webスクレイピングを知識0から始めて習得するまで⑤【Scrapyの基本】

2022/1/9 【2日目】
データ分析コンペである程度pythonのコードとかpandasとか使うのに慣れたので、ずっとやりたかったwebスクレイピングを1から勉強していきます。
webスクレイピングができるようになったらやりたいことは、webからTiborの履歴をとってきて、チャートを表示できるサイトを作りたい。データ分析で勉強したpandasとかmatplotも使うことになると思うから丁度いいとおもってる。
Scrapyのコマンド
scrape bench
benchコマンドは、簡単なベンチマークテストを実行するのに利用します。
2020年M1モデルのMacbook Airでこのくらい。1分間に4000ページぐらいをクロールできる。
clearこれでターミナルの内容をリセットできる。
基本的にはVS Codeではなく、ターミナルを使っていくらしい。
プロジェクトの作成
# option+command+Mで最前面のウインドウを最小化できる。最小化するとDockに入る。
mkdir projectsls![]()
これでprojectsディレクトリを作成して、カレントディレクトリの中身を確認できる。
cd projectsprojectsでディレクトリに移動して
scrapy startproject qiita


qiitaプロジェクトに必要なディレクトリ、ファイルが自動的に作成される。次のSpiderの作成に必要なコマンドの説明も表示された。
scrape.cfg(コンフィグファイル)はSpiderの作成やディプロイに必要な設定ファイル。

items.pyをVS Codeで開く。スクレイピングで取得したデータを格納する入れ物のようなもの。アイテムと呼ばれている。フィールドはこのように提示していて、あらかじめ提示していないと格納ができない。
2022/1/13【3日目】
Spiderの作成
ScrapyでのSpiderの作成
cd qiitaqiitaディレクトリに移動
scrapy genspider -l
scrapyで利用できるコマンドを確認する。
basic:ベーシックのテンプレート
crawl:通常のWEBサイトをクロールする。ルールを指定してリンクを辿っていくテンプレート
csvfeedとxmlfeedは滅多に使わない。
scrapy genspider qiita_trend_1d qiita.com
spiderファイルを作成する。サイトURLのhttps://と最後の/は不要。

VScodeで開く。ベーシックなテンプレートとして、Spiderクラスの多くの機能を引き継いだQiitaTrend1dSpiderができている。中身は上書きするコードを書くだけで多くのことを実現できる。
allowed_domains:指定しなくても良い属性だけど、思わぬドメインをスクレイピングしないように指定しておく。リスト型だから複数指定できる。
start_urls:スクレイピングを始めるページ
メソッドとしてparseメソッドが設定されている。ブラウザとwebサーバーとの間でHTTP通信をするが、ブラウザの役割をするのがScrapy。サーバーへリクエストを送ってサーバーからのresponseをparseメソッドでキャッチする。parseの中にXpathやcssセレクタのコードをオーバーライド(上書き)を用いて必要な情報だけを抽出する。
Safari開発者ツールの使い方

