
データ分析の前にやっておくべきこと - 横持ち、縦持ち、整然データ構造の話 -

こんにちは。コグラフ株式会社データアナリティクス事業部の塩見です。
データ分析に取り組む際、データの持ち方によってその後の作業効率や分析のしやすさが大きく変わることをご存知でしょうか?特に「横持ちデータ」と「縦持ちデータ」については、しっかりと理解しておくことで、分析の負担を大きく減らすことができます。
この記事では、データ分析の前に知っておくべき「横持ち」「縦持ち」について解説し、横持ちデータから縦持ちデータに変換することの重要性を説明します。データ構造を整理することで、データ分析を効率的に行うことができます。
また「整然データ」という考え方についても解説します。データ構造設計の指針となる考え方を知って、快適にデータ分析に取り組みましょう。
横持ちデータとは?
「横持ちデータ」は、エクセルなどの表計算ソフトでよく見られる形式です。項目が横方向に展開され、各行にデータが収められる構造になっています。例えば、以下のような架空の応募データを考えてみます。

このデータは、応募者NOごとに一意であり、横方向に情報が展開されています。応募者NO.1は1月16日に一次面接を受け、その結果は「○」。続いて1月23日に二次面接を受け、結果は「×」でした。この形式は、一見すると簡潔でわかりやすいように見えますが、データ分析の段階になると、問題を引き起こすことがあります。
横持ちデータを分析してみる
一次面接合格者の二次面接通過率を求めてみましょう。応募データを集計すると、一次面接合格者は「結果_1」が「○」の応募者で、その人数は3人です。同様に、二次面接合格者は「結果_2」が「○」の人数で、1人と集計されます。

これらの結果はそれぞれ別のテーブルに保存されていますが、両者を結合して一つのテーブルに統合します。

最後に、一次面接合格者の二次面接通過率は、二次面接合格者の人数(1人)を一次面接合格者の人数(3人)で割ることで求められます。結果として、通過率は1/3です。
このように、通過率を求めることはできました。ただし、この方法には課題があります。選考段階が増えるたびに、集計手順も修正が必要になるため、処理が煩雑になる可能性があるのです。
横持ちデータの問題点
横持ちデータは、データを目で確認するには便利ですが、分析や処理を行う際には次のような問題が生じることがあります。
データの操作が難しい 集計や可視化を行う際、各列に対して個別の処理を行う必要があり、手間がかかります。例えば、一次面接と二次面接の結果をまとめて集計したい場合、列ごとに処理をする必要があります。
分析ツールとの相性が悪い 多くのデータ分析ツールやライブラリは、横持ちデータではなく「縦持ちデータ」を想定しています。横持ちのままでは、ツールの機能を最大限に活用できない場合があります。
縦持ちデータに変換する
では、横持ちデータを「縦持ちデータ」に変換してみましょう。縦持ちデータとは、各観測値が1行ずつに収められた形式です。上記の応募データを縦持ちに変換すると、次のような形になります。

この形式にすることで、分析や集計が非常に簡単になります。例えば、「全応募者の一次面接結果の合格率を計算する」「二次面接での合格者の割合を出す」といった操作が、ツール上で簡単に行えるようになります。
縦持ちデータを分析してみる
一次面接合格者の二次面接通過率を求めてみましょう。応募データを集計し、選考段階別、結果別の人数を求めます。

上記から「結果」が「○」のレコードだけを抽出します。

人数列の値を一行下にずらしたlag列を作成します。

人数をlagで割り、通過率を求めます。

いかがでしょう。とても洗練された方法で分析できたと思いませんか。これなら選考段階が増えても手順の修正なしで対応できますね。
縦持ちデータの利点
縦持ちデータには次のような利点があります。
集計や分析が効率的 縦持ちデータは、集計や分析の際に非常に柔軟です。例えば、一次面接の合格者だけを抽出したり、特定の選考段階の結果だけを分析したりすることが容易になります。
分析ツールとの親和性 多くのデータ分析ツールやライブラリは、縦持ちデータに最適化されています。SQLをはじめ、PythonのPandasやRのdplyrなど、強力なデータ処理ライブラリは、縦持ちデータに対して簡単かつ効率的に操作を行うことができます。
整然データとは?
ここで、さらに一歩進んで「整然データ」について考えてみましょう。整然データとは、Hadley Wickham氏が提唱した概念で、「データ分析のために適切な形に整えられたデータ構造」を指します。整然データの特徴は以下の通りです。
1. Each variable forms a column. 各変数は1つの列
2. Each observation forms a row. 各観測値は1つの行
3. Each type of observational unit forms a table. 各観測単位は1つのテーブル
整然データの概念に従えば、データは一貫性を持って整理され、分析の際に不要な手間を省くことができます。先ほどの縦持ちデータも、整然データの一例と言えます。以下では、整然データの特徴について個別に詳しく説明します。
特徴1. 各変数は1つの列
再度、応募データ(横持ち)を見てみましょう。このデータでは、「面接日」という変数が「面接日_1」や「面接日_2」のように、一次面接と二次面接で分かれています。「結果」という変数も同様に分割されています。そのため、このデータは「整然データ」の特徴である「各変数は1つの列」という条件を満たしていません。このような整然ではないデータのことを「雑然データ」と呼びます。

