
【入門】NMKD Stable Diffusion GUI で LoRA を作る

想定する読者
NMKD Stable Diffusion GUI をインストールできる人
ローカルで画像生成を行った事がある人
LoRA を使った事のある人
はじめに
Stable Diffusion の爆発的な人気で、様々なローカル生成用の実装が公開されましたが、ブラウザで利用する webUI でなく、一般的な Windows アプリケーションとして実用的に利用できるのは NMKD Stable Diffusion GUI しかないと思います。(※ NMKD とは、NMKD氏が開発した Stable Diffusion GUI という意味)
残念ならが開発の更新が止まってしまっているので、新しい機能の拡張はないと思われますが、それでも気軽にローカル画像生成を行える点で非常に有用なツールです。
さらに webUI を利用する人にとっても、NMKD Stable Diffusion GUI の LoRA 学習機能は便利だと思います。
LoRA とは(少ない学習と計算資源で高品質な学習モデルを実現できる)簡易学習の一つですが、それでも敷居が高く、実際に使いこなしている人は少ないと感じます。
ネットでダウンロードできる LoRA のほぼすべては kohya-ss氏の sd-scripts が利用されています。
このスクリプトを直接利用する、もしくは webUI の機能拡張から GUI 経由で利用する手法が最も多く利用されています。しかしながら、導入の面倒さやトラブルの多さがネックです。
一方で NMKD版は機能こそ限定的ですが、限定されているからこそ簡単に利用できる利点があります。もちろん、NMKDで作成した LoRA は他の webUI 等で利用する事も可能です。普段 webUI を利用してる方も、LoRA作成だけ NMKD版を利用するのは方法のひとつだと思います。
準備
NMKD Stable Diffusion GUI を利用した LoRA 作成のための必要事項です。
【Windows 10/11】
【NMKD Stable Diffusion GUI 1.11.0 が既にインストールされている事】
【GPUはメモリ6GのNVIDIA製のTuringアーキテクチャ以上】
