
【GPT−4o超え】遂にオープンソース史上最強LLM「Llama 3.1」が公開《概要・使い方・今後の展望を徹底解説》

みなさん、こんにちは。
チャエンです!(自己紹介はこちら)
遂にオープンソース史上最強AI「Llama 3.1」が公開されました!🔥いよいよオープンLLM時代の幕開け第一歩になるかもしれないですね。
最新のクローズドモデルGPT-4oやClaude 3.5を凌駕するレベルです。コンテキストウインドが128Kで、多言語でのサポートや3つのモデルが用意されています。
【⚡️速報:遂にオープンソース史上最強AI「Llama 3.1」が公開】
— チャエン | 重要AIニュースを毎日発信⚡️ (@masahirochaen) July 23, 2024
405Bなら最新のクローズドモデルGPT-4o、Claude 3.5を凌駕。オープンLLM時代の幕開けか。
・コンテキストウインド:128K
・多言語サポート
・3モデル: 405B、改良版8B & 70B… pic.twitter.com/Wnh2JwyU0a
Llama 3.1 の概要や他のモデルとの比較、活用方法を紹介します。オープンソースなので、企業でのローカルLLM導入案件が増えそうですね。
社内に導入するための情報収集として、ぜひ最後までご覧ください📝
1.Llama 3.1 の概要

Llama 3.1は、2024年7月にリリースされたLlama(Large Language Model Meta AI)最新モデルです。405Bパラメータを持つ世界最大のオープンソースの言語モデルで、2023年12月までの公開されているソースから収集された約15兆トークンのテキストデータを元にトレーニングされています。
