
気候データマネゴト解析:準備編

記事の概要
自然豊かな北海道。
この記事は北海道の夏季(6,7,8月)の気温の変動傾向がどんな要因によって支配されているかを主成分分析を利用して確認してみます。(その準備編!)
参考論文はこちら
利用データとツール
DL_Link:気象庁過去のデータ検索
場所:気象庁の北海道道内22地点の観測所
項目:気温(℃)
年数:1970~2020の51年間の6,7,8月
地点:北海道内22地点
解析ツール:Jupyter notebook(Python)
以下の地点において、気温データの解析を行いました。

ダウンロードしたデータ(data.csv)をエクセル上で簡単に整形し(笑)、pandasに読み込んで処理をしていきます。
Jupyter notebookへのcsvファイルの読み込み
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv("data.csv", encoding = "shift-jis")
datacsvの情報を変数dataに格納します。このときに、当該csvファイルの文字コードがshift-jisであることに注意して読み込みます。結果は以下のようになります。

カラム名の指定
dataを表で示すと、1,2列目のカラム名が未指定になっています。ここにそれぞれ年と月を指定して更に出力して確認します。
data=data.rename(columns={data.columns[0]: 'Year'})
data=data.rename(columns={data.columns[1]: 'Month'})
data.head()
data.info()などを実行し、データの概形やnullがないかなどを確認します。
各地の年ごとの平均気温を算出し、テーブルを作成
今回は各地の夏季の平均気温の傾向を調べたいので、各年における6,7,8月の平均気温を算出し、新たなデータフレームを形成します。
まずはset関数を使ってダブりのない年代リストを取得します。
Year = list(set(data["Year"]))
print(Year)![]()
これを利用して、各年6,7,8月平均値を算出し、データフレームに挿入していく処理を行います。
df = pd.DataFrame() #データフレームを生成
#年ごとに平均値を算出し、dfに挿入する処理
for i in range(len(Year)):
a = list(data[data["Year"] == Year[i]].mean())
a = pd.DataFrame(a)
df2 = pd.DataFrame(a.T) #aは列ベクトルなので、行ベクトルに転置する
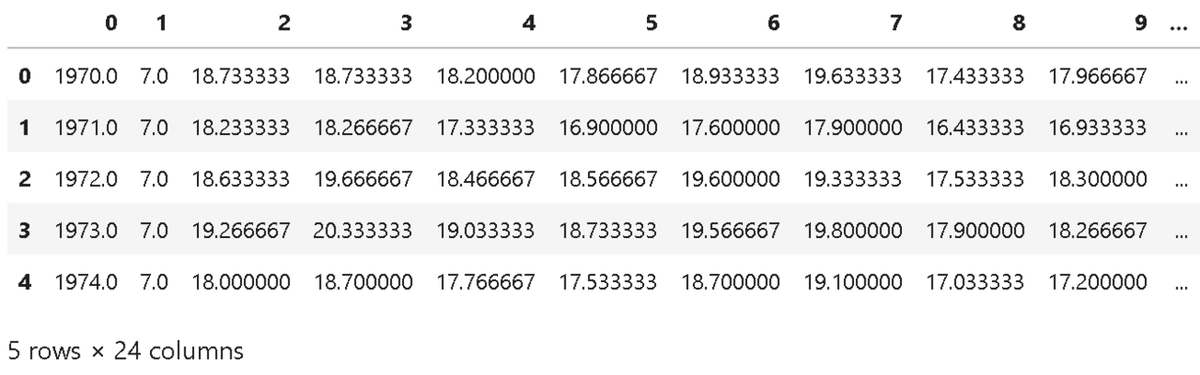
df=df.append(df2,ignore_index=True) #appendでdfに各年ごとに挿入するdf.head()で上から5行を確認すると以下のようになります。
dfカラムの24列はYear, Month, 各地点(22地点)で構成されています。
分析用のデータフレームXを作成
カラム名を設定します。dfのカラムをdataから引っ張ってきて代入します。
c = list(data.columns)
df.columns = c実際に主成分分析に利用するデータフレームXを作成します。
#dfの3列目以降の全ての行をXに代入
X = df.iloc[:,2:]
X.head()
Xは行成分に年代情報、列成分に地点情報を含むデータフレームを示しています。
ここからXを用いて主成分分析を実行します。
今回はデータを整形するところまでということで、今回はここまでとします。
続きはこちら!
この記事が気に入ったらサポートをしてみませんか?