Safari→環境設定→詳細 から「メニューバーに開発メニューを表示」にチェックを入れる必要がある。
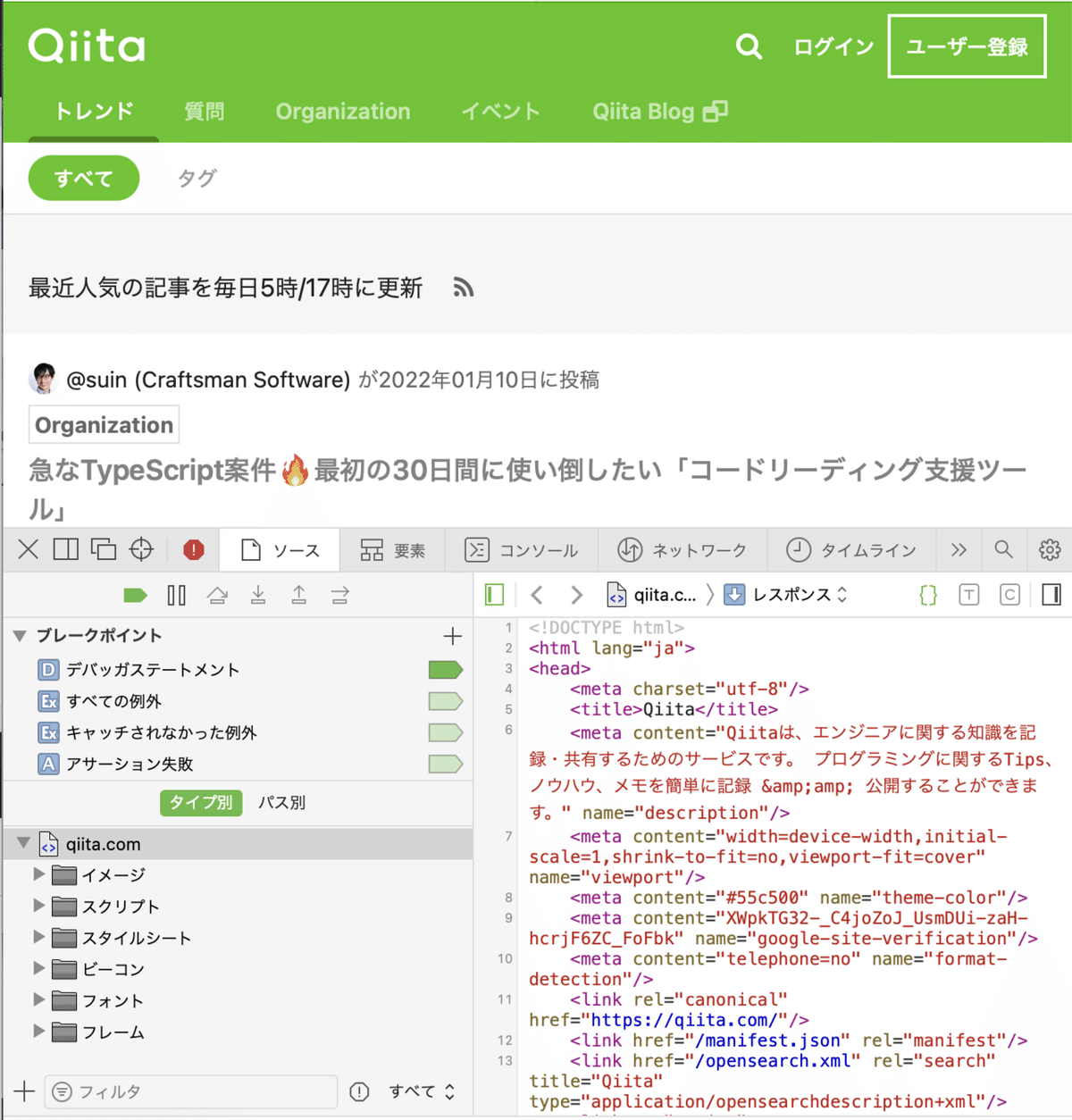
option+command+Uで、ページの要素を表示できる。
やっぱり講座でChrome使ってるからChrome でやることにする。

option+command+Iで開発者ツールを開ける。
option+command+Cもしくは↑をクリックで検査用モードに切り替わって、カーソルの位置のhtmlがハイライトされる。


htmlを見たいところにカーソルを合わせて検証からでも開ける。サイト上部タブのOrganizationsを取得していく。

href属性にorganizationsaという値が格納されているa要素の配下のテキストにこのOrganizationsという文字が格納されている。

command+fで検索ボックスを表示。

//a[@href="/organizations"]//text()
このコードでXPathでOrganizationsを取得できた。

a[href="/organizations"]::text
このコードでCSSセレクタで取得できる。配下の要素を取得するには擬似要素として::textを入力するが、開発ツールでは取得できない。コーディングの時に使える。

