
WizardLM: Instruction Tuning を行うための複雑で多様な指示データの自動構築

# Instruction Tuning # LLM # 日本語解説
WizardLM: Empowering Large Language Models to Follow Complex Instructions
Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, Daxin Jiang
1. どんなもの?
指示チューニング用のデータセット Evol-Instruct を構築
汎用的な言語モデルを学習する上で重要となる 指示データを ヒトの代わりに LLM が生成する データ構築手法を提案。複雑で多様なデータを構築するために、小規模の指示データから派生させるよう LLM が反復的に加筆を行う。
Evol-Instruct (70K) で言語モデル WizardLM (7B) を学習し評価
ChatGPTとのやりとりを共有するサイト ShareGPT から収集した 70K の指示データで学習した Vicuna (7B) と比べて、WizardLM (7B) が高い性能を示したことから、複雑で多様な指示データが LLM を効果的に学習させることを示唆。
難易度の高い設定における人手評価の結果、WizardLM (7B) が ChatGPT (175B~) よりも高い選好性を示したことから、Evol-Instruct が複雑な命令を扱う LLM の能力を大幅に改善できることを示唆。
2. 先行研究と比べてどこがすごい?
Closed-Domain Instruction Fine-tune
(説明)様々な NLP タスクを対象に指示追従モデルを学習する。タスクごとの指示はヒトが手書きで作成する。
(問題)1つの指示は1つの NLP タスクしか含まず、入力データ形式は単調 であるため、実シナリオで適切に動作しない場合がある。
(比較)本研究では特定のタスクを指定しないオープンな設定で、複雑で多様な指示データを構築する。
(研究例)
Wei+'22 - Finetuned Language Models are Zero-Shot Learners (ICLR) [OpenReview]
Aribandi+'22 - ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning (ICLR) [OpenReview]
Sanh+'22 - Multitask Prompted Training Enables Zero-Shot Task Generalization (ICLR) [OpenReview]
Xu+'22 - ZeroPrompt: Scaling Prompt-Based Pretraining to 1,000 Tasks Improves Zero-Shot Generalization (EMNLP) [ACL Anthology]
Chung+'22 - Scaling Instruction-Finetuned Language Models [arXiv]
Open-Domain Instruction Fine-tune
(説明)特定のタスクを指定しない指示データによって学習を行う。
(問題)自由な指示を求めるためアノテーションコストが高い。また 難易度の高い複雑な指示をアノテータに依頼することは難しい。
(比較)本研究では、ヒトの代わりに LLM が指示データを作成 する。また Alpaca の Self-Instruct とは異なり、Evol-Instruct は生成される指示の複雑さを考慮する。
(研究例)
Ouyang+'22 - Training language models to follow instructions with human feedback [arXiv]
Taori+'23 - Stanford Alpaca: An Instruction-following LLaMA Model [project]
Chiang+'23 - Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* Chatgpt Quality [project]
Luo+'23 - Augmented Large Language Models with Parametric Knowledge Guiding [arXiv]
3. 技術や手法のキモはどこ?

Q. 複雑で多様な指示データをどうやって作成するか?
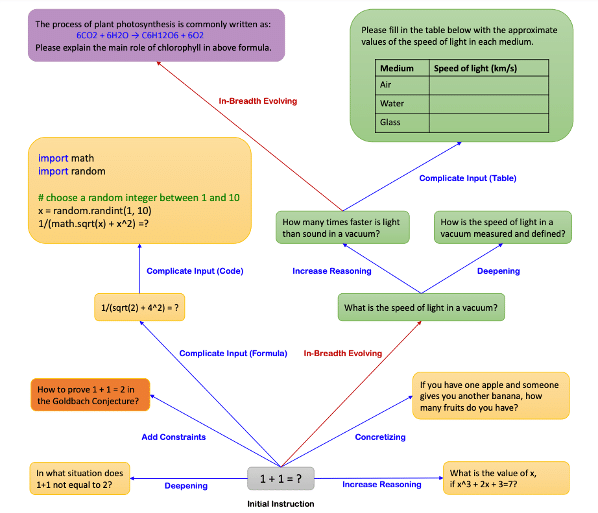
初期データとしての指示を LLM によって反復的に書き換える(進化)ことで複雑で多様な指示データを作成する。進化用のプロンプトは6つ(In-depth Evolving で5つ、In-breadth Evolving で1つ)存在し、指示を進化させる際は無作為に1つのプロンプトを選択する。
In-depth Evolving (複雑化)
①制約条件追加 ②深ぼり ③具体化 ④推論過程追加 の4つのタスク表現に基づくプロンプトを LLM に入力することで、与えられた指示を複雑化する。


In-depth Evolving では、上記4つのタスク表現に加えて「XML データを追記して下さい」のような複雑なデータ形式を伴う ⑤Complicate Input Prompt というタスク表現も提案されている(詳細は論文を参照されたい)。
In-breadth Evolving(多様化)
トピックやスキルの網羅性、データセット全体の多様性を高めるため、⑥突然変異 のタスク表現に基づくプロンプトを LLM に入力する。

