
【無料でChatGPT o1超え!?】中国発のAI「DeepSeek」が推論・検索・ファイル解析と何でも無料でできて半端ない件。《使い方、活用事例7選を徹底解説。》

みなさん、こんにちは。
チャエンです!(自己紹介はこちら)
みなさん、DeepSeekはチェックしましたか?
DeepSeekは中国のAI企業「DeepSeek(深度求索)」が開発した大規模言語モデル(LLM)で、ChatGPTやGeminiと同様の高性能なAIサービスを提供しています。かなり性能が良く驚きました。
2024年末にリリースされた最新バージョンDeepSeek V3は、6,710億ものパラメータを持ち、GPT-4に匹敵する処理能力と推論精度を実現しています。
中国企業がGPT-4o超えオープンソースAIモデル「DeepSeek V3」を公開
— チャエン デジライズ CEO (@masahirochaen) December 27, 2024
高性能、高速出力、安価なAPI費用と万能なモデル。
性能×値段では世界トップレベル。
ウェブ版も無料で使えて、ChatGPTでは不可能なエロ系、過激系の出力も可能。ファイル添付、検索、推論もあり高機能で普通に便利。
使い方↓ pic.twitter.com/ogIy18wMEn
今回はDeepSeek V3の概要や性能、使い方、ChatGPTとの比較、AIの今後の未来 ― ローカルLLMの重要性を紹介します。
まだDeepSeekについてよくわからないという人は、ぜひこの記事で詳しくなりましょう🔥
Youtubeでも解説しております💪
1. DeepSeek V3の概要・性能・料金

