iris_datasetで主成分分析①

おなじみのiris(アヤメ)のデータセットを使って、主成分分析をしてみました。今回はscikit-learnのPCAクラスを用いる方針で、コードを示しながら進めていきます。
解析のための実行環境はgoogle colaboratoryを用いました。
データの読み込み
#python
import os
import pandas as pd
s = os.path.join('https://archive.ics.uci.edu','ml','machine-learning-databases','iris','iris.data')
print('URL:',s)
#csv形式でiris_datasetを読み込む
iris = pd.read_csv(s, header=None, encoding='utf-8')
#irisはpandasのdataframe形式
#読み込んだirisの先頭5行を表示させる
iris.head()出力は以下のようになります。
irisのカラム(列のこと)名が0,1,2,3,4となっておりわかりにくので、カラム名の設定をします。

#カラム名の設定
iris.columns = ["Sepal_Length", "Sepal_Width", "Petal_Length", "Petal_Width", "Species"]
iris.head()
#sepal length ガクの長さ
#sepal width ガクの幅
#petal length 花弁の長さ
#petal width 花弁の幅
カラム名が設定されました。次に読み込んだirisの概形や簡単な情報をチェックします。
データセットの概形を把握
# #→(出力結果)とします。
#irisの行列数の確認
iris.shape()
# →(150, 5)150行✕5列のデータ形式であることがわかりました。
次に基本統計量を見てみます。
#簡単なデータの基本統計量
iris.describe()
#count:データ数
#mean:平均値
#std:標準偏差
#min:最小値
#25%:
#50%:
#75%:
#max:最大値
欠損値を確認してみます。
iris.isnull().sum()
#出力結果↓
#Sepal_Length 0
#Sepal_Width 0
#Petal_Length 0
#Petal_Width 0
#Species 0
#dtype: int64null(データなし)の状態が全てのカラムにおいて0なので、欠損値なしのデータセットであることがわかりました。
それでは次に、カラム間での関係性をseabornという可視化モジュール?を使って確認しておきます。
各変数の関係を可視化
#seabornのインポート
import seaborn as sns
%matplotlib inline
#各カラムの散布図を網羅的に図示します
#hue="Species"はSpeciesのカラムの値で場合分けを指示しています
#seabornを使った図示
sns.pairplot(iris, hue="Species", palette="husl")
iris-setosa(赤)は他の種と比べて萼も花弁の形質も大きく異なることがわかり、分離が良いことがわかります。一方、iris-versicolor(緑)とiris-virginica(青)の分離はやや曖昧になっています。
主成分分析の準備(データの分割と標準化)
現在4次元のこちらのデータを主成分分析(PCA)によって2次元に次元削減して分離が良くなるか試してみましょう。
今回はsklearnのtrain_test_splitで訓練データセット(データの70%を使用)とテストデータセット(データの30%を使用)に分けて(この記事では必要ではないが)Xに1~4列目をyに5列目をそれぞれ格納します。
その後、各カラムの分散が1となるように標準化を行います。
#データの分割!
from sklearn.model_selection import train_test_split
X, y = iris.iloc[:, :4].values, iris.iloc[:, 4].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, stratify=y, random_state=0)
#平均と標準偏差を用いて標準化
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train_std = sc.fit_transform(X_train)
X_test_std = sc.transform(X_test)これで、標準化されたX_train_stdを得ることができます。
ちなみにX_train_stdは105行4列の行列になります。
※主成分分析は教師なし学習に分類されるので、必ずしも訓練データとテストデータに分ける必要はありません。今後教師ありを紹介する時にスムーズなのであえて分けています。
主成分分析の実行と可視化
sklearnのPCAモジュールを利用するとここからとても簡潔です。
#PCAをインポート
from sklearn.decomposition import PCA
#n_componentsは処理後の次元を指定する。今回は2次元に削減する。
pca = PCA(n_components=2)
#第一、第二主成分までを計算
X_train_pca = pca.fit_transform(X_train_std)
#ここから第一第二主成分をプロット。
#マーカの色リストの作成
colors = ["r", "b", "g"]
#マーカのシンボルリストの作成
markers = ["s", "x", "o"]
#クラスラベル・点の色・点の種類の組み合わせからなるリストを生成してプロット
for l, c, m in zip(np.unique(y_train), colors, markers):
plt.scatter(X_train_pca[y_train==l, 0], X_train_pca[y_train==l, 1], c=c, label=l, marker=m)
#ラベルを指定
plt.xlabel("PC 1")
plt.ylabel("PC 2")
#ラベル位置を指定
plt.legend(loc="upper right")
plt.tight_layout()
#出力
plt.show()結果は以下のようになります。iris-setosaが第一主成分で大きく分離されていますね。上の散布図と比較してみると、花の形質に関する項目の寄与が大きいことがわかります。