Elimination Evolving (品質担保)
LLM からの生成において、以下の4つに該当する不適切な指示を除去:
進化前の指示と比べて、進化後の指示に新しい情報が含まれないと ChatGPT が判定した場合(判定プロンプトは付録 G を参照されたい)
指示内容が「sorry という文言を含む」等のルールに合致する場合
指示に対する応答文が句読点やストップワードのみを含む場合
指示がプロンプトの一部(#Rewritten Prompt# 等)を含む場合
Q. Evol-Instruct を使用するメリットは何か?
先行研究との評価セット間による難易度の比較
(従来)既存の評価セットは難易度の高い指示データの割合が低い
(提案)人手によって難易度のバランスが取れた評価セットを作成

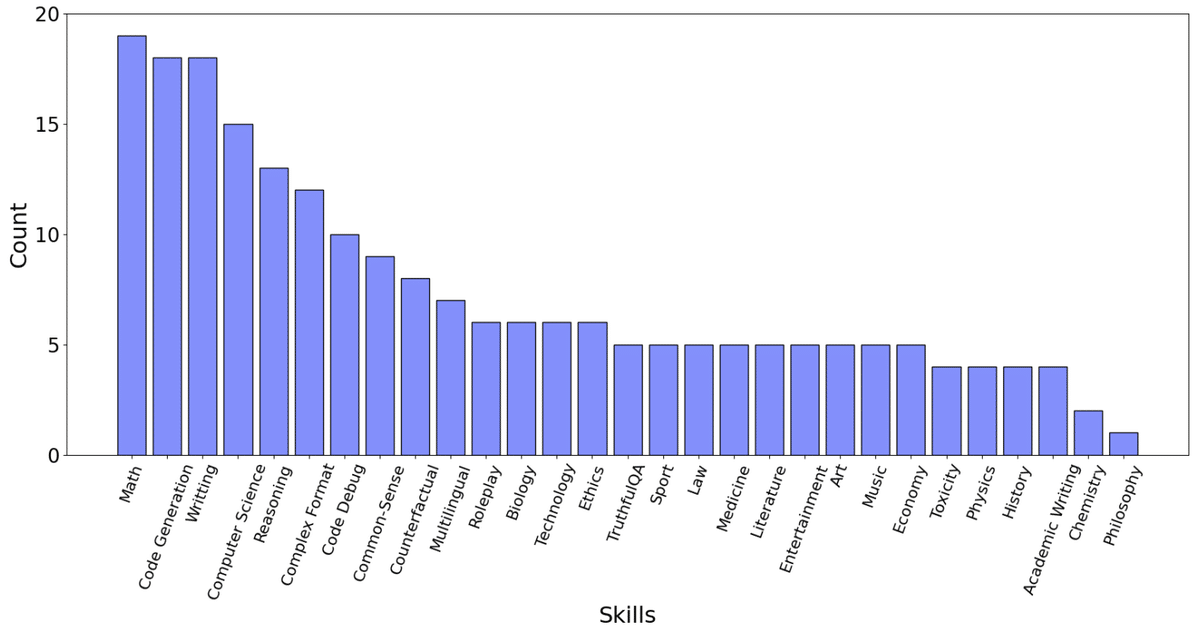
先行研究との評価セット間による多様性の比較
(従来)Vicuna 評価セットは 9 スキル 80 インスタンスで構成
(提案)Evol-Instruct 評価セットは 29 スキル 218 インスタンスで構成
4. どうやって有効だと検証した?
WizardLM の学習設定
ヒトの会話データに対して Evol-Instruct の有効性を検証するため Alpaca の学習セットにおける 175 個の指示を Evol-Instruct の初期データとする
ChatGPT を用いて 1 指示に対して 4 回の進化を実施し、250K の Evol-Instruct を構築
Vicuna 学習時の会話データ 70K と同量にするため、250K の Evol-Instruct から 70K をサンプリングして LLaMA-7B を学習。
評価設定
比較対象のモデル
・ChatGPT
・Alpaca: text-davinci-003 から生成された 52K の指示で LLaMA を微調整
・Vicuna: ChatGPT とのやりとりを共有するサイト ShareGPT から収集した 70K の指示データで学習。FastChat-7B モデルを使用。
人手評価による既存モデルとの比較
評価セットに対して Alpaca, Vicuna, WizardLM, ChatGPT の各応答が盲目設定で提示され、アノテータは以下 5 つの基準に従って各応答を 1~5 にランク付けする:
・Relevance … 文脈と質問の意味を正しく解釈する能力があるか
・Knowledgeable … 問題解決のために詳細な知識を正確に利用できるか
・Reasoning … 正しい推論過程や妥当な推論概念を考案するか
・Calculation … 与えられた数式を正確に計算できるか
・Accuracy … 対応する動作を正しく行うことができるか