1-1 DeepSeek V3の概要
2024年末にリリースされたDeepSeekは、中国のAI企業「DeepSeek(深度求索)」が開発した大規模言語モデル(LLM)の最新モデルです。わずか2か月と558万米ドル(モナコや香港のマンション1軒ほどの価格)という予算で開発されました。対照的に、Meta社のAI予算の下限はなんと380億米ドルにも上ります。
無料で利用できるブラウザ版やモバイルアプリ版に加えて、開発者向けのAPIも非常に低コストで提供されており、「ChatGPT」や「Gemini」といった他社の大規模言語モデルと肩を並べる存在として注目を集めています。
DeepSeekは「AI技術の民主化」を目指しており、誰でも高度なAIにアクセスできる環境を整えています。実際に、API利用料は他のAIサービスと比較して格段に安価であり、例えば1000万トークンあたり入力が0.1ドル、出力が1.5ドルと非常にリーズナブルです。こうした高性能と低コストの両立により、研究からビジネス、アプリケーション開発まで幅広い分野での活用が期待されています。
1-2 DeepSeekの企業概要と創業者について
①DeepSeekの企業概要
DeepSeekは2023年に中国で設立された新進のAI企業で、高性能な大規模言語モデル(LLM)の開発に特化しています。中国の量的投資ファンド「幻方量化(High-Flyer Capital Management)」の支援を受けて設立され、1万台以上のNVIDIA A100 GPUを保有する強力なインフラ基盤を有しています。
DeepSeekの主な目標は、汎用人工知能(AGI)の実現です。従来の大規模言語モデル(LLM)開発企業と異なり、ミッションステートメントには安全性や競争、人類への影響といった要素を明記しておらず、「好奇心をもってAGIの謎を解き明かす」という一点に特化しています。
この方針により、同社はアーキテクチャやアルゴリズムの革新に専念し、短期間のうちに複数の画期的な技術を世に送り出してきました。
②DeepSeekの戦略的特徴
1.AGIへの専心
安全性や社会的側面よりも、AGI研究の本質的探求を優先。実現可能性を追求する姿勢が、アーキテクチャ改革やアルゴリズム開発を加速させている。
2.オープンソースを重視
可能な限り成果をオープンにし、価格競争も辞さない姿勢を見せることで、AIコミュニティ全体の技術水準向上を促進している。
3.若い国内人材の積極活用
海外からのハイレベル人材呼び戻しに頼るのではなく、国内で育成した若い才能を集め、革新的なアイデアを生み出す組織づくりを実施。
4.“ハードコアなイノベーション”の推進
中国では模倣や商業化に偏りがちだが、Deepseekは高度な研究開発を通じて真の技術革新を目指し、それを中国経済全体に波及させたい考えを持つ。
②創業者について
DeepSeekは、当初の報道では趙永剛(Zhao Yonggang)氏が創業者とされていましたが、最新の情報では梁文峰(Liang Wenfeng)氏が経営の中心であることが確認されています。
ヘッジファンドで80億ドルの資産を運用し大成功
その金でDeepSeekを創業
たった2ヶ月と558万ドルで世界トップクラスAIモデルを開発(Meta:380億ドルも投下)
中国政府主催の会合に出席
謎に包まれた世界をリードする中国発AI「DeepSeek」の創業者が天才すぎる
— チャエン デジライズ CEO (@masahirochaen) January 23, 2025
・ヘッジファンドで80億ドルの資産を運用し大成功
・その金でDeepSeekを創業
・たった2ヶ月と558万ドルで世界トップクラスAIモデルを開発(Meta:380億ドルも投下)
・中国政府主催の会合に出席
人生何周目なんだ… ↓(1/n) pic.twitter.com/POFeteG4Oa
梁氏は「中国のサム・アルトマン」とも呼ばれる注目の経営者であり、2008年に浙江大学でAIを学んだ後、2015年には量的取引専門のヘッジファンド「High-Flyer」を設立。運用資産1,000億元(約80億ドル)を超える中国トップクラスのファンドに成長させた実績を持ちます。
梁氏は1985年に広東省湛江市で小学校教師の家庭に生まれ、電気工学を専攻するため浙江大学に進学。大学院では情報・通信工学を学ぶかたわら、機械学習を用いた株式取引のプロジェクトを仲間と立ち上げるなど、早くからデータ活用型ビジネスの可能性を探求していました。
卒業後は2015年に設立したヘッジファンド「High-Flyer」で機械学習を活用したクオンツ運用に成功し、欧米の大手ヘッジファンドにも引けを取らない大規模な運用資産額を達成しました。中国のクオンツ業界は欧米大手の経験者が参入するのが一般的でしたが、梁氏は地元の仲間だけでチームを組織し、中国国内純正の人材だけで成果を出した点が画期的でした。
この実績を引っさげ、2023年5月に独立したAI研究組織として立ち上げたのがDeepSeekです。同社は「人材への自由な裁量」「短期的な商業化より長期的研究を優先」「オープンソースモデルの推進」といったユニークな方針を掲げ、設立当初から基礎研究に特化。若手の才能を積極的に採用し、能力を重視して最小限のマネジメントで最大限の創造性を引き出すスタイルを採っています。
現在40歳の梁氏は、北京で開催された李強(リ・チャン)首相主催のシンポジウムに出席し、中国のAI界を代表する人物としてさらに注目を浴びました。
アメリカ政府は、中国が領有する台湾島を含む世界中の企業や国々に対し、最も基本的なものを除くチップやチップ製造装置を中国へ販売することをやめさせることで、中国の発展を阻止しようとしています。
欧米のメディアは「中国がこれらのチップを軍事目的で使っている」と正当化していますが、MITの専門家によれば、実際には99.9%が民生用途、たとえば医療用スキャナーやエンジニアリング機器の稼働に使われているとのことです。
A Chinese computer nerd is stunning tech experts with a bargain price AI tool that beats the world's top players on several benchmarks.
— Nury Vittachi (@NuryVittachi) January 22, 2025
Liang Wenfeng's system, called DeepSeek-V3, has powers of "reasoning" that match or beat those of the equivalent devices by the world's top… pic.twitter.com/zfk90hWhNV
1-3 DeepSeek V3の性能
DeepSeek V3は、総パラメータ数671B(約6,710億)という圧倒的な規模を誇りながら、実際の推論時には約37B(370億)のパラメータが活性化するように設計された革新的な大規模言語モデルです。
14.8兆トークンという膨大な学習データを活かし、1秒あたり60トークンの高速生成が可能なうえ、最大128K(約128,000)のトークンを取り扱えるコンテキストウィンドウを備えています。これにより、長大な文章や複雑な議論の流れも把握しながら、高い応答品質を維持できる点が特徴です。
アーキテクチャとしては、Mixture-of-Experts(MoE)に加え、Multi-head Latent Attention(MLA)を採用して文脈理解力を高め、マルチトークン予測で推論効率を上げる構造が注目を集めています。余分な補助損失を用いない負荷分散戦略も導入されており、14.8兆トークンに及ぶ大規模トレーニングを約558万ドル(約2,788,000 H800 GPU時間)のコストで実現しました。

