
【超初心者】データ処理環境の構築体験【Python × Google Colaboratory】

はじめに
現代はデータ社会といっても過言ではありません。
購買、決済、ヘルスケア・・・など、いたるところにデータが存在しています。

仕事や趣味でも、データを扱うことの大切さや必要性を感じて、
データ処理やデータ分析をやってみよう!
と思った方は多いのではないでしょうか?
ただ、ネット記事や本は読んだけど、
なかなか手を動かすところに至らないということも多いのではないでしょうか?
この記事では、Google Colaboratory(Colab)を利用して、
爆速でデータ処理環境を構築をする方法をお伝えします。
環境の構築の簡単さに重点を置いていますので、
この記事で紹介する処理は単純な内容になります。
もちろん、今回構築した環境でより高度な処理も実行可能ですので、
応用性は高いと思います。
Google Colaboratory(Colab)とは
Colabに対する説明なので、とりあえずデータ処理環境を構築したい方は、読み飛ばしてもらってOKです。
Colabは、Webブラウザ上でPythonというプログラミング言語を記述、実行できるツールになります。
Googleが提供しています。

Webブラウザ上で完結するので、
自分のPCに実行環境などのインストールが不要であり、
プログラミングおよびデータ分析をするまでの
セットアップがとても簡単です。
また、Colab上のドキュメントは静的なウェブページではなく、
Colab ノートブックという、コードを記述して実行できるインタラクティブな実行環境です。
言い換えると、
セルと呼ばれるコードのまとまり単位で
実行およびアウトプットを確認しながら、
データ分析を進めることができます。
通常のプログラミング環境だと、
プログラムを実行したら、
最初のインプットに対して、最後のアウトプットだけが出力されます。
データ分析では、
今扱っているデータはどんな状態?ということを把握するために、
途中のデータを確認したいことがありますので、
セル単位の実行機能は大変有用です。
事前に用意するもの
今回、事前に用意するものは、この2つだけです。
Webブラウザ(Google Chrome, Edge, Firefoxなど)
Googleアカウント
このnoteの記事を見ているのであれば、Webブラウザはインストールされているはずですので、残りはGoogleアカウントだけです。
Googleアカウントも、Gmailの利用などで、すでにお持ちの方も多いのではないでしょうか。
もし、アカウントをお持ちでなければ、下記の記事を参考にGoogleアカウントの作成をお願いします。
Colabノートの作成手順
Google Colaboratoryを使えるようにするには、下記のリンクを開いてください。
下図のような画面が表示されますので、
続いて、
左上のファイル > ノートブックを開くをクリックしてください(下図の赤枠)
ここで、Googleアカウントにログインしてない場合は、ログインを求められますので、ログインをお願いします。

次に、下図のような画面になると思います。
左上の「Untitled0.ipynb」と書かれている部分をクリックし、
保存するファイル名を入力してください。
ファイル名なので、好きな名前で問題ありません。
ex) データ分析体験シート
これでデータ処理基盤を構築することができました。

