
【Wikimediaデータプロセシング】Kafkaを実際に適用する- Springboot3 第14回

はじめに
こんにちは、今日は前回のKafkaの勉強に続き、Wikimediaのデータ処理をするのに実際に適用してみます。Wikimediaには大量のデータがリアルタイムで素早く流通するので、Kafkaを活用することはとても良い勉強になると思います。
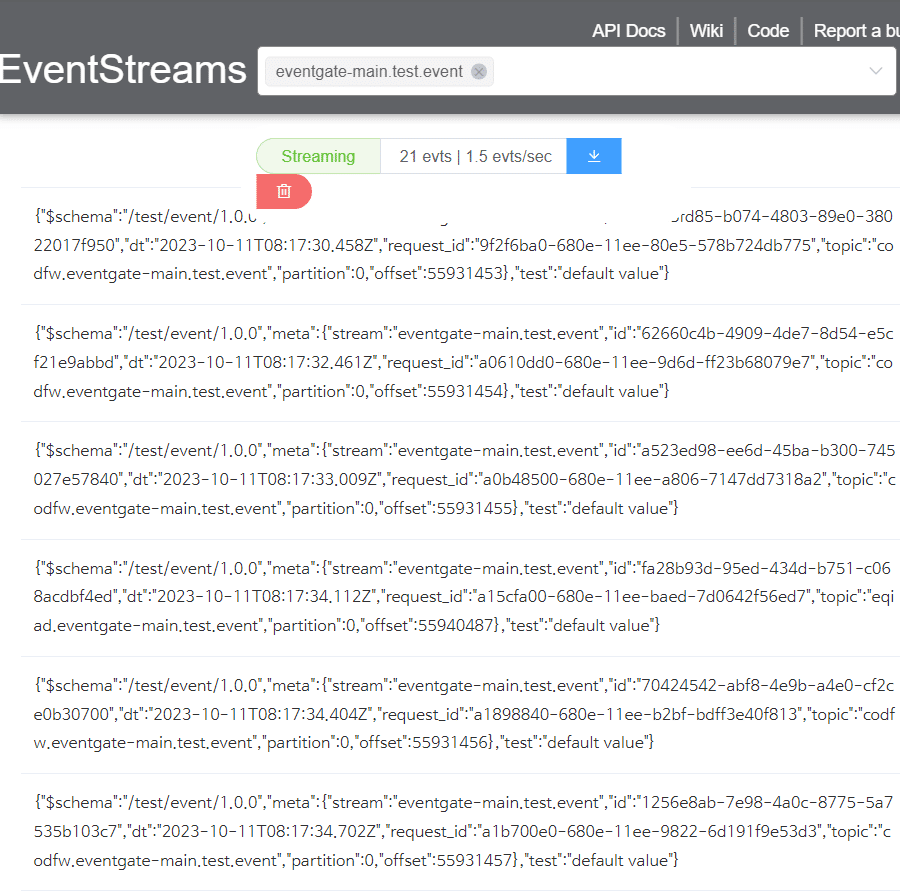
リアルタイム情報が素早く流通する。

実装過程
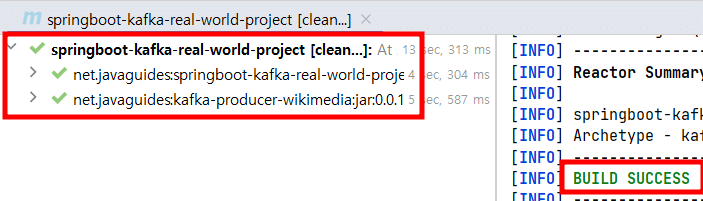
1.プロジェクト生成

KafkaとLombokの依存性を追加します。
このプロジェクトをマルチモジュールにするために必要な変更を行おします。

自分のプロジェクトでマルチモジュールを作成するときは、
必ずパッケージングを親プロジェクトのpomとして提供します。


NameとArchetypeを設定して、
モジュール生成します。


このモジュールをSpring Bootプロジェクトとして作ってみよう。
@SpringBootApplication
public class SpringBootProducerApplication {
public static void main(String[] args) {
SpringApplication.run(SpringBootProducerApplication.class);
}
}


