
【Ollama】Llama3.2-visionを試した話【ローカルVLM】

はじめに
Ollamaバージョン4.0からLlama3.2-Visionを利用できるようになりました。
VisionモデルとはLLM(Large Language Model)に視覚機能(Vision)をもたせたモデルです。図や写真を利用してLLMチャット等を利用できます。
しかしQwen2-VLと異なり、Llama3.2-Visionは日本語には非対応なので用途は限定的です。
導入
Ollamaコマンドでダウンロードします。Ollama公式リポジトリはこちら、
Windows版「OllamaSetup.exe」をダウンロード&実行すれば導入できます。
llama3.2-visionの取得コマンドです。
ollama pull x/llama3.2-vision動作テスト
Ollama OpenWebUIを利用した動作確認です。※ コマンドラインでも利用可能です。ollama run x/llama3.2-vision
写真解析
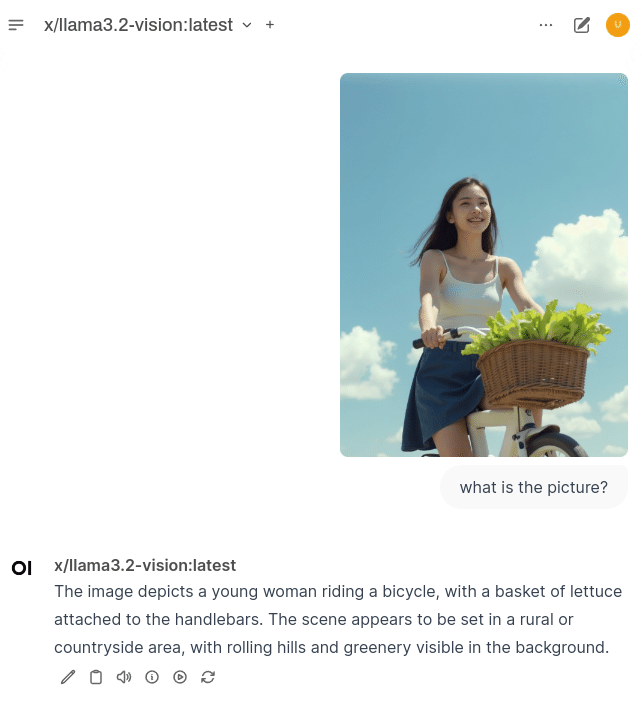


数式・グラフ・表解析
数式の場合
数式を読み取れるかの確認です。

表の場合
llava-llama3と同じで、単純な表ならば、実用的に読み込めるようです。

グラフの場合
この手の用途での実用的な精度は出ないようです。

ニュースサイト等
ニュースサイトのクリーンショットです。
llava-llama3と比べるとLLMの性能が良いので、画像と文章が混ざったデータの精度は良くなります。ただし、文章のみなら通常のOCRとさほど変らないかもしれません。

まとめ
Visionモデルは、日本語(文字)