次に、記事のタイトルを取得するために、//section/h2まで記述すると30件ヒットし、全てがタイトルであることを確認する。
//section/h2//text()これで記事名をXPathで取得できる。
section > h2::textこれでは開発ツールでは記事名をCSSセレクタで取得できるけど、ターミナルでは取得できない。>は子要素を表す。
h2 > a::text
これでターミナルでも記事名をCSSセレクタで取得できる。
//h2/a/@href
これでURLをXPathで取得できる。
h2 > a::attr(href)これでURLをCSSセレクタで取得できる。a要素のhref属性を取得するには::attr(属性名)で取得できる。これらの擬似要素は非標準だから開発者ツールでは確認できずコーディングの際に追記する。
これで目的の要素を取得できるようになった。
2022/1/15【4日目】
Scrapy Shellの使い方
ShellはXPathやCSSセレクタを試すのに使う。Shellで確認する方法。慣れてくれば不要な作業。
![]()
ipythonが必要。
scrapy shell https://qiita.com/![]()
これでシェルを起動できる。
fetch('https://qiita.com/')
scrape shell でURLを指定せずに後からfetchコマンドを使ってURLを指定してもデータを取得することもできる。GETは送信したリクエストの種類を示す。qiitaのURLにリクエストを送信している。


サーバーから情報を取得したいのでGETを使ってる。200なのでリクエストに成功している。
category=response.xpath('//a[@href="/organizations"]//text()')![]()
取得してきたデータを格納する変数をcategoryとする。xpathの引数にOrganizationsのXPathを入れる。引数は” ”か’ ’で囲う必要があるが、XPathに””が使われているなら’’じゃないといけない。
selectorオブジェクトという形で表示された。ここに取得したデータが格納されている。htmlの特定の部分を選択するためselectorと呼ばれている。xpathのプロパティには先ほどのXPathが、dataプロパティには取得した要素がそれぞれ格納されている。
category=response.xpath('//a[@href="/organizations"]//text()').get()
.get()メソッドを使うと、webサイトよりOrganizationの文字をテキストで所得できる。
category=response.css('a[href="/organizations"]::text')
cssを入力しても、Scrapyの中でxpathに変換され実行される。
category=response.css('a[href="/organizations"]::text').get()
.get()も同様に使える。
title=response.xpath('//section/h2//text()')
title=response.xpath('//section/h2//text()').getall()
複数の要素を取得する場合は、.getall()を使う。リスト型で取得できる。CSSも同様。
title=response.xpath('//h2/a//text()').getall()
こっちのXPathでも同じデータが得られる。
urls=response.xpath('//h2/a/@href').getall()
urlも同様に、XPathで取得できる。
urls=response.css('h2 > a::attr(href)').getall()
exit()これで、シェルから抜けられる。
慣れてくれば、このScrapy Shellでの確認作業を省略してSpiderで直接コーディングしても良い。
2022/1/16【5日目】
Spiderのコーディングと実行

アナコンダナビゲーターで仮想環境を選び、VS Codeを実行。


settings.pyを開く。
FEED_EXPORT_ENCODING='utf-8'空いているスペース15行目に上記コードを挿入。出力ファイルの文字コードを指定する。指定しないと文字化けすることがある。

command+K+UでDOWNLOAD_DELAY=3のコメントアウトを解除する。1つのページをダウンロードしてから次のページをダウンロードするまでの間隔を秒で指定する。サイトに負荷をかけないように。


禁止されているページにアクセスしないよう、ROBOTSTXT_OBEYはTRUEのままにしておく。

WEBサイトから取得するデータを日本語にするためScrapyから送信するリクエストのヘッダーの言語設定をenからjaに変更する。DEFAULT_REQUEST_HEADERSのコメントアウトを解除する。command+K+Cで解除。真ん中の行はコメントアウトする。
全ての変更が終わったのでファイルをcommand+Sで保存する。