kafkaに与えます。

2.Producerの設定とTopicの作成
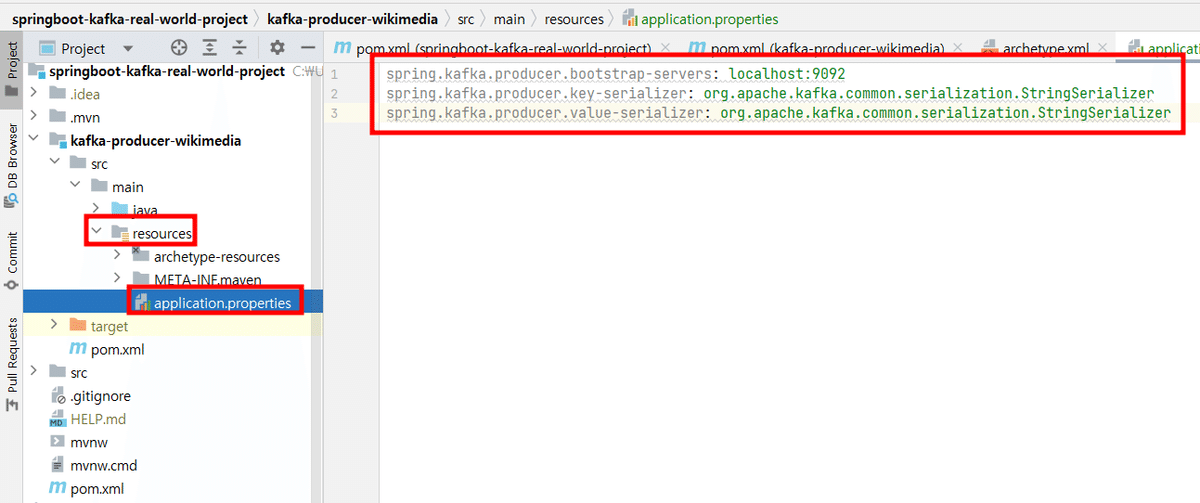
Kafkaブローカーへの接続情報を指定します。
メッセージのキーを変換するシリアライザのクラスを指定。
メッセージの値を変換するシリアライザのクラスを指定。
spring.kafka.producer.bootstrap-servers: localhost:9092
spring.kafka.producer.key-serializer: org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer: org.apache.kafka.common.serialization.StringSerializer
Kafkaブローカーに「wikimedia_recentchange」という名前の Topicが存在することを確認し、存在しない場合は新しく作成することです。
@Configuration
public class KafkaTopicConfig {
@Bean
public NewTopic topic() {
return TopicBuilder.name("wikimedia_recentchange")
.build();
}
}3. Producerの実装と実行
実装

このクラスはKafkaにメッセージを送信する役割をします。
@Service
public class WikimediaChangesProducer {
private static final Logger LOGGER = LoggerFactory.getLogger(WikimediaChangesProducer.class);
private KafkaTemplate<String, String> kafkaTemplate;
public WikimediaChangesProducer(KafkaTemplate<String, String> kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
public void sendMessage() {
String topic = "wikimedia_recentchange";
// to read real time stream data from wikimedia, we use event source
}
3つのライブラリを追加していきましょう。
https://mvnrepository.com/artifact/com.launchdarkly/okhttp-eventsource/3.0.0

https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-core/2.14.2

https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-databind/2.14.2
<dependencies>
<!-- https://mvnrepository.com/artifact/com.launchdarkly/okhttp-eventsource -->
<dependency>
<groupId>com.launchdarkly</groupId>
<artifactId>okhttp-eventsource</artifactId>
<version>3.0.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-core -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.14.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-databind -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.14.2</version>
</dependency>
</dependencies>Jackson Databindは、JavaオブジェクトとJSONデータとの間でのデータの結びつけます。JavaオブジェクトをJSONデータに変換するシリアライザ(Serialization)と、逆にJSONデータをJavaオブジェクトに変換するデシリアライザ(Deserialization)を提供します。





下記のコードを完成します。
@Service
public class WikimediaChangesProducer {
private static final Logger LOGGER = LoggerFactory.getLogger(WikimediaChangesProducer.class);
private KafkaTemplate<String, String> kafkaTemplate;
public WikimediaChangesProducer(KafkaTemplate<String, String> kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
public void sendMessage() throws InterruptedException {
String topic = "wikimedia_recentchange";
// to read real time stream data from wikimedia, we use event source
EventHandler eventHandler = new WikimediaChangesHandler(kafkaTemplate, topic);
String url = "https://stream.wikimedia.org/v2/stream/recentchange";
EventSource.Builder builder = new EventSource.Builder(eventHandler, URI.create(url));
EventSource eventSource = builder.build();
eventSource.start();
TimeUnit.MINUTES.sleep(10);
}
}sendMessageメソッド
sendMessageメソッドは、指定されたKafkaトピックにWikimediaのリアルタイムストリームデータを送信します。
EventHandlerというインターフェースを実装したクラス WikimediaChangesHandler を使用して、Wikimediaの変更データを処理するためのイベントハンドラを作成します。
EventSourceを使用して、Wikimediaのストリームエンドポイントからのリアルタイムイベントを購読します。これにより、Wikimediaからの変更データを受信できます。
TimeUnit.MINUTES.sleep(10)により、プログラムが10分間スリープすることで、イベントソースが10分間起動し続け、データを受信できるようになります。
実行

