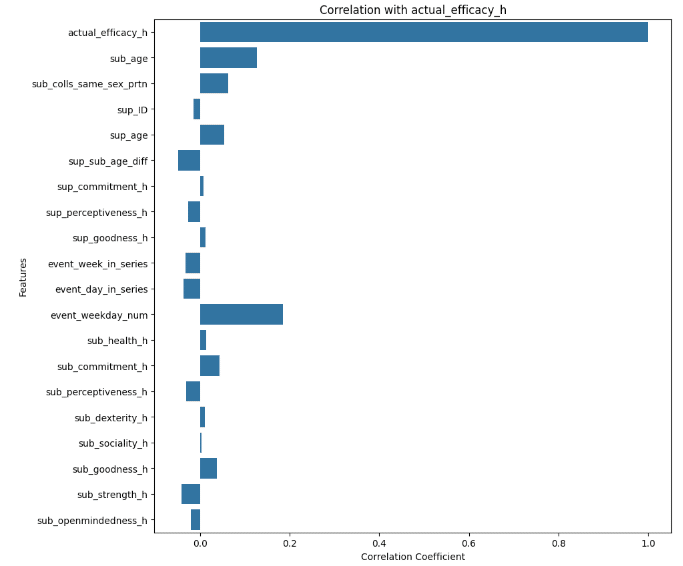
ワーカーの資質はあまり関係なく、関係ありそうな項目が「event_weekday_num(曜日)」と「sub_age(作業者の年齢)」という結果に。どうやら週の初めから終わりに向かうにつれて効率が上がっているようです。また、作業者の年齢によって作業効率は影響を受けていました。

5.【精度が低い問題】相関係数に基づいて特徴量の項目を追加
相関係数が比較的大きなevent_weekday_numとsub_ageに絞って回帰モデルの作成を行いました。
相関係数が比較的高いevent_weekday_numとsub_ageから線形回帰、リッジ回帰、ラッソ回帰の比較
# sklearn.linear_model.LinearRegression クラスを読み込み
import numpy as np
from sklearn.linear_model import Ridge
from sklearn.linear_model import Lasso
from sklearn.linear_model import LinearRegression
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
#df_Efficacy5:説明変数にsub_ID、actual_efficacy_h(作業効率)" 以外全てを利用
df_Efficacy4 = df_Efficacy3.loc[:,['event_weekday_num','sub_age']]
X = df_Efficacy4
print("説明変数の全体像(info)")
display(df_Efficacy4.info())
print()
# 目的変数に "actual_efficacy_h(作業効率)" を利用
y = df_Efficacy3['actual_efficacy_h']
# 「X_train, X_test, y_train, y_test」にデータを格納します。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# トレーニングデータから変換モデルを学習し、テストデータに適用
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
# 線形回帰
model_Linear = LinearRegression()
model_Linear.fit(X_train, y_train)
# ラッソ回帰
model_Lasso = Lasso()
model_Lasso.fit(X_train, y_train)
# リッジ回帰
model_Ridge = Ridge()
model_Ridge.fit(X_train, y_train)
# X_test, y_testに対する決定係数を出力
print("決定変数")
print("Linear regression:{}".format(model_Linear.score(X_test, y_test)))
print("Lasso regression:{}".format(model_Lasso.score(X_test, y_test)))
print("Ridge regression:{}".format(model_Ridge.score(X_test, y_test)))
実行の結果、決定変数は0.005から0.04に上がりましたがまだまだ低い。
一筋縄では行かないようです。。。
6.【続・精度が低い問題】StandardScalerを用いてデータスケールの標準化
0〜1の間を取る項目が多いものの年齢などの比較的大きい数字もあることから標準化によって重みの偏りをなくすことを試みます。「3.【精度が低い問題】回帰モデルを作成し、各項目の偏回帰係数を算出」で作成した全項目の回帰モデルにStandardScalerを用いて標準化を行いました。
# 標準化のためのインスタンスを生成
sc = StandardScaler()
# トレーニングデータから変換モデルを学習し、テストデータに適用
X_train_std = sc.fit_transform(X_train)
X_test_std = sc.transform(X_test)
# 線形回帰
model_Linear = LinearRegression()
model_Linear.fit(X_train_std, y_train)
# ラッソ回帰
model_Lasso = Lasso()
model_Lasso.fit(X_train_std, y_train)
# リッジ回帰
model_Ridge = Ridge()
model_Ridge.fit(X_train_std, y_train)
# X_test, y_testに対する決定係数を出力
print("決定変数")
print("Linear regression:{}".format(model_Linear.score(X_test_std, y_test)))
print("Lasso regression:{}".format(model_Lasso.score(X_test_std, y_test)))
print("Ridge regression:{}".format(model_Ridge.score(X_test_std, y_test)))
実行結果は以下の通り。多少改善しました。
決定変数
Linear regression:0.05601631464105972
Lasso regression:-4.6334526003555254e-05
Ridge regression:0.05623078343490129
ちなみに「5.【精度が低い問題】相関係数に基づいて特徴量の項目を追加」で作成した相関関係の比較的大きな項目に絞ったモデルも標準化しましたが、大差ありませんでした。
決定変数
Linear regression:0.04078661622751589
Lasso regression:-4.6334526003555254e-05
Ridge regression:0.04078715561892876
7.【続続・精度が低い問題】one-hotエンコーディングを用いてカテゴリ型データのダミー変数化
藁にもすがる思いで他に有効な特徴量を追加できないか考えてみます。