データ処理体験
データの読み込みと表示
環境構築だけだと
データ処理を
どのようにできるのか
イメージが湧かないと思いますので、
簡単なデータ処理体験できるコードを紹介します。
1個目のセルのところに、以下のコードをコピペしてください。
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
data.head()そして、セルの左側にある▶ボタンを押して下さい(下図参照)。
そうすると、下図のようになります。
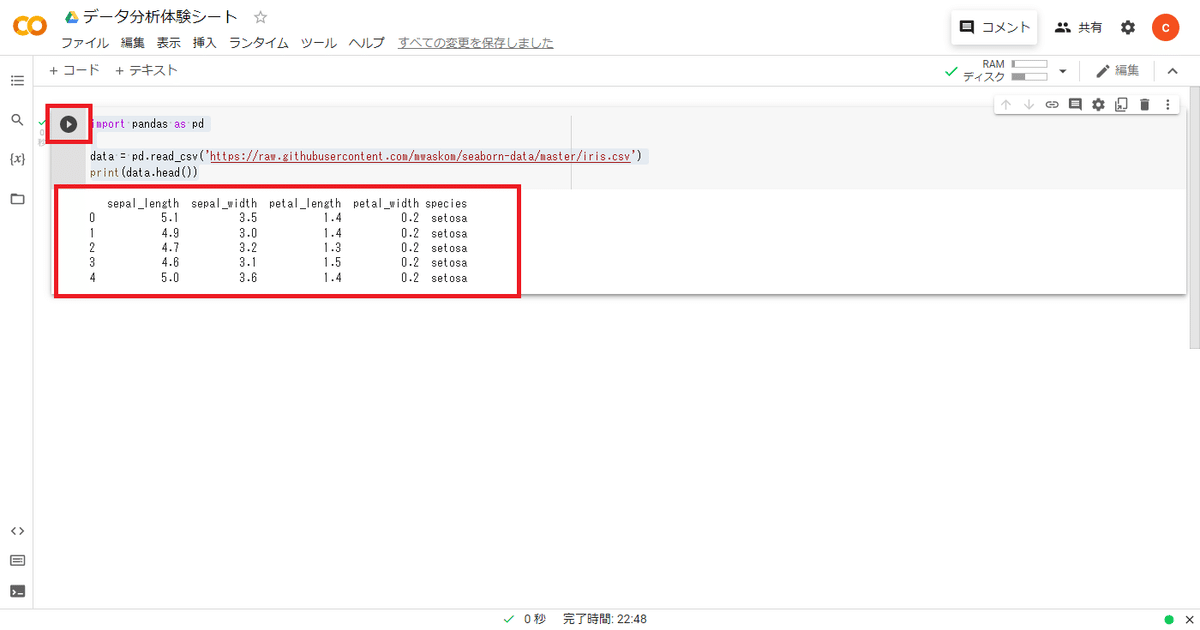
コードが実行され、表が出てきたと思います。
この作業、データ処理の第一歩を踏み出しました。
データ処理の中で、基本操作である
「データを読み込む」
ことと、
「データを表示する(最初の5行)」
ことをを実行できました。
なお、読み込んだデータはIrisデータセットと呼ばれるものです。
Irisデータセットとは150個体分のIris(アヤメ)の
『ガクの長さ(sepal length)』『ガクの幅(sepal width)』
『花弁の長さ(Petal length)』『花弁の幅(petal width)』の4つの特徴と
それに対応する『花の種類(species)』がまとめられたデータセットです。
このようにデータを読み込んでしまえば、
分析したり、
可視化したりと
データ処理でできることの可能性が一気に広がります。
データの可視化
