
【Flux.1】Flux.1時代のローカルAI画像生成④-3【SD1.5】

はじめに
下記事の続きです。
広範囲にテストを行ってみたのですが、Flux.1とSD1.5を交互に生成する手法は、汎用的にかなり良い結果を出すようです。さらに良くなるようにComfyUIのノードを作り直しました。
本記事のComfyUI jsonファイルは過去の下記事の付録欄にてダウンロードできます。
生成例
Flux.1(pro)を利用できるサイトのひとつhttps://fluxai.studio/ja/showcasesで紹介されているプロンプトで試します。
black forest gateau cake spelling out the words "FLUX PRO", tasty, food photography, dynamic shot


アップスケーラを利用している事もありますが、Pro版を大きく超える品質です。


ComfyUIワークフロー例の紹介
生成の流れ
① プロンプトを利用したFlux.1の画像を生成
② (1)で生成した画像を元にしてSD1.5モデルでのimg2imgを行う。ただし、プロンプトはLLMで(1)を整形したものを利用
③ (2)で生成した画像を元にして、再度Flux.1モデルでのimg2imgを行う。ただし、プロンプトは(2)をLLM Visionモデルで作ったものを利用
④ (3)で生成した画像を元にして、SD1.5モデルのimg2imgを行う。ただし、プロンプトは(2)と同じ
⑤ オプションとしてUltimate SD Upscalerを利用する ※ 場合によっては劣化させる事もあるのでオプションとします
全体図

① Flux.1一回目
特に工夫のない通常のFlux.1の生成方法です。最後に生成画像をモデルアップスケーラで1.2倍にして、次の工程に渡します。

② SD1.5一回目
まずはSD1.5用のプロンプトを作ります。先のFlux.1で利用したプロンプトを「短い英文に変換して。結果のみ表示して。」の指示でLLMで作ります。※ 長過ぎるプロンプトはSD1.5で悪影響になる場合があるため
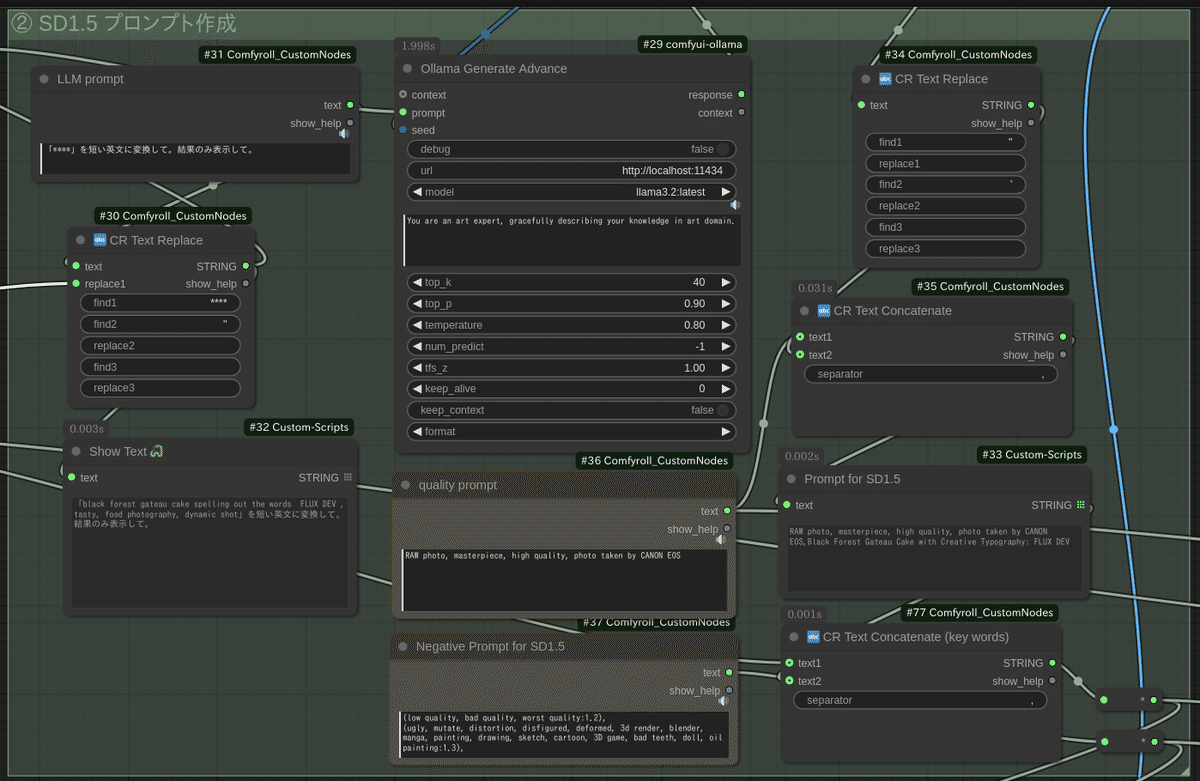
Flux.1一回目の画像を受け取り、SD1.5でimg2imgをします。形状を大きく損なわないように、ControlNet(depth)を利用します。
LoRA効果を強く出したい場合は、denoiosing strengthを大きく、Apply ControlnetのStrengthを小さくします。
生成画像をオリジナルサイズの1.5倍にして、次の工程に渡します。

③ Flux.1二回目
先の工程の結果をFlux.1でimg2imgします。その前にVisionモデルでプロンプトを作ります。

Flux.1でimg2imgします。生成画像をオリジナルサイズの2倍にして、次の工程に渡します。

④ SD1.5二回目
最終工程です。SD1.5でimg2imgします。例では768x1024が初期画像サイズですので、1536x2048の画像が完成します。ここまでRTX3060(12G)で7分弱かかりました。

⑤ オプション工程
Ultimate SD Upscalerを利用します。さらに1.5倍にします。プロンプトはSD1.5の品質プロンプトのみを利用します。

使い方と技工的なもの
初期プロンプトとキーワード
一回目のFlux.1のプロンプト入力と、すべてのプロンプトに強制的に挿入するキーワード欄です。LLMの加工で、キーワードが消えてしまう事を防ぎます。

初期画像サイズの指定とSD1.5 LoRA
最初の画像サイズを768x1024に指定しています。工程②と工程④で利用するLoRAの指定もここで設定するようにしています。それぞれ2つずつ指定できるようにしています。
※ ComfUIのショートカット「Ctl+B」で各ノードのON/OFFが切り替えられるので便利です。LoRAを利用しない場合は切り替えてピンク色にするだけです。
Global Seedを利用して、(Ollama以外の)各Seedを一括管理できるようにしています。途中から再開したい場合などに便利です。

GPUメモリ管理
LLMの利用で(時々)問題になる事は、GPUメモリを専有してしまい。CPUで計算してしまう事です。そのために3つのギミックを利用しました。

LLM利用直前に、LayerUtilityのPurge VRAMを利用する(ただし必要のないパッケージを大量に入れてしまうので考えものですが…)
Impact-PackのSleepを利用する
Purge VRAMは非同期処理のようですので、1秒の緩衝時間を作っています
LLM(Ollama)を利用した後にも1秒の緩衝時間を作ります
ollamaノードの「keep_alive」を0に設定するとLLM処理の終了後に即座にGPUメモリを開放するはずなのですが、タイミングによるようです。
まとめと付録
以前の記事の有料の付録欄に、本記事のComfyUI jsonファイルを追加しました。記事サポートをしていただける場合はよろしくお願いします。
以下、関連する記事の【PR】です。