lightGBMのクロスバリデーション サンプルコード

試行錯誤してなんとかmaeのクロスバリデーションができるようになったので残しておきます。
import numpy as np
import pandas as pd
import lightgbm as lgb
from sklearn.model_selection import KFold
from sklearn.metrics import mean_absolute_error
pd.set_option('display.max_columns', None)
trdf=pd.read_csv('train.csv')
X=trdf[['TimeToReply','MaximumAccommodates']]
X.replace({'within an hour':0,
'within a few hours':1,'within a day':2,
'a few days or more':3},inplace=True)
y=trdf['Price']
X=np.array(X)
y=np.array(y)FOLD = 5
NUM_ROUND = 100
VERBOSE_EVAL = -1
params = {
'objective': 'regression',
'verbose': -1,
}
valid_scores = []
models = []
kf = KFold(n_splits=FOLD, shuffle=True, random_state=42)
for fold, (train_indices, valid_indices) in enumerate(kf.split(X)):
X_train, X_valid = X[train_indices], X[valid_indices]
y_train, y_valid = y[train_indices], y[valid_indices]
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_valid, y_valid)
model = lgb.train(
params,
lgb_train,
valid_sets=lgb_eval,
num_boost_round=NUM_ROUND,
verbose_eval=VERBOSE_EVAL
)
y_valid_pred = model.predict(X_valid)
score = mean_absolute_error(y_valid, y_valid_pred)
print(f'fold {fold} MAE: {score}')
valid_scores.append(score)
models.append(model)
cv_score = np.mean(valid_scores)
print(f'CV score: {cv_score}')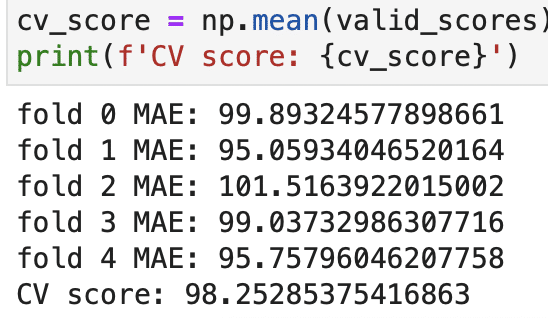
:こんな感じで出てくるようになりました。2変数しか使ってないけど一番高くて101、一番低くて95だから6%ぐらいのブレが出てくると言うこと。
# データの特徴量をnp.ndarray型にしておく必要がある。のと、目的変数は1次元のarrayじゃないといけない。y=[['Price']]とすると2次元になってしまうから、y=['Price']と大括弧は1つで括る。y.shape()で確認できる。