データ処理のコードを追加するのは、
先ほどと同じセルでも良いのですが、
下図のあたりにマウスカーソルを持っていくと、
コードというボタンが現れます。
これを押すと、
セルがもう一つ増えます。
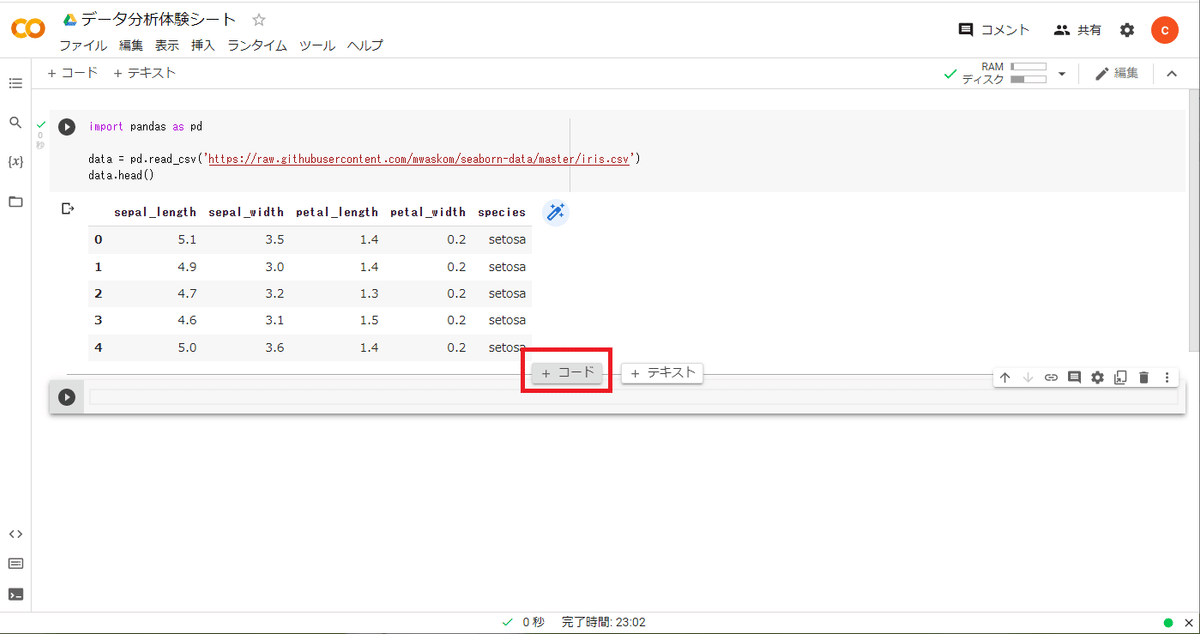
この増えたセルに以下のコードをコピペして、実行すると、
import matplotlib.pyplot as plt
plt.hist(data["petal_length"])下図のようなグラフを描画できます。
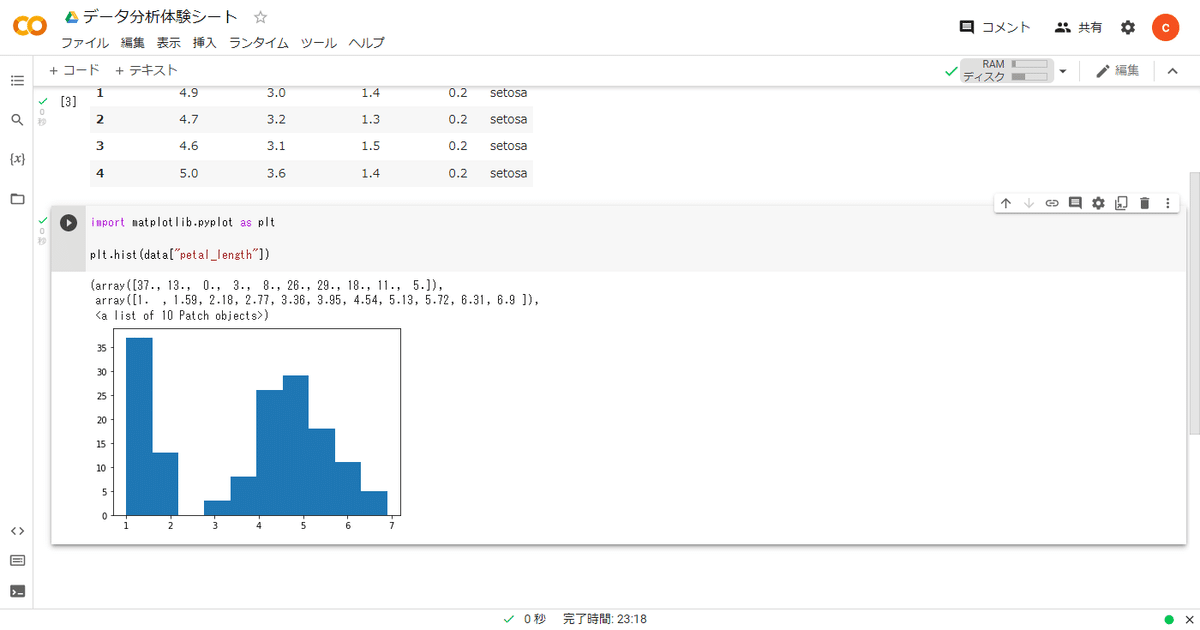
これは、irisデータセットのアヤメの花弁の長さのヒストグラムになります。
2つの山があることから、
性質の異なる2種類のアヤメがありそうなことが推測できます。
終わりに
Google Colaboratory(Colab)を使って、
データ処理環境を構築する方法をお伝えしました。
Colabは、GPU処理もできるので、
統計処理だけでなく、機械学習の計算もさせることができます。
この環境の応用性は高いです。
ご質問やコメントなどありましたら、
ちんちらのtwitterにDMをお願いします。
https://twitter.com/chinchilla10x
また、この記事の内容に限らず、
プログラミングに関してレクチャーのご依頼などありましたら、
ココナラからご連絡ください。
いいなと思ったら応援しよう!