Starting today, open source is leading the way. Introducing Llama 3.1: Our most capable models yet.
— AI at Meta (@AIatMeta) July 23, 2024
Today we’re releasing a collection of new Llama 3.1 models including our long awaited 405B. These models deliver improved reasoning capabilities, a larger 128K token context… pic.twitter.com/1iKpBJuReD
AWS・NVIDIA・Databricks・Groq・Dell・Azure・Google Cloud・Snowflakeなどを含む25社以上のパートナーが、初日からサービスを提供する準備が整っていると発表しています。

1-1 Llamaシリーズについて
Meta AIから2023年2月に、初めてリリースされました。Llamaシリーズは、OpenAIのGPTシリーズに対抗するために設計された大規模な言語モデルファミリーです。初期のLlamaモデルは研究コミュニティ向けに非商業ライセンスで提供されましたが、後に商業利用も一部許可されるようになりました。
LLaMA 1: 7B, 13B, 33B, 65Bパラメータ
LLaMA 2: 7B, 13B, 70Bパラメータ
LLaMA 3: 8B, 70B, 405Bパラメータ
過去にLlama3を解説しています👇
どのように変わったのかぜひご確認ください。
Metaは、AIの倫理的利用に積極的に取り組んでおり、モデルの透明性やバイアスの軽減、誤情報の防止、モデルのトレーニングデータの品質管理や、人間によるアノテーションの使用などに努めています。Llama 3.1もこれらの取り組みを通じて、AIの倫理的利用と技術的進歩の両立を目指しています。