特徴2. 各観測値は1つの行
応募データ(横持ち)の観測値に注目します。本来は応募者NOと選考段階をそれぞれ変数とする必要があります。例えば、応募者NO.1の場合、選考段階「一次」で1つの観測値、選考段階「二次」で別の観測値として記録するのが理想です。しかし、現在のデータ形式では、これら2つの観測値が1行にまとめられており、「各観測値は1つの行」という整然データの特徴を満たしていません。

雑然データから整然データへ
このように実務のデータは、しばしば「雑然データ」として存在します。これは、分析のためには適していない構造のデータです。整然データに変換することで、データの見通しが良くなり、効率的な分析が可能になります。前段で「縦持ち」として紹介したデータを下図に再掲します。このデータは、整然データの以下の特徴をどちらも満たしています。
1.各変数は1つの列
2.各観測地は1つの行

特徴3.各観測単位は1つのテーブル
データセットには、複数のレベルや異なるタイプの観測単位で収集された情報が含まれることがあります。この場合、異なる観測単位のデータはそれぞれ別のテーブルに分けて格納すべきです。この考え方はデータベースの正規化と似ています。つまり、一つの事実は一つの場所にだけ記録するということです。これを守らないと、データの矛盾が発生するリスクがあります。
例えば、応募データに応募者名が記録されているとします。この場合、「応募データ」と「応募者データ」は観測単位が異なります。異なる観測単位のデータを同じテーブルに混在させると、矛盾が発生する可能性があります。具体的には、応募者NOが同じであれば応募者名も同じであるべきですが、同じテーブルに格納していると、このルールを守らず、矛盾した情報を登録できてしまうのです。

このような矛盾を防ぐためには、下図のように「応募データ」と「応募者データ」をそれぞれ別のテーブルに分ける必要があります。これが「各観測単位は1つのテーブル」という原則が示す内容です。
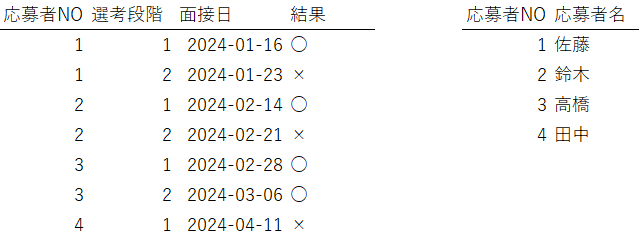
さらに、同じタイプの観測単位に関するデータが複数のテーブルやファイルに分散している場合もあります。たとえば、応募者ごとに別の表に記録されていたり、面接月ごとにファイルが分かれているケースです。このような場合、同じ観測単位に関するデータは一つのテーブルにまとめる必要があります。これも「各観測単位は1つのテーブル」という原則に含まれます。
まとめ:データを正しく整えることの重要性
データの構造を正しく整えておくと、データ分析作業を効率よく行うことができます。特に、横持ちデータから縦持ちデータへの変換は、分析作業を大幅に簡略化します。整然データの概念を理解し、データを適切に整えることで、ミスを減らし、効率的なデータ処理が可能となります。
データ分析の際には、まずデータの構造を見直し、整然データを意識した整理を行うことが成功への近道です。
データ分析に興味のある方募集中!
コグラフ株式会社データアナリティクス事業部ではPythonやSQLの研修を行った後、実務に着手します。
研修内容の充実はもちろん、経験者に相談できる環境が備わっています。
このようにコグラフの研修には、実務を想定し着実にスキルアップを目指す環境があります。
興味がある方は、下記リンクよりお問い合わせください。

X(Twitter)もやってます!
コグラフデータ事業部ではX(Twitter)でも情報を発信しています。
データ分析に興味がある、データアナリストになりたい人など、ぜひフォローお願いします!
📢Wantedly新掲載!
— アラリコ@コグラフ株式会社 | データ事業部 (@CographData) July 14, 2023
「データに興味がある」
「データに携わる仕事がしたい」
そこのあなた!
私たちと一緒にデータ分析しませんか?
IT業界未経験の方も大歓迎です☺️#エンジニア転職 #データ分析 #駆け出しエンジニアと繋がりたいhttps://t.co/S9o7VSjGRt