
ChatGPTに関数を作ってもらって再利用・ワードクラウド編(大城)

こんばんは、ChatGPT部、部長の大城です。今日から来週木曜日の午前中までちょっと夏休みなので、締め切りの近い本を書きつつ息抜きにChatGPTに色々と思いつきの作業をしてもらっています。
今日はnoteableプラグインでワードクラウドをChatGPTに作ってもらう実験をしていたのですが、そういえば「関数」の形にしたら、他のみなさんも再利用しやすいのでは、と思ったのでそちらの実験です。
実験の前に:そもそものワードクラウドとは
テキストを出現個数等に応じて、いい感じに可視化してくれるのがワードクラウドです。今回は以下のような画像を作ってもらいました。
・元記事
・ワードクラウド化後

色々と工夫の余地はありますが、ひとまず「こういう単語・話題がありそう」というのを視覚的に把握する場合には結構便利かと思います。
実験その1:ひとまず文字化けを回避してワードクラウドを作成してもらう
今回はWebPilotプラグインで特定の記事の検索、noteableプラグインでワードクラウドのコーディングと実行を依頼しました。
ただ、最初、何も考えずに依頼すると「日本語のワードが文字化け」するという状態でして、そちらを一旦回避したコードを作成してもらいました。
・文字化けの例
こんな感じですね。箱ばっかり・・。

・解決方法
一応、(依頼の)試行錯誤のスレッドは最後に載せますが、こんな感じでいけました。(ファイルパス指定しているので、別環境だと再現しないかも・・?) -> Google Fontsからダウンロードして設置、という技でいけました。pip installで行けると楽なんですけどね・・

実験その2:肝心な、関数のコード出力
さて、今日の実験は「出力されたコードをnoteに記載し、それを別のChatGPTのスレッドが参照して、再利用が可能かどうか」です。ということで今回簡易的に作ってもらったコードを出力してもらいました。それがこちら。
・必要なライブラリのインポート
import requests
from bs4 import BeautifulSoup
from janome.tokenizer import Tokenizer
from wordcloud import WordCloud
import matplotlib.pyplot as plt
・ワードクラウド生成関数
def generate_wordcloud_from_url(url):
# URLからHTMLを取得
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# 記事のタイトルを取得
titles = [title.text for title in soup.find_all('a', class_='o-timeline__link')]
text = ' '.join(titles)
# テキストのトークン化
t = Tokenizer()
tokens = t.tokenize(text)
words = [token.surface for token in tokens if token.part_of_speech.split(',')[0] in ['名詞']]
words_str = ' '.join(words)
# ワードクラウドの設定
wordcloud = WordCloud(
font_path='/usr/share/fonts/truetype/fonts-japanese-gothic.ttf',
background_color='white',
width=800,
height=800,
stopwords={'の', 'に', 'は', 'を', 'た', 'が', 'で', 'て', 'と', 'し', 'れ', 'さ', 'ある', 'いる', 'な', 'ん', 'こと', 'これ', 'さん', 'して', 'ない', 'なり', 'なっ', 'など', 'でも', 'から', 'よう'}
).generate(words_str)
# ワードクラウドの表示
plt.figure(figsize=(10, 10))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
・参考:ChatGPTとの途中までのやり取りログ(長いので、特に見なくて大丈夫ですー)
追記:テキストを読み込ませるように変更したver
URL指定だとスクレイピングに失敗することがありましたので、「ChatGPTにテキストを解釈させて、関数にはテキストを渡してワードクラウド化」という処理にしてもらいました。時間はかかりますが、おそらくコチラの方が汎用的。
実験その3:この記事のコードをWebPilotで読ませて再現するか実験
ということで、実験です。一度、その2までの記事を公開してChatGPTに読み込ませる指示をしたいと思います。(WebPilotプラグインとNoteableプラグインを利用)