Turing でも、tensorコアのない1650/1660は難しいです。つまり RTX 名を表示しているものが必要になります。
【システムメモリは32GBを推奨】
NMKD氏のドキュメントには16GBでも動くはずと記述があります。ただし、Windows の仮想メモリは大きく用意しておく必要があります。※ 利用しなくてもエラーで止まります
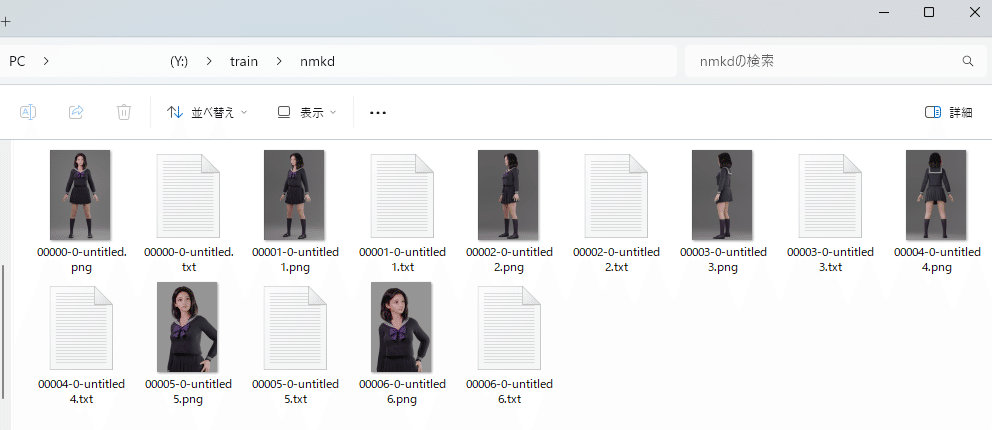
【5枚以上の画像とそれらに対応したタグ】
一般的には、512x512 や 768x768 解像度の画像です。NMKD氏のドキュメントには、品質重視で、タグ(画像を説明するプロンプト)なども手動がおすすめとあります。300枚の雑多なダウンロード画像よりも、厳選した15枚の画像の方が良いそうです。
学習元画像の準備
AI学習と聞けば複雑そうな気がしますが、実際の手順は、数枚の画像とそれを説明するテキストファイルが必要になるだけです。
上記 BOOTH で販売中の LoRA は、kohyka-ss スクリプトを利用したものですが、同じ学習画像を利用した NMKD版での LoRA 作成を行います。つまり、7枚の 3D レンダー作品を利用します。解像度はすべて 512x768 です。
ちなみに、元の3Dモデルも販売しています。

タグの準備
LoRA 学習には、画像とそれに対応したタグが必要になります。(※ 分離を全く考えないのであれば、タグが無くてもかまいません)たとえば、一枚目の画像に対応しているタグファイルの内容は、
pr3dm002, sailor-fuku, serafuku, school uniform, a woman in a skirt , a sailor's outfit is standing in a pose, in front of a gray backgroundとしています。何がベストなタグかどうかは難しいところですが、一般的には次のようなものが挙げられます。
【先頭にトリガーワード】
LoRAの名前のようなものです。すべてのファイルに登場させる事によって概念を関連付けさせます。ファイル名と一致させる必要はありません。