1-2 Llama 3.1の利用方法について
Llama 3.1はオープンソースとして公開されており、研究者や開発者が自由に利用できるようになっています。またMeta Llama 3 Community Licenseの下で提供されているため、商業利用も一部許可されています。
モデルは、以下のMetaの公式サイトやHugging Faceでダウンロード可能です。詳しい使い方は後述します。
1-3Llama 3.1の特徴
Llama 3.1 は、複数の言語での商業および研究用に設計されています。指示調整済みテキストのみのモデルはアシスタントのようなチャット用に意図されており、事前学習モデルはさまざまな自然言語生成タスクに適応可能です。
パラメータ数: 8B, 70B, 405B
Llama 3.1 ファミリーのモデルは、事前学習データのみを対象としたトークン数を示します。すべてのモデルバージョンは、推論のスケーラビリティを向上させるためにグループ化されたクエリアテンション(GQA)を使用しています。
メモリ要件とKVキャッシュメモリ要件 (FP16、128kトークン)の概算はこちら。

トレーニングデータ: 約15兆トークンのテキストデータ
公開されているソースから収集された約15兆トークンのテキストデータで事前トレーニングされました。
データの品質を確保するために、ヒューリスティックフィルターやNSFWフィルター、セマンティックデデュプリケーション、テキスト分類器が使用された他、10万件の人間によるアノテーションが含まれています。
トレーニングの後、教師あり微調整 (SFT)、拒否サンプリング、直接的な好みの最適化を含む複数の調整を経て、チャットモデルが改良されました。