寄与率の説明は別記事で紹介することにしますので、取り急ぎグラフを示します。

このグラフの横軸は各種成分を表し、縦軸は各主成分ごとの固有値の分散説明率(variance explained ratio)になります。(それと累積値を重ねたものになります)
グラフから1つ目の主成分で分散の7割近くを占めていることがわかる。また、2つめと合わせると、分散の9割を占める事がわかります。
まとめ
もともとirisの形質のデータセットは4次元でしたが、主成分分析を行い、2次元に削減し、図示してみました。
感想としては、4次元くらいだと有用性があんまり伝わらないかもしれませんね。元ネタの教科書ではワインのデータセットでの実装を紹介しています。ワインは13次元→2次元に削減するのでこちらのほうが有用性がありますよね。。
今回の参考書はこちらです!
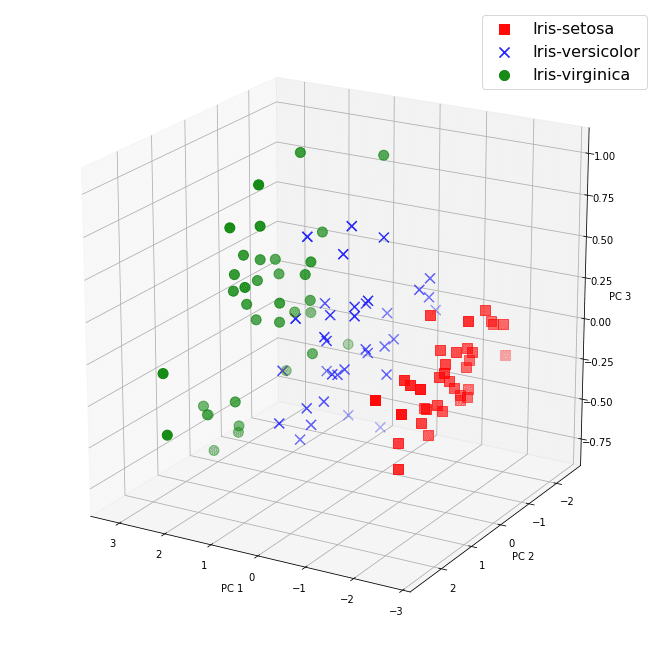
おまけ:あまり意味ありませんが、3次元へのプロットはこんな感じで可能です。
from sklearn.decomposition import PCA
pca = PCA(n_components=3)
X_train_pca = pca.fit_transform(X_train_std)
from mpl_toolkits.mplot3d import Axes3D
#figureを追加
fig = plt.figure(figsize = (9,9))
ax = Axes3D(fig)
colors = ["r", "b", "g"]
markers = ["s", "x", "o"]
#クラスラベル・点の色・点の種類の組み合わせからなるリストを生成してプロット
for l, c, m in zip(np.unique(y_train), colors, markers):
ax.scatter(X_train_pca[y_train==l, 0], X_train_pca[y_train==l, 1], X_train_pca[y_train==l, 2], c=c, label=l, marker=m, s = 100)
ax.set_xlabel("PC 1")
ax.set_ylabel("PC 2")
ax.set_zlabel("PC 3")
ax.legend(loc="upper right", fontsize=16)
ax.view_init(elev=20, azim=120)
#plt.tight_layout()
plt.show()