webスクレイピングを知識0から始めて習得するま⑥【XPathとCSSセレクタの基本】

2022/1/22【6日目】
XPathとCSSセレクタのちがい
いずれかをマスターをすれば大丈夫。両方マスターする必要はない。CSSセレクタの方が理解しやすいという声もあるがどちらもあまり変わらない。XPathの方が柔軟に要素を指定できる。
私は、柔軟に要素を指定できると後々困ることも少ないと思うのでXPathで進めていこうと思います。
XPathとは
XML Path Languageの略。XML形式の文書から要素を抽出するための簡易言語。htmlにも使える。
柔軟に要素を指定できるが、その分理解することは多くなる。BeautifulsoupではXPathで指定できない。
XPathとは、XPathの基本的な書き方
HTMLの階層構造
html- head- title- テキスト
|- body- p
|- p
HTMLタグの属性
<a class(属性)="book"(属性値) id="link1">テスト</a>
aタグの中にはclass属性として属性値bookが含まれている。idもid属性として属性値link1が含まれている。
XPathの基本的な書き方
ロケーションパス:/ノードテスト/ノードテスト/ノードテスト

このサイトでXPathをためすことができる。
Inputの入力欄でhtmlコードを入力しておく。XPath欄に条件を入力。Resultに結果が出る。

Chromeでhtmlを表示して、Inputにコピペ。
XPathの基本
htmlのルートからXPathを書く場合はスラッシュを使って記述する。
html-head-titleと辿ってタイトル要素を指定する場合は、
/html/head/title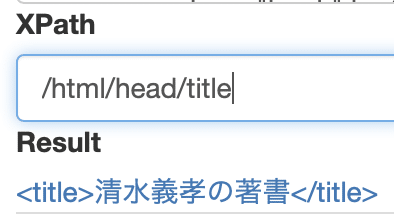
このように書くと、タイトルタグとその中に含まれるテキストが表示されてた。要素に含まれるテキストを表示したい場合は、
/html/head/title/text()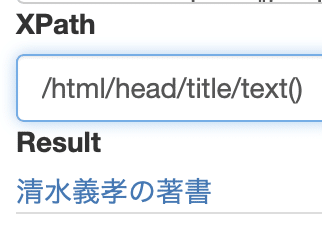
text()で、テキストのみ取得できる。
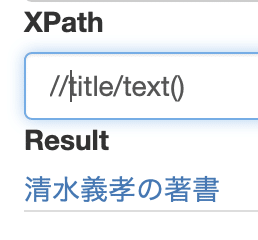
// ダブルスラッシュを使うと、途中のパスを省略できる。

a要素は複数あるので、複数表示される。その中で1つに絞り込みたい場合は、親要素は省略せずに記述するか、属性と合わせて指定する必要がある。
XPathによる属性の取得

a要素はid属性としてlink1、link2、link3を持つものそれぞれある。

これで、id属性がlink1を持つa要素だけを指定できる。

任意の属性を指定する場合は*を使う。

属性値を表示したい場合は、@を使う。href属性の値として格納されているURLを表示できた。

URLについている10桁の商品コードで絞り込むときは、containsを使う。

not(contains())を使うと、含まない要素を指定できる。

and contains(@)でid属性の条件を追加。

orを使うと、商品コードとid属性で指定できる。

stars-withで前方一致検索ができる。httpsのURLは除かれた。

ends-withで後方一致検索ができる。この方法はXPath2.0以降に対応していてChrome等では使えないから参考までに。

containsは、テキストに含まれる文字列も検索できる。大文字小文字の別もあるので注意。
xpathでのリストの要素の取得

このサンプルhtmlを使っていきます。

これでulが抽出できた。

これでliが抽出できた。


[ ]に番号を入力するか、[position()=番号]でリストの要素を取得できる。

positionであれば複数要素の取得もできる。[ ]だとできない。

最後の要素の指定はlast()でもできるけど、最初の要素は1。

position()>1で2以降の要素取得。
XPathでの親・先祖・兄弟・子・子孫要素の取得
/軸::ノードテスト[述語]/ノードテスト/軸::ノードテスト
でロケーションパスを指定する。

XPathによる前方にある要素の取得


id属性が"link2"のa要素を自分要素とする。

親要素pの中身が取得できた。

親要素がわからない場合は、node()を使うと同じように取得できる。

先祖要素を取得するにはancestor()を使う。自分自身は含まれない。

ancestor-or-selfとすることで自分自身も含まれる。

自分自身の前にある先祖要素を除いた全ての要素の取得には、precedingを使う。

自身より前にある全ての兄弟要素の取得には、preceding-siblingを使う。
XPathによる後方にある要素の取得

自分自身をclass属性がresent booksのp要素とする。

子要素の取得にはchildを使う。子要素がわからない場合は親と同じように、node()を使う。

後続の全ての要素を取得するにはfollowingを使う。

後続の兄弟要素取得にはfollowing-siblingを使う。

後続にある全ての子孫要素を取得するには、descendantを使う。子と孫も取得できた。自分自身も含めるにはdescendant-or-selfを使う。

自分自身を取得するにはselfを使うが、通常は省略されて、
//p[@class="recent books"] と記述する。

自分自身の属性の値を取得。
xpathの指定方法は以上。このブログではxpathを用いていくので、CSSセレクタの指定方法については割愛します。
「Codes&Co.」「コーズコー」