タグとして記載したすべての単語は、Stable Diffusionが解釈する際に変更を受けるようになります。たとえば、この LoRA を利用すれば、woman は変更を受けて元の woman ではなくなります。つまり、他の単語とかぶらないキーワードのようなものが良いとされます。
【ベースモデルに即した記述スタイル】
たとえば、アニメ風で Danbooru タグ(1girl や solo 等)を利用したモデルの場合は、上記例のような自然言語的な記述よりも、Danbooruタグ風にします。
【学習対象の分離】
背景と分離したい場合は gray background のように背景を説明するタグを必ず入れます。もしヘアスタイルと分離したい場合であれば、髪型に関する記述も同様に入れます。ただし、筆者のように生成品質重視で、分離作業を主に手動インペイントで行うのであれば、あまり気にする必要はなく、むしろ無理に分離しない方が学習元に近くなるので生成”品質”は上がります。
スタイルの分離も可能です。手書きなどを学習元に選ぶ場合は、”手書きである”事(hand writing等)を記述する事で、生成物が手書きにならないようにできます。
NMKD Stable Diffusion
起動と設定
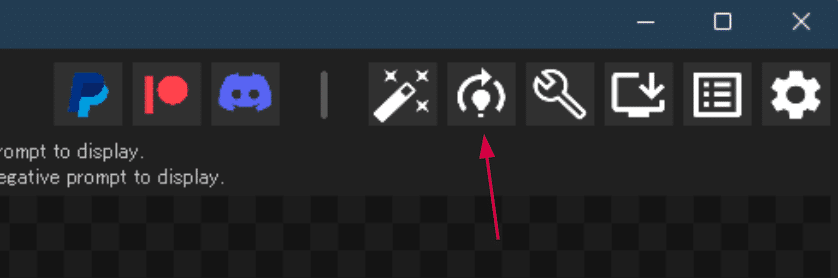
上記ボタンを押すと、LoRAの設定画面が開きます。
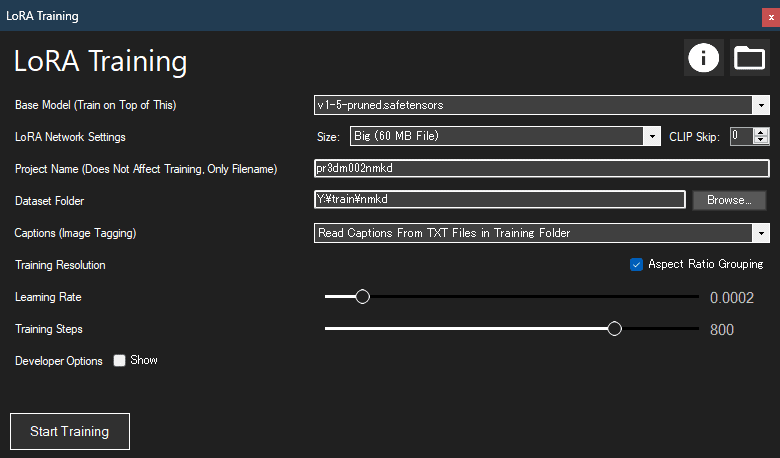
【Base Model】
学習に利用するモデルを指定します。Stable Diffusion の開発元である StabilityAI/runwayml が公開していて、ほぼすべてのモデルのベースになっているv1-5-pruned.safetensorsを選択すると、最も汎用性のあるLoRAになりますが、品質を追求するなら、リアルやアニメなどに特化したモデルを利用します。
学習時において原理的には、fp16版(約2Gのファイル)よりも、fp32版(約4Gのファイル)の方が良いとされていますが、今回の程度ならば、差が出ないように感じます。
【LoRA Network Setting】
確認はしていませんが、おそらくLoRAの次元差だと思います。大きいファイルほど詳細な学習が可能になり複雑な概念の分離もできます。ただし、アニメなどではノイズも学習してしまうので必ずしも大きい次元の方が良いという話ではありません。最も大きい60MBを選択します。
