
【Flux.1】llama.cppでFlux.1のGGUF変換メモ【safetensors】

はじめに
Flux.1(dev)モデルでgguf形式を扱う事ができるComfyUIのカスタムノード「ComfyUI-GGUF」がありますが、ComfyUIを利用せずにコマンドラインで量子化gguf形式に変換するまでの手順メモを残します。(ちょっと分かりにくかったので)
※ Linux(またはwsl2)での作業です。仮想環境はAnacondaを利用します。
変換手順は次になります。
BF16版safetensorsモデルを入手:ダウンロード
safetensorsモデルをBF16版gguf形式に変換:convert.pyスクリプト利用
BF16版ggufからQ4_K_S量子化ggufに変換:llama-quantizeバイナリコマンド利用
ComfyUI-GGUF
GGUF変換を可能にするComfyUIのカスタムノードのリポジトリはこちら、
仮想環境と設定
まずはAnacondaで仮想環境を作ります。筆者環境ではPython3.12で動作しました。
# 仮想環境作成
conda create -n comfyui-gguf python=3.12
# 仮想環境に入る
conda activate comfyui-gguf作業ディレクトリを作ります。たぶん一時ファイル保存を含めて60GB以上必要です。
# 作業出ディレクトリ作成
mkdir ~/app/comfyui-gguf
cd ~/app/comfyui-gguf
# リポジトリをクローン
git clone https://github.com/city96/ComfyUI-GGUF.git
cd ComfyUI-GGUFお決まりのインストールコマンド(comfyui-gguf仮想環境に入っている事を確認)
pip install -r requirements.txt実際に利用するユーティリティはtoolsディレクトリの中のものです。
cd toolstoolsディレクトリのREADME.mdの手順に沿って進めていきます。
toolsディレクトリで作業します。量子化変換のプログラムエンジンとして、別リポジトリのllama.cppをcloneします。
git clone https://github.com/ggerganov/llama.cpp
pip install llama.cpp/gguf-py※ ちなみにllama.cppはLLMの量子化ggufにも利用します。
その他変換に必要なpythonパッケージを導入します。