多言語対応: 英語、ドイツ語、フランス語、イタリア語、ポルトガル語、ヒンディー語、スペイン語、タイ語(*日本語はありません…)
コンテキスト長: 128Kトークン(Llama 3の16倍)
高精度なツール使用: コーディングアシスタントや対話エージェントとしての利用
モデルの量子化: 16ビットから8ビットへの量子化により、計算リソースの効率化
他のモデルの改善
合成データ生成:現実的で多様な訓練データを人工的に作り出すことができ、他のAIモデルの学習に必要なデータの質と量を向上させることが可能です。
知識蒸留:Llama 3.1の持つ知識や能力を、より小さな、または特化したモデルに転移させることができ、特定のタスクに最適化された効率的なモデルを作成できます。
1-4 性能と能力
一般知識や長文生成・多言語翻訳・コーディング・数学・ツール使用・コンテキスト理解・推論能力において優れています。
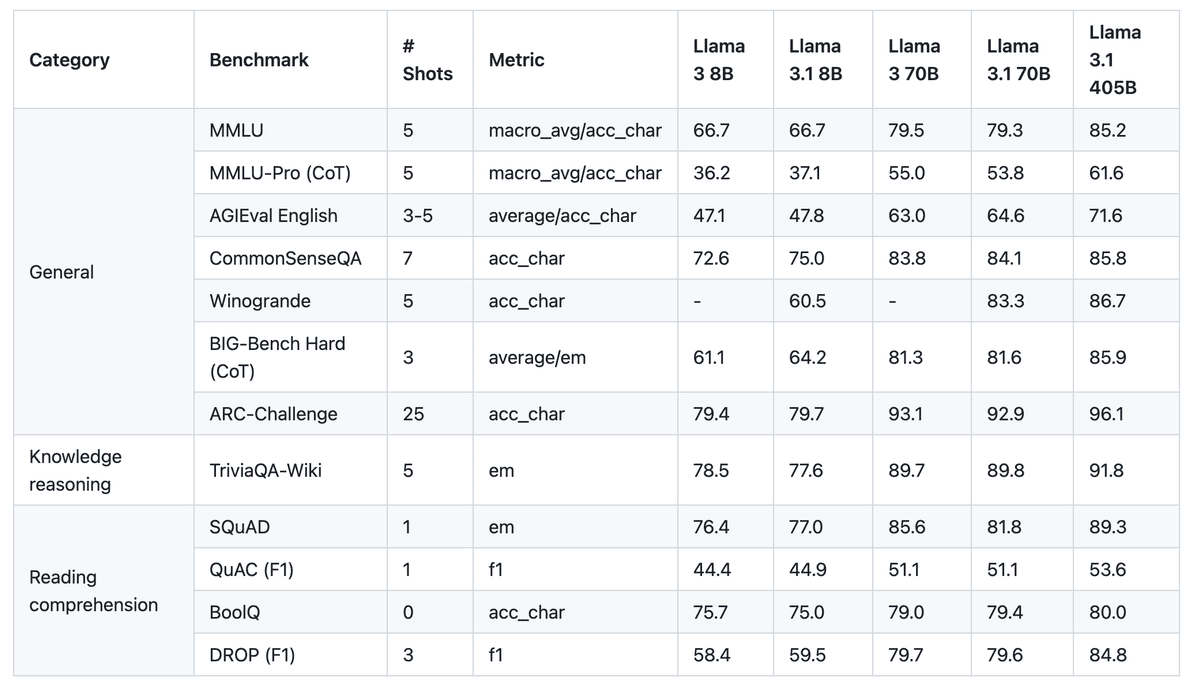
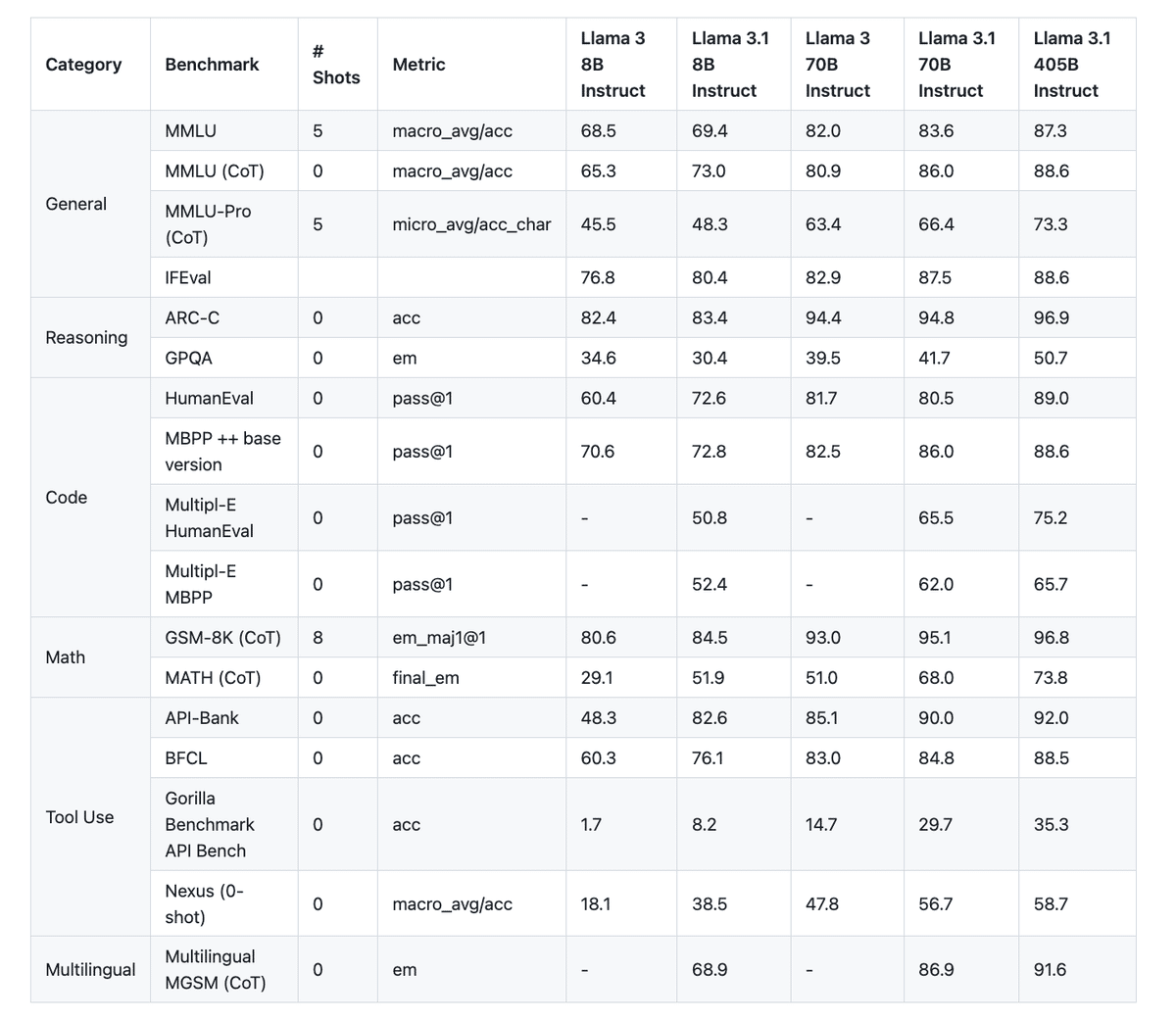

1-5 2つの追加機能
①ツール呼び出し対応
外部ツールの呼び出し機能をサポートしており、モデルの応答能力が大幅に向上しています。以下のツールが組み込まれていて、ユーザーのクエリに応じて必要な情報や計算結果を提供します。
Brave Search: ウェブ検索機能を利用して、リアルタイムの情報取得が可能
Wolfram Alpha: 数学的な問題解決やデータ解析に利用できるツール
Code Interpreter: コードの解釈や実行を行うためのツール
②カスタムツール呼び出し
開発者は、独自のAPIや関数をモデルに統合することができるようになりました。複雑な処理や特定のビジネスロジックを外部ツールを通じて実行することができるようになりました。