CommandLineRunner インターフェースを実装しています。
runメソッド内では、WikimediaChangesProducerを注入し、sendMessageメソッドを呼び出しています。
これにより、WikimediaChangesProducerがKafkaにメッセージを送信する処理が実行されます。
@SpringBootApplication
public class SpringBootProducerApplication implements CommandLineRunner {
public static void main(String[] args) {
SpringApplication.run(SpringBootProducerApplication.class);
}
@Autowired
private WikimediaChangesProducer wikimediaChangesProducer;
@Override
public void run(String... args) throws Exception {
wikimediaChangesProducer.sendMessage();
}
}
Zookeeperの実行

Kafkaブロッカーの実行

トピック名をwikimedia_recentchangeに変更した後、
コンシューマーはイベントを読み込む


4. Consumerプロジェクト・設定・クラスの実装




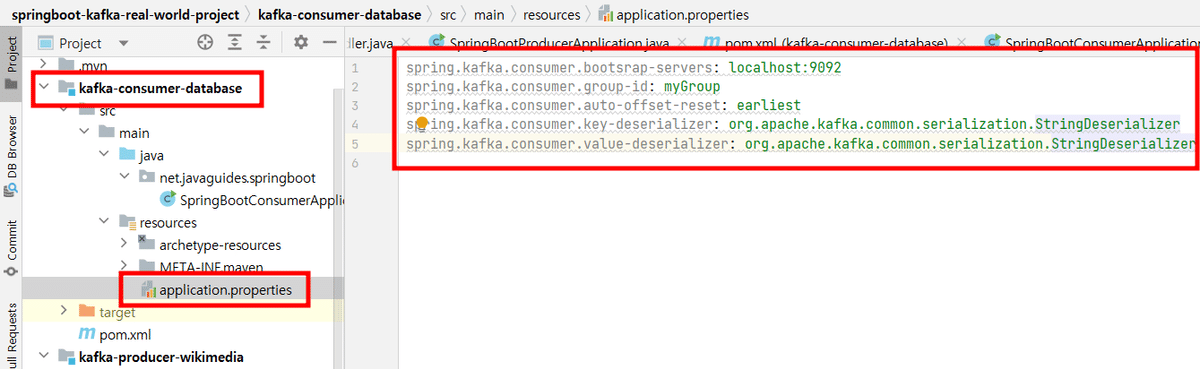
spring.kafka.consumer.bootsrap-servers: localhost:9092
spring.kafka.consumer.group-id: myGroup
spring.kafka.consumer.auto-offset-reset: earliest
spring.kafka.consumer.key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.group-id: myGroup
コンシューマーグループのIDを指定します。同じグループIDを持つコンシューマーは、同じトピックの異なるパーティションを分担して処理します。この設定により、メッセージがどのコンシューマーに届くかが制御されます。
spring.kafka.consumer.auto-offset-reset: earliest
コンシューマーグループが初めてトピックに参加するときや、オフセットが失われた場合に、どのオフセットからメッセージを読み始めるかを指定します。earliestは最も古い利用可能なメッセージから読み始めることを示します。

@Service
public class KafkaDatabaseConsumer {
private static final Logger LOGGER = LoggerFactory.getLogger(KafkaDatabaseConsumer.class);
@KafkaListener(
topics = "wikimedia_recentchange",
groupId = "myGroup"
)
public void consume(String eventMessage){
LOGGER.info(String.format("Message received -> %s", eventMessage));
}
}@KafkaListener アノテーション:
@KafkaListenerアノテーションは、メソッドがKafkaトピックからメッセージをリッスンすることを示します。
topics属性によって、リッスンするKafkaトピックの名前が指定されています。この例では "wikimedia_recentchange" というトピックを指定しています。
groupId属性によって、このコンシューマーが所属するコンシューマーグループのIDが指定されています。この例では "myGroup" というグループIDを使用しています。
consumeメソッド
consumeメソッドは、Kafkaトピックから受信したメッセージを処理するためのメソッドです。

プロデューサーにはイベントデータに関する情報が、
コンシューマーにはMessage receivedに関するデータが
素早く出力されます。
5. MySQLの設定と格納

create database wikimediaと入力すると、
スキーマにwikimediaが生成されました。


<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>

spring.datasource.url=jdbc:mysql://localhost:3306/wikimedia
spring.datasource..username=root
spring.datasource.password=1234
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQLDialect
spring.jpa.hibernate.ddl-auto=update
spring.jpa.properties.hibernate.show_sql=true
spring.jpa.properties.hibernate.use_sql_comments=true
spring.jpa.properties.hibernate.format_sql=true

