snipping toolのOCR技術を使って看板の文字を取り込んでみた。

snipping toolのOCR技術を使って看板の文字を取り込んでみた。 - つみかさね
https://3yokohama.hatenablog.jp/entry/2023/12/23/184549
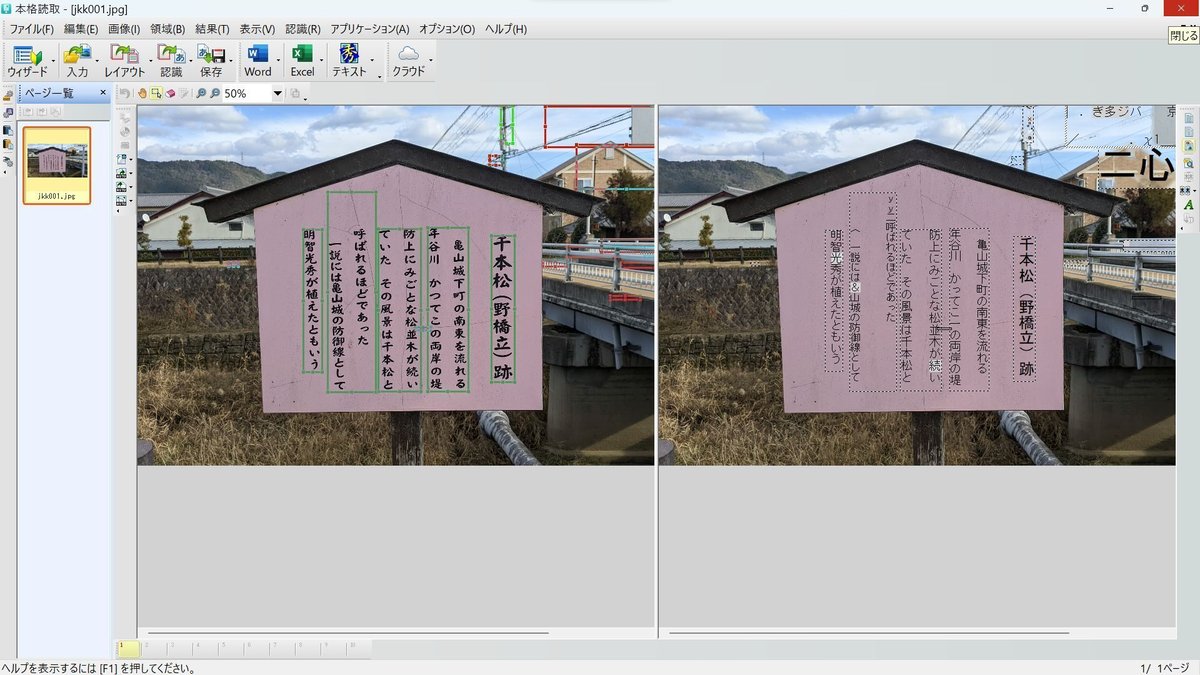
snipping toolのOCR技術を使って、写真にある看板を取り込んで文字を抽出すると縦書きの場合、左側から読み込んでくれる。縦書きに日本語は右端から読んでいくのが普通の読み方ですね。これではちょっと都合が悪いので、下記の文章の上下反対に1つずつ並べなおさないといけない。この程度の長さならば手動でやっても何とかなるが、もっと文章量の多い場合は困ってしまう。そこでChatgptで文章の整形、行順の入れ替えをやることにした。OCRの機能で反対にできないか?左右反対にして逆の文字(反転しt文字)を出しておいて、1行ごとに切り取って貼り付けて、右端から順番に文章を並べておいてOCR技術を使ってテキスト文字を抽出した。これは意外とうまくいった。ただ手間がかかる。したがって読みは左側からのままChatgptで整形する方法がベストかなと思います。
OCRは「Optical Character Recognition」の略で、日本語では「光学文字認識(こうがくもじにんしき)」と読みます。OCR技術は、印刷物や手書きのテキストを画像からコンピュータが読み取り、テキストデータに変換するための技術です。snipping toolのOCR技術はなかなか優れものです。本格読取り、読み取り革命はチャンと右端から読んでくれます。ただ読み取り精度がいまいちです。それに比べてsnipping toolのOCR技術は精度も良いです。
取り込んだ文章
明智光秀が植えたともいう
一説には亀山城の防御線として
呼ばれるほどであった
ていた その風景は干本松と
防上にみごとな松並木が続い
年谷川 かつてこの両岸の堤
亀山城下町の南東を流れる
「次の文章を一番下の行から順番に上の行に並べ替えてください。行を全部ひっくり返して」
千本松(野橋立)跡
「千本松(野橋立)跡」。
「亀山城下町の南東を流れる」。
「年谷川 かつてこの両岸の堤」。
「防上にみごとな松並木が続い」。
「ていた その風景は干本松と」。
「呼ばれるほどであった」。
「一説には亀山城の防御線として」。
「明智光秀が植えたともいう」。
プロンプト「次の文章の間隔を詰めてください。「」は不要です。削除してください。」
最終的には下記のように並び替えられた。
千本松(野橋立)跡。
亀山城下町の南東を流れる。
年谷川 かつてこの両岸の堤。
防上にみごとな松並木が続い。
ていた その風景は干本松と。
呼ばれるほどであった。
一説には亀山城の防御線として。
明智光秀が植えたともいう。
写真の行を入れ替えたものをOCRで取り込むと。1行ずつ文字を切り取って貼り付けていく。
すると下記の通りチャンと読み込んでくれました。これは手間暇がかかります。
千本松(野橋立)跡
亀山城下町の南東を流れる
年谷川 かつてこの両岸の堤
防上にみごとな松並木が続い
ていた その風景は千本松と
呼ばれるほどであった
一説には亀山城の防御線として
明智光秀が植えたともいう