CLIP Skip は利用する Base Model に一致させる必要があります。今回は 0 を指定します。
【Project Name】
作成するLoRAのファイル名を決めます。今回は pr3dm002nmkd とします。
【Dataset Folder】
学習元画像とタグを記述したファイルのフォルダを指定します。
必ず画像ファイルと対応したタグファイルの名前を一致させる必要があります。
【Training Resolution】
Base Model が 512x512 で学習されているため、それらに近い解像度が良いとされます。Aspect Ratio Grouping は効率良く処理するためだそうですが、詳細は確認していません。
【Learning Rate】
AIの学習とは、少し変更→対象画像と比較→少し変更→比較… を繰り返します。その変更の大きさを指定します。ここではデフォルトの0.0002にします。
【Training Steps】
学習回数を指定します。少なければ学習効果が弱く、多ければ学習効果が強くなります。適切な値を探す必要があります。強すぎるとどんなプロンプトを入力しても同じ画像になってしまいます。800を指定します。
学習のスタート
「Start」ボタンを押せば学習がはじまります。筆者環境 RTX 3060 では30分程度で終了しました。必要なGPUメモリも6GB程度です。
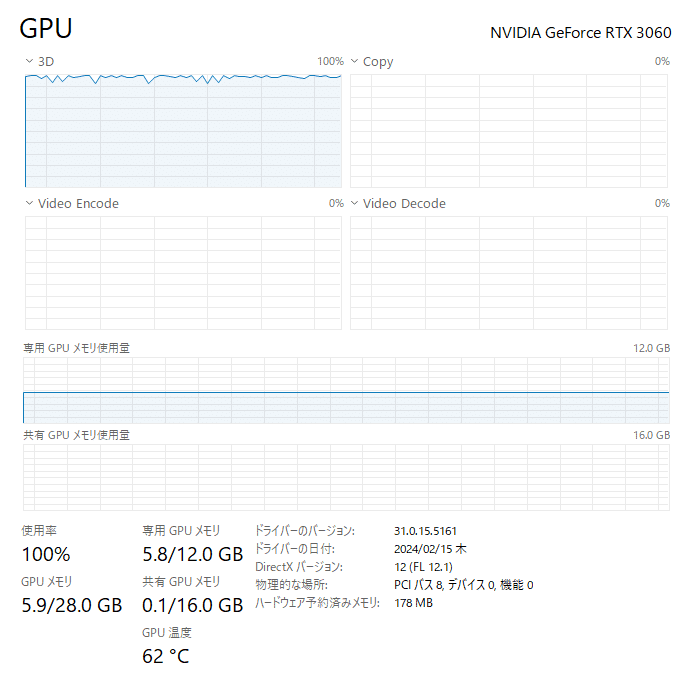

結果の確認
作成されたファイルは NMKD Stable Diffusion GUI インストール先フォルダの Models→LoRAs フォルダに保存されます。
NMKD Stable Diffusion GUI でも確認できますが、ファイルを webUI の models→Lora フォルダに保存して画像を生成してみます。
モデルは、Beautiful Realistic Asian BRAv6 を利用します。
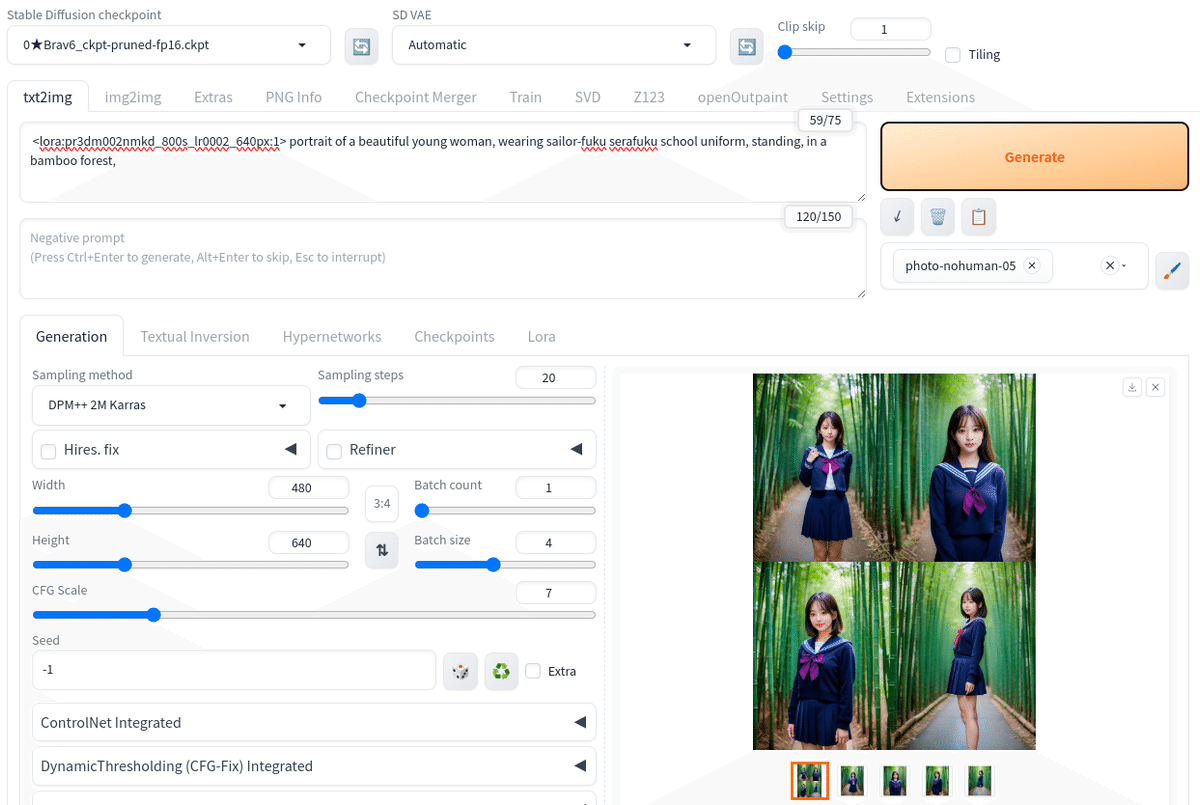
高精細化して完成です。

LoRA 効果が弱いので、もう少し学習回数を上げた方が良いかもしれません。