数字ではなかった為に除外していた下記の項目の中に相関関係のあるものがある可能性を信じてone-hotエンコーディングを用いてカテゴリ型データのダミー変数化を試みます。
sub_sex(作業者の性別)、sub_shift(作業者のシフト)、sub_team(作業者のチーム)、sub_role(作業者の役職)、sub_workstyle_h(作業者の働き方)、sup_sex(上司の性別)、sup_role(上司の役職)
# 欠損値の補完
#data2:検証に必要な列のみ抽出
data2 = data[["actual_efficacy_h","sub_sex","sub_shift","sub_team","sub_role","sub_workstyle_h","sup_sex","sup_role","sub_age","sub_colls_same_sex_prtn","sup_ID","sup_age","sup_sub_age_diff","sup_commitment_h","sup_perceptiveness_h","sup_goodness_h","event_week_in_series","event_day_in_series","event_weekday_num","sub_health_h","sub_commitment_h","sub_perceptiveness_h","sub_dexterity_h","sub_sociality_h","sub_goodness_h","sub_strength_h","sub_openmindedness_h","behav_comptype_h"]]
print(data2.info())
print()
#df_Efficacy:behav_comptype_h列がEfficacyの行のみ抽出
df_Efficacy = data2[data2['behav_comptype_h'].isin(['Efficacy'])]
df_Efficacy = df_Efficacy.reset_index()
#欠損値のカウント
df_Efficacy2 = df_Efficacy.replace(['NaN', 'None', ''], float('nan'))
print(df_Efficacy2.isnull().sum())
#欠損値の補完
df_Efficacy3 = df_Efficacy2.dropna()
print(df_Efficacy3.isnull().sum())
print()
#"actual_efficacy_h"の値をfloat型に変更
df_Efficacy3['actual_efficacy_h'] = df_Efficacy3['actual_efficacy_h'].astype(float)
df_Efficacy3['sub_colls_same_sex_prtn'] = df_Efficacy3['sub_colls_same_sex_prtn'].astype(float)
df_Efficacy3['sup_ID'] = df_Efficacy3['sup_ID'].astype(float)
df_Efficacy3['sup_age'] = df_Efficacy3['sup_age'].astype(float)
df_Efficacy3['sup_sub_age_diff'] = df_Efficacy3['sup_sub_age_diff'].astype(float)
df_Efficacy3['sup_commitment_h'] = df_Efficacy3['sup_commitment_h'].astype(float)
df_Efficacy3['sup_perceptiveness_h'] = df_Efficacy3['sup_perceptiveness_h'].astype(float)
df_Efficacy3['sup_goodness_h'] = df_Efficacy3['sup_goodness_h'].astype(float)
#df_Efficacy3:one-hotエンコーディング
df_Efficacy3 = pd.get_dummies(df_Efficacy3)
print(df_Efficacy3.info())
試行錯誤の結果、「#df_Efficacy4:one-hotエンコーディング」の場所は最下部になりました。これより前に実施すると欠損値として検知されなかったり、Float型に直せなくなります。

嬉しいことに「sub_workstyle_h」によって正負の相関があることが見えてきました。
【参考】
kaggleによると「sub_workstyle_h」は各ワーカーのワークスタイルの違いのようですが、詳細の内容は不明でした。
The subject’s “Workstyle group” influences his or her Efficacy (which will be elevated, average, or reduced and either stable or variable); number of Disruptions (either elevated, average, or reduced); and number of Ideas (elevated, average, or reduced). Possible values are “Group A”, “Group B”, “Group C”, “Group D”, and “Group E”. Each Workstyle group has its own characteristic pattern of influences.(原文)
被験者の「ワークスタイルグループ」は、その人の有効性(上昇、平均、または低下し、安定または変動します)に影響を与えます。中断の数 (増加、平均、減少のいずれか)。およびアイデアの数 (増加、平均、または減少)。可能な値は、「グループ A」、「グループ B」、「グループ C」、「グループ D」、および「グループ E」です。各ワークスタイル グループには、独自の特徴的な影響パターンがあります。(Google翻訳)
期待しながら「3.【精度が低い問題】回帰モデルを作成し、各項目の偏回帰係数を算出」で作成した全項目の回帰モデルを再度実行します。
すると、、、!