# 変換にCUDAは必要無いはずですが、面倒なので全部導入します(cuda12.6の場合)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
# safetensorsの変換に必要
pip install safetensorsFlux.1のモデルのダウンロード
変換例として次のFlux.1(dev)ベースのモデルをダウンロードします。BF16版の約22GBのものです。
ダウンロードファイル「pixelwave_flux1Dev03.safetensors」を指定してBF16形式ggufに変換します。同じディレクトリ(Downloads)にBF16形式ggufファイルが、ほぼ同じサイズで作成されます。
python convert.py --src ~/Downloads/pixelwave_flux1Dev03.safetensorsllama.cppの設定
Flux.1のモデルに利用するには、特別バージョンのllama.cppを利用する必要があります。(※ Flux.1以外のモデルを利用する場合は、別のtagになります。README参照)
cd llama.cpp
# 特別バージョンにする
git checkout tags/b3600
# パッチを当てる
git apply ..\lcpp.patch# llama.cppのビルド作業環境の作成
mkdir build
cd build
# cmakeがない場合はsudo apt install cmake
cmake ..
# バイナリコマンド・llama-quantizeをビルドする(8並列)
cmake --build . --config Debug -j8 --target llama-quantize
cd ../..量子化の実行(Q5_K_Sの場合)
llama.cpp/build/bin/llama-quantize ~/Downloads/pixelwave_flux1Dev03-BF16.gguf ./pixelwave_flux1Dev03-Q5_K_S.gguf Q5_K_S成功すれば、カレントディレクトリに「pixelwave_flux1Dev03-Q5_K_S.gguf」が作成されます。
動作テスト
せっかくなので、PixelWaveモデルのトップ画面のプロンプトを試します。ここではKrita-ai-diffusionを利用します。※ ggufファイルは、ComfyUIフォルダの「models/unet」に保存します
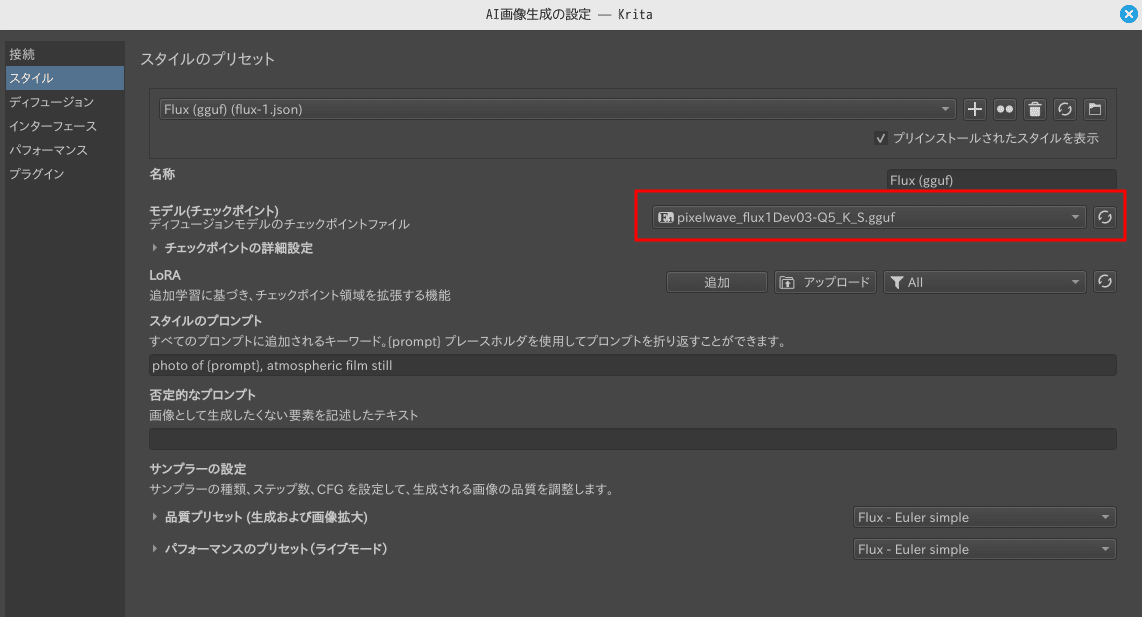
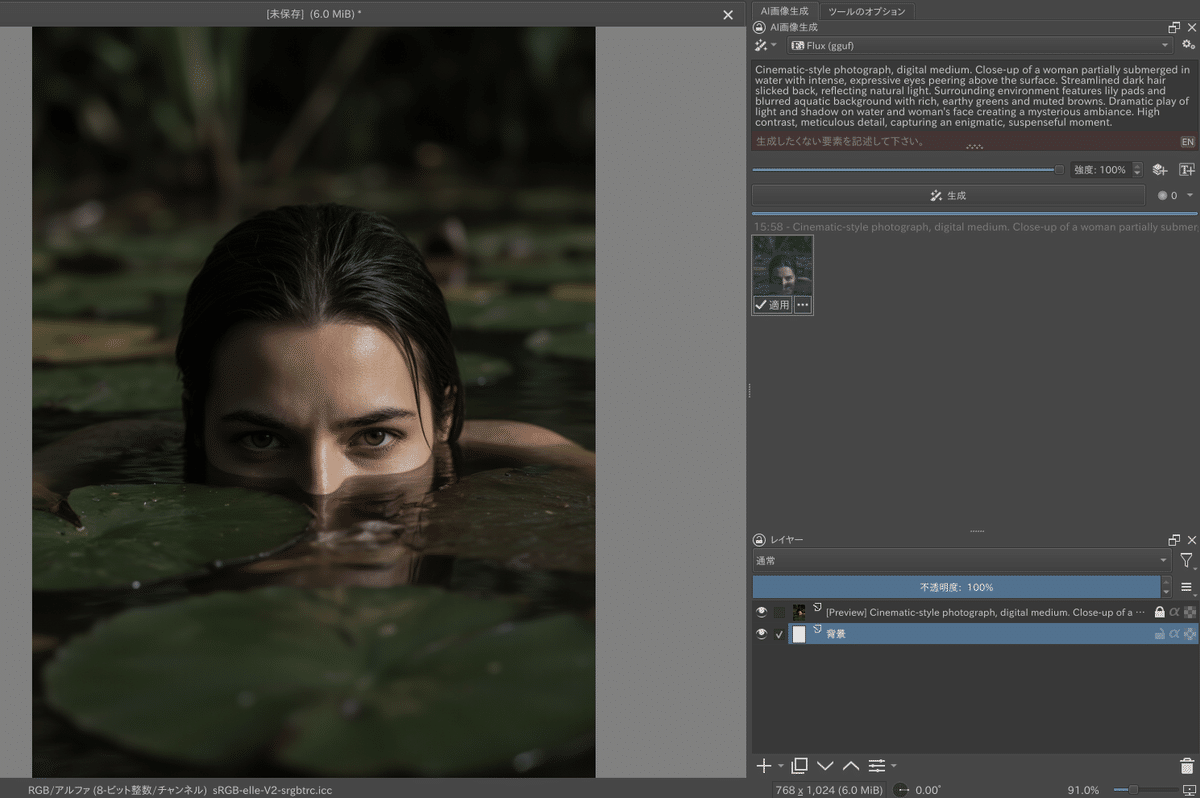
トップ画面の画像とほぼ同じものが問題なく生成できています。(768x1024解像度)
以下、関連する記事の【PR】です。