@Lobは、RDBのテーブルに、
単独で巨大なサイズになるデータを格納する構造です。
@Entity
@Table(name = "wikimedia_recentchange")
@Getter
@Setter
public class WikimediaData {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Lob
private String wikiEventData;
}エンティティを上記のように作成します。

public interface WikimediaDataRepository extends JpaRepository<WikimediaData, Long> {
}

このスプリング・ビンにはパラメータ化されたコンストラクタが1つしかないので、アノテーションを追加する必要はありません。
@Service
public class KafkaDatabaseConsumer {
private static final Logger LOGGER = LoggerFactory.getLogger(KafkaDatabaseConsumer.class);
private WikimediaDataRepository dataRepository;
public KafkaDatabaseConsumer(WikimediaDataRepository dataRepository) {
this.dataRepository = dataRepository;
}
@KafkaListener(
topics = "wikimedia_recentchange",
groupId = "myGroup"
)
public void consume(String eventMessage){
LOGGER.info(String.format("Message received -> %s", eventMessage));
WikimediaData wikimediaData = new WikimediaData();
wikimediaData.setWikiEventData(eventMessage);
dataRepository.save(wikimediaData);
}
}spring.datasource.url=jdbc:mysql://localhost:3306/wikimedia
spring.datasource..username=root
spring.datasource.password=1234データがDBに格納されなって、ずっと悩んでいたのですが、フィールドのタイプが変わらなかったのが原因でした。 そうなった最終的な原因が何なのか探り続けて、最終的にタイプミスを発見しました。犯人はapplication.propertiesの"spring.datasource..username"=>点が2回入っていた。 datasource.usernameに修正しました。忍耐力をテストするサプライズバグでした。
spring.kafka.consumer.bootstrap-servers: localhost:9092
spring.kafka.consumer.group-id: myGroup
spring.kafka.consumer.auto-offset-reset: earliest
spring.kafka.consumer.key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
spring.datasource.url=jdbc:mysql://localhost:3306/wikimedia
spring.datasource.username=root
spring.datasource.password=1234
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL8Dialect
spring.jpa.hibernate.ddl-auto=create-drop
spring.jpa.properties.hibernate.show_sql=true
spring.jpa.properties.hibernate.use_sql_comments=true
spring.jpa.properties.hibernate.format_sql=true
今まで設定ファイルで修正すべき部分は3つあります。
1.bootstarpの誤字をbootstrapに修正する
2. ..userを.userに修正する
3.updateをcreate-dropに修正する
アプリケーションの実行時にカラムサイズが適用されない理由は、Spring Bootがspring.jpa.hibernate.ddl-auto属性をupdateに設定したためです。 この属性は、アプリケーションの起動時、Spring Bootが既存のテーブルを変更しないように指定します。カラムサイズを適用するには、spring.jpa.hibernate.ddl-auto属性をcreateまたはcreate-dropに設定する必要があります。 この属性は、アプリケーションの起動時、Spring Bootが既存のテーブルを削除して再作成するように指定します。


6. リファクタリング: TopicNameの外部化/ハードコーディングの削除

@Value アノテーションで活用します。

@Configuration
public class KafkaTopicConfig {
@Value("${spring.kafka.topic.name}")
private String topicName;
@Bean
public NewTopic topic() {
return TopicBuilder.name(topicName)
.build();
}
}

@Service
public class WikimediaChangesProducer {
@Value("${spring.kafka.topic.name}")
private String topicName;
private static final Logger LOGGER = LoggerFactory.getLogger(WikimediaChangesProducer.class);
private KafkaTemplate<String, String> kafkaTemplate;
public WikimediaChangesProducer(KafkaTemplate<String, String> kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
public void sendMessage() throws InterruptedException {
String topic = topicName;
// to read real time stream data from wikimedia, we use event source
EventHandler eventHandler = new WikimediaChangesHandler(kafkaTemplate, topic);
String url = "https://stream.wikimedia.org/v2/stream/recentchange";
EventSource.Builder builder = new EventSource.Builder(eventHandler, URI.create(url));
EventSource eventSource = builder.build();
eventSource.start();
TimeUnit.MINUTES.sleep(10);
}
}
spring.kafka.consumer.group-idもつかわれます。

修正しました!
最後に
今日はKafkaを使ってproducerサービスとconsumerサービス、二つのマイクロサービスでWikimediaストリームデータをmysqlデータベースに格納するプロジェクトをやってみました。

実際に流通されるデータを使ってみると、実感が湧きますね。 このようにKafkaは大量のデータを処理するのに特化したプラットフォームであることがはっきり分かりました!次回はEvent Drivenという観点でKafkaを勉強してみたいと思います。
エンジニアファーストの会社 株式会社CRE-CO
ソンさん
【参考】
[Udemy] Building Microservices with Spring Boot & Spring Cloud