決定変数
Linear regression:0.14985393814775505
Lasso regression:-4.6334526003555254e-05
Ridge regression:0.14971318806553424
線形回帰(Linear regression)の0.04が0.14に
リッジ回帰(Ridge regression)も0.04が0.14に向上しています!!
まだまだ回帰モデルの精度としては低いものの、決定変数は当初の約30倍になりました。
やっと本題のリッジ回帰モデルの偏回帰係数を調べてみました。
#リッジ回帰モデルの偏回帰係数
pd.options.display.max_rows = 20
display(pd.DataFrame({"Name":df_Efficacy5.columns,
"Coefficients":model_Ridge.coef_}).sort_values(by='Coefficients') )
正の相関と負の相関のそれぞれのTop1〜5が判明しました。
特定のワークスタイルやチームが効率を悪化させていることが見えてきましたね。
また、event_day_in_series(記録を始めてからの日数)が正の相関をもっているということは職場全体として効率が向上していると言えると思います。
8.【続続続・精度が低い問題】新しい分析モデル「LightGBM」
カウンセラーの方にもう少し新しい分析モデル「LightGBM」を教えて頂き試してみました。
# LightGBM
import lightgbm as lgb
# Scikit-learn(評価算出)
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
#df_Efficacy5:説明変数にsub_ID、actual_efficacy_h(作業効率)" 以外全てを利用
df_Efficacy4 = df_Efficacy3.drop("actual_efficacy_h", axis=1)
df_Efficacy5 = df_Efficacy4.drop("behav_comptype_h_Efficacy", axis=1)
X = df_Efficacy5
# 目的変数に "actual_efficacy_h(作業効率)" を利用
y = df_Efficacy3['actual_efficacy_h']
# 「X_train, X_test, y_train, y_test」にデータを格納します。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 標準化のためのインスタンスを生成
sc = StandardScaler()
# トレーニングデータから変換モデルを学習し、テストデータに適用
X_train_std = sc.fit_transform(X_train)
X_test_std = sc.transform(X_test)
#モデルの作成と学習
model = lgb.LGBMRegressor()
pred_y = model.fit(X_train_std,y_train)
pred_y.score(X_test_std,y_test)
# 特徴量の重要度の算出
pd.Series(model.feature_importances_,index=X_train.columns)実行結果
[LightGBM] [Info] Total Bins 2763
[LightGBM] [Info] Number of data points in the train set: 24372, number of used features: 63
[LightGBM] [Info] Start training from score 0.706180
決定変数 LightGBM:0.23857430123617174
さすが新しいモデル、倍近く精度が向上しました!
モデル精度の作業は非常に楽しいですね!!
各特徴量の重みも簡単に算出できました
重要度
event_weekday_num 180
sub_age 149
sub_commitment_h 108
sub_dexterity_h 115
sub_goodness_h 115
sub_health_h 161
sub_openmindedness_h 122
sub_perceptiveness_h 121
sup_age 104
sup_sub_age_diff 318
event_weekday_numが重要なことはリッジ回帰の時と変わりませんがLightGBMではsup_sub_age_diff(上司との年齢差)がより重要となっていました。
まとめ
まだまだ回帰モデルの精度が低い為、仮説の域をでませんが下記のことがわかりました。
最初は作業効率は個人の資質によると思っていたがそうではなく、所属するチームやワークスタイルにより依存する。また上司との年齢差の影響を受ける。
回帰モデルの精度を上げていく作業は思った以上に楽しくできました!
いつか決定変数0.8越えにもチャレンジしたいと思います。
※このブログはAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開しています。