2.他のモデルとの比較
Llama 3.1を、競合モデルと実世界のシナリオで比較する広範な人間による評価を実施したと発表しています。150以上のベンチマークデータセットで評価され、GPT-4やClaude 3.5 Sonnetなどの競合モデルと比較しても優れた性能を示しました。
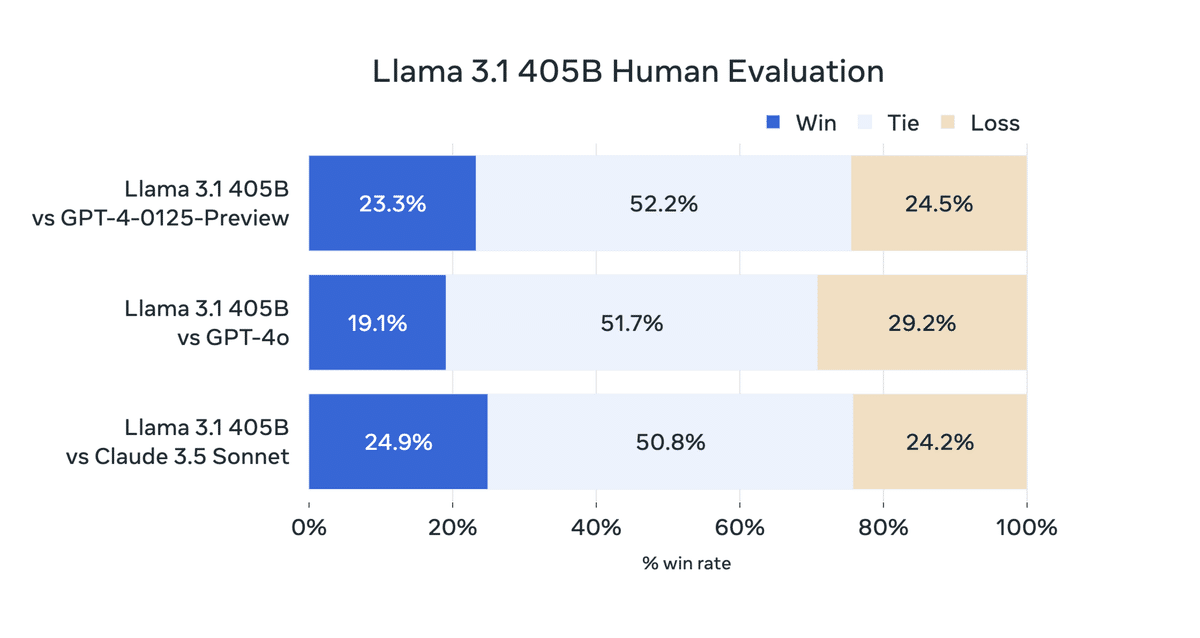
さらに、小型モデルも同様のパラメータ数を持つクローズドおよびオープンモデルと競争力があります。
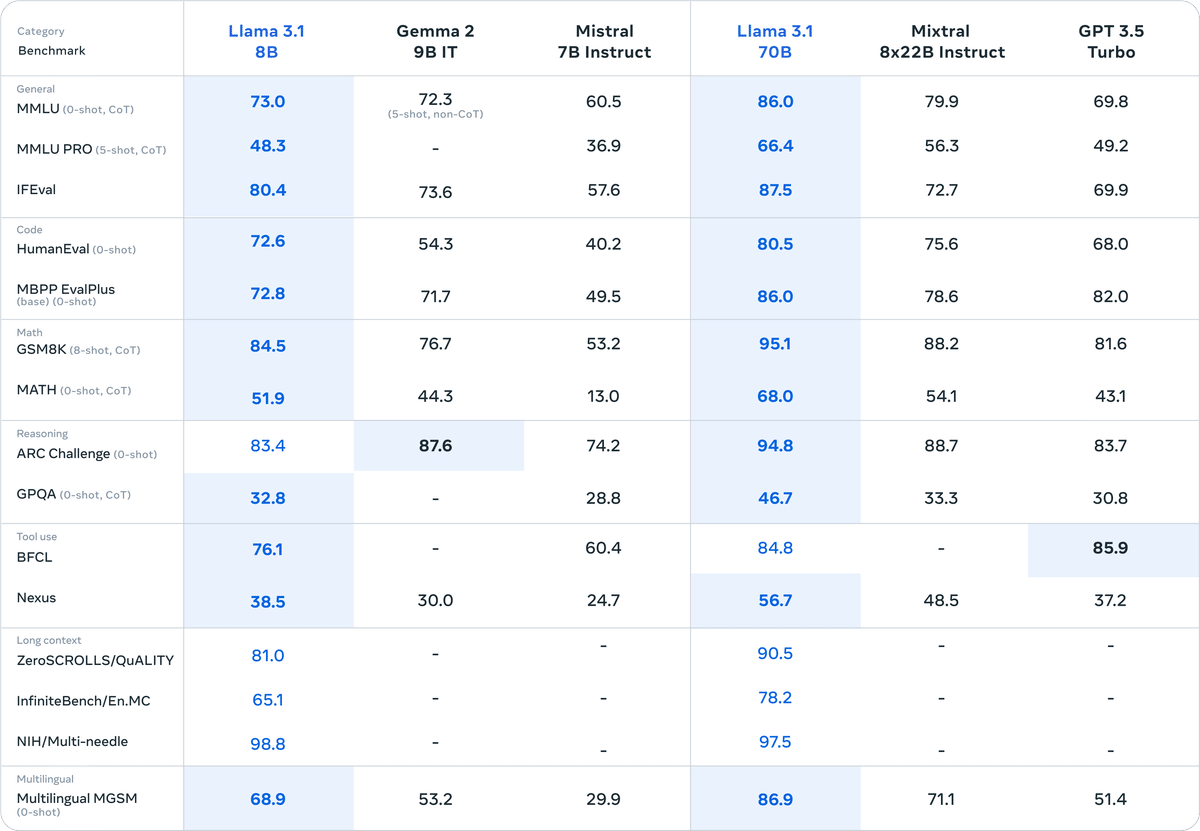
独自にファインチューニングテストを実施した結果を見てもかなりいいパフォーマンスを出していることがわかります。

2-1 日本語でLLMテストをしてみた
日本語ではサポートされていないので、仕方ないことですが調べ物に使う場合はPerplexityの方がいいかもしれないですね。
①過去の人物について聞いてみた
外務省の部分を始め、間違えの情報が混ざっています。

②史実を聞いてみた
史実なので、そもそも間違いがあるかもしれないが日付が旧暦だったりと少し間違いがある模様。

3.Llama 3.1の活用方法
ChatGPTやClaudeと違い、Llamaはオープンソースなので様々なツールから使うことができます。今回は、5つのツールそれぞれの使い方を紹介します。
405Bは重くて、中々動かないのがネックです。また、日本語対応してなくてもプロンプトでなんとか生成できる印象です。
こちらの5つの方法で誰でも利用できるので、試してみてください!!
ここから先は
¥ 700
Amazonギフトカード5,000円分が当たる
この記事が気に入ったらチップで応援してみませんか?