自動評価による既存モデルとの比較
Vicuna 論文で提案された GPT-4 による 自動評価 を採用。


5. 議論はある?
人手評価と自動評価における不整合は何が原因か?
高い難易度の Evol-Instruct 評価セットにおいて、人手評価では WizardLM が高い選好性を示したが、自動評価ではその逆の結果となった。主な理由としては以下が考えられる:
・見た目のフォーマットに対する人間の選好性
・同等の回答においては、コンパイルがパスされる問題が選好される
In-depth Evolving によって複雑性に段階的な変化はあるか?
ChatGPT を用いて各指示の難易度と複雑さのレベルを判定(付録 E 参照)

In-breadth Evolving によって多様性に変化はあるか?
指示に対する BERT の分散表現を k-means で 20 クラスタに分割

本研究の限界
GPT-4 による自動評価、人手評価の限界
スケーラビリティ・信頼性に課題
Evol-Instruct 評価セットは、LLM が適用あるいは他手法と比較される全てのシナリオやドメインを代表する訳ではない
本ブログ著者による感想
同量パラメータの Alpaca, Vicuna に比べて明らかな有効性を検証している点が評価できる。特に人手評価において同データサイズの ShareGPT で学習された Vicuna に対して WizardLM が高い選好性を示した点は、昨今の大規模言語モデルの学習においても影響力の大きい結果といえる。
独自 LLM サービスを展開している場合は、継続的なデータ収集と併せて LLMOps に組み込むことができる。
Evol-Instruct における6つのプロンプト作成に恣意性がある。
ChatGPT を用いた複雑性の評価は一指標として参考になるものの、何をもって複雑と判断しているのか明らかでない。検証方法の確立が難しいのは承知だが多段推論や構成的推論等からみた複雑性なども考えられる。
本研究では「指示の複雑性・多様性」に着目しており「推論方法の複雑性・多様性」はまた別の話。多様な推論方法(水平思考、垂直思考、批判思考、統合思考等)を促す指示セットを作成する方向も考えられる。
学習セットにおけるタスク別のデータ分布についても議論の余地がある。250K の Evol-Instruct から 70K をサンプルしているが、タスクのデータ分布が推論性能に与える影響についても明らかにしたい。
6. 次に読むべき論文は?
Wang+'23 - Self-Instruct: Aligning Language Models with Self-Generated Instructions (ACL) [ACL Anthology]
Wei+'22 - Finetuned Language Models are Zero-Shot Learners (ICLR) [OpenReview]
Chung+'22 - Scaling Instruction-Finetuned Language Models [arXiv]
Zhang+'23 - Instruction Tuning for Large Language Models: A Survey [arXiv]
日本語の参考資料
RIKEN - LLMのための日本語インストラクションデータ作成プロジェクト [site]
岡崎直観教授+'23 - 大規模言語モデル(2023年度統計関連学会連合大会チュートリアルセッション 言語モデルと自然言語処理のフロンティア)[speakerdeck]
西田京介氏、西田光甫氏、風戸広史氏 / NTT人間情報研究所 +'23 - 大規模言語モデル入門(ソフトウェアエンジニアリングシンポジウム 2023)[speakerdeck]
濵田氏 / ブレインパッド +'23 - GPT-4登場以降に出てきたChatGPT/LLMに関する論文や技術の振り返り [blog]
岩澤有祐講師 / 東京大学 +'23 - 基盤モデルの技術と展望(人工知能学会全国大会チュートリアル)[speakerdeck]
中筋渉太氏+'23 - LLM Fine-Tuning(東大松尾研LLM講座 Day5資料)[speakerdeck]
AI-SCHOLAR+'22 - 言語モデルのZero-Shot性能を高めるFine-Tuning [blog]
西田京介氏 / NTT人間情報研究所 +'23 - 論文紹介 / Llama 2: Open Foundation and Fine-Tuned Chat Models(第15回最先端NLP勉強会)
岡崎直観教授 / 東京工業大学 +'23 - 【論文紹介】Google. 2023. PaLM 2 Technical Report [speakerdeck]
Appendix (memo)
A. 学習設定
Azure OpenAI ChatGPT を用いて進化の処理を実行
temperature = 1.0
max tokens = 2048
frequency penalty = 0
top-p = 0.9
合計で 52k * 4 * 3 = 624k 回の API 送信してデータセットを構築
Alpaca の 52k 指示セットで初期化
4 回の進化(指示の書き換え)を行い 250k の指示を取得
各進化時において ①~⑥ の 6 つのタスク表現から 1 つを無作為に選択
モデルの初期化は事前学習済みの LLaMA 7B を使用
optimizer: Adam
initial learning rate: $$2\times10^{-5}$$
max tokens: 2048
batch size per GPU: 8
GPU: V100 * 8台
misc: Deepspeed Zero-3
epochs: 3
training time: 70 hours