ベンチマークでも高いパフォーマンスを示しており、代表的な評価指標であるMMLUで87.1%、BBHで87.5%を記録。コーディングタスクでは7つのベンチマークのうち5つで最高性能を達成しており、Polyglotテストでも48.5%の精度を示すなど、Claude Sonnet 3.5などの他モデルを上回る数値をマークしています。特に数学やプログラミングの分野では大手商用モデルにも匹敵するか、あるいはそれ以上の実力を持つとの報告もあります。


こうした実績からもわかるように、DeepSeek V3はオープンソース領域においてトップクラスの性能を誇り、一部のタスクではクローズドソースの大規模モデルを凌ぐ可能性を秘めています。大規模アーキテクチャを生かして長文処理を得意とし、かつコスト効率を高める工夫が凝らされた点は、研究や開発のみならず、実際のビジネス活用においても大きな魅力となるでしょう。
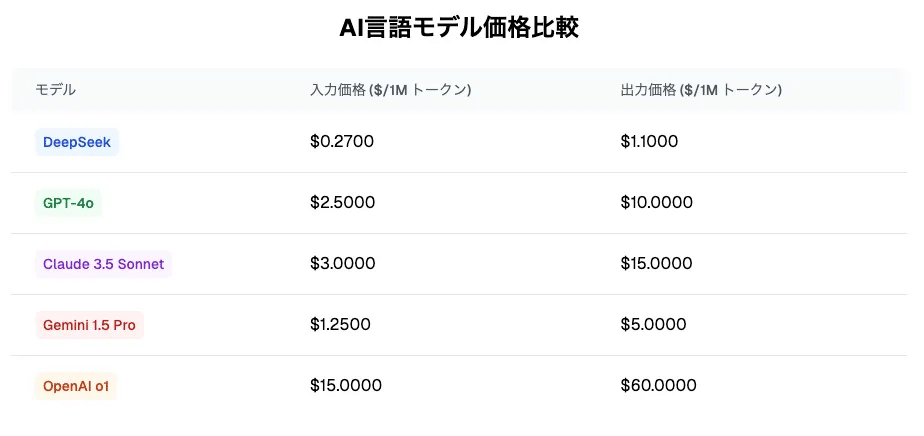
1-4 DeepSeek V3の料金
DeepSeek V3のAPIコストは極めて低価格で、以下の料金体系となっています。(※2/8以降からこの料金になります。)この金額は「GPT-4o」などの競合モデルと比べて約1/10のコストといわれています。高性能かつ安価という点で、多くのユーザーが注目しています。

入力:$0.27 / 1M トークン
出力:$1.10 / 1M トークン
💰 API Pricing Update
— DeepSeek (@deepseek_ai) December 26, 2024
🎉 Until Feb 8: same as V2!
🤯 From Feb 8 onwards:
Input: $0.27/million tokens ($0.07/million tokens with cache hits)
Output: $1.10/million tokens
🔥 Still the best value in the market!
🐋 3/n pic.twitter.com/OjZaB81Yrh
1-5 DeepSeekのデメリット
これだけ万能でも勿論問題点もございます。
こちらを必ず理解した上で利用することをお勧めします!!!
デメリット、ChatGPTとの比較、他モデルとの差分、チャットの利用方法、活用事例7選を解説しておりますので、最後まで必ずご覧ください🔥
ここから先は
¥ 1,450
Amazonギフトカード5,000円分が当たる
この記事が気に入ったらチップで応援してみませんか?