・別のアカウント&スレッドでChatGPT-4に依頼
大城:
こんばんは。下記の記事の関数を参考にして、以下のWeb記事のワードクラウド作成をお願いできますか?記事のランキング20位までを対象にしてもらいたいです。 なお、記事からのテキスト抽出はChatGPTの能力を使ってお願いします(参照先のテキスト構造が変化しうるため)。
・補足事項1:
なお、新たなnoteableの環境の場合各種ライブラリはインポートされていませんので、pip install等をお願いします。
・補足事項2:
Google Fontsから日本語のフォントをダウンロードし(例:Noto Sans CJK)、一時的にnoteableが利用可能なファイルパスにフォントファイルを設置し、日本語の文字化けを解消してください。
・補足事項3:参照先の関数はURLを読み込む形ですが、汎用性が欠けるがめ、関数へのテキスト入力を受け付ける形に変更してください。なお、テキストのスクレイピングはChatGPTの機能を用いて実現してください。
・ワードクラウドの関数のある記事
ChatGPTに関数を作ってもらって再利用・ワードクラウド編(大城)
https://note.com/chatgpt_nobdata/n/n15c028dd6af5
・ワードクラウド化する記事のURL
【世界】の「ChatGPT」ニュースまとめ20230807(42記事)
https://note.com/chatgpt_nobdata/n/n1a67d3f05f15
関数が中途半端なので補足事項だらけですが、ひとまずご愛嬌・・。
・一度エラー:ライブラリの未インポート(プロンプトに反映済み)
この辺りもプロンプトの工夫で回避できるかもですが、ライブラリのインポートは毎回明示してあげた方がよさそうです。

・文字フォントエラー(プロンプトに反映済み)
日本語のフォントが文字化けしてたので、「Google Fontsからzipファイルをダウンロード・回答して必要なパスに配置」をしてもらいました。noteable、pipインストール以外もいけるんか・・ (賢い)

・実行結果(途中省略)
こんな感じになりました。
なお、先ほどの関数のURL指定だと構造によってHTMLのパースに失敗したりするので、ChatGPTでスクレイピングしてテキストを関数に渡す形にしてもらいました(工夫すればプログラムからでも行けそうですが、取り急ぎ)。
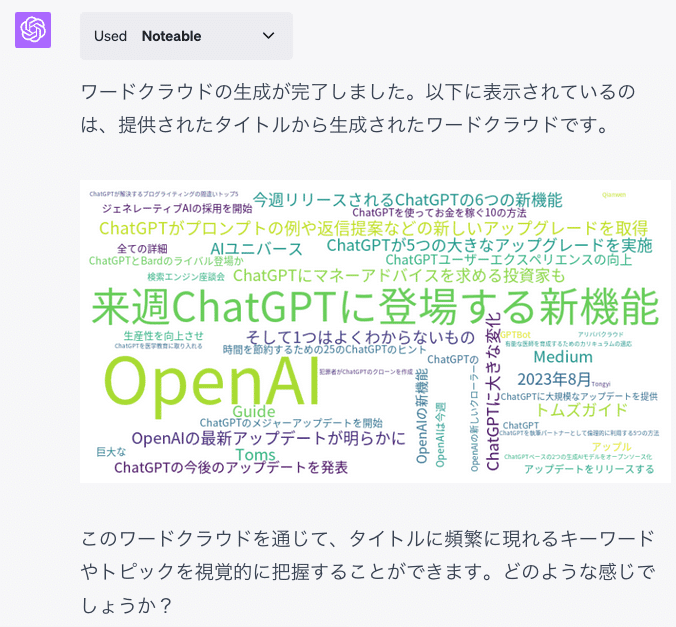
途中で関数をいじってしまったのでoutputの形式が違う気もしますが、まぁ一旦良しとしましょう。厳密にやる場合は関数を固めてgithub等に置いておく感じになるかな、とも思います。
補足:試行錯誤のやりとり
こちらもログ置いておきます。
その他:noteableの無料版のカーネルは同時に3つまで
以下のようなエラーをChatGPTが報告してくることがあります。無料版は3つのカーネルまでしか同時実行できないようなので、その場合は他のアクティブなカーネルを落とす指示をすると良いと思います。
(もしくは月額$30払って有料プランにするかですが、記事的にはなるべく無料で行きたいところ・・ 実用上はよく使うのなら課金しても良いかもですね)


ということで、今日は関数を作ったページをChatGPTに読み込ませて、テキストマイニングのコードを再利用させる方法についてでした。
それではみなさんもどうぞ良いChatGPTライフを・・!(大城)