qiita_trend_1dayのspiderを開く。spiderのコーディングをしていく。
def parse(self, response):
category=response.xpath('//a[@href="/organizations"]//text()').get()
titles=response.xpath('//section/h2//text()').getall()
urls=response.xpath('//h2/a/@href').getall()
# category=response.css('a[href="/organizations"]::text').get()
# titles=response.css('section>h2::text').getall()
# urls=response.css('h2 > a::attr(href)').getall()parseメソッドにScrapy Shellで確認したxpathを記入していく。今回はcssはコメントアウト。
yield{
'category':category,
'titles':titles,
'urls':urls
}
戻り値はyieldを使って辞書で記述して出力する。キーを設定して値をxpathで定義した変数とする。returnではそこで処理が完全にストップしてしまうが、yieldなら一旦停止するだけなので値を返した後に処理は継続する。
Scrapyではこのようにほんの数行でコーディンができる。
![]()
ターミナルで、qiitaディレクトリに移動。lsコマンドで中身を見て、scrapy.cfg(コンフィグファイル)があることを確認する。spiderの実行にあたってはscrapy.cfgと同じレベルにいる必要がある。
scrapy crawl qiita_trend_1d
spiderはqiitaのrobot.txtとqiitaのサイト自身にリクエストを送ってレスポンスのステータスとして200成功が返ってきた。categoryにはOrganizationと、titlesには記事名が取得できている。
scrapy crawl qiita_trend_1d -o data.json
ターミナルで確認するだけでなく、josonファイルで出力もできる。Shift+option+Fでjsonファイルのフォーマットで表示できる。jsonファイルでは、キーと値の組み合わせでデータが保存されている。

command+JでVScode上でターミナルを開ける。qiitaディレクトリに移動。同様にSpiderを実行できる。Scrapy Shellも起動できる。
(参考)PythonでのJSONファイルの読み込み
data.jsonと同じレベルにpythonファイルを作成する。
import json
with open('data.json',encoding='utf-8') as f:
qiita_data=json.load(f)
print(qiita_data)with openとすることで自動的に閉じてくれる。オープンしたファイルオブジェクトにfと名付けることで、今後fと打つだけで扱えるようになる。json.load(f)で帆見込んだものをqiita_dataに格納。
python read_json.py
ターミナルでpythonファイルを実行することで、格納されているデータがリスト型で表示される。
print(qiita_data[0])
辞書型で表示するには、インデックスに[0]を指定してprintする。
with open('data.json',encoding='utf-8') as f:
qiita_data=json.load(f)
# print(qiita_data[0])
titles=qiita_data[0]['titles']
print(titles)
urls=qiita_data[0]['urls']
print(urls)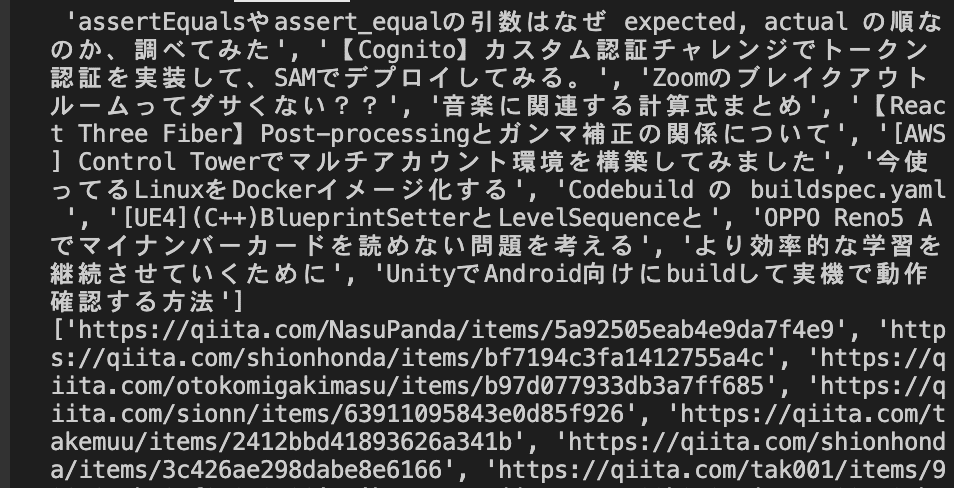
これで、titlesとurlsだけを取得できる。
for title,url in zip(titles,urls):
print(title,url)
zipを使うことで、タイトルとURLをペアで表示できた。
「Codes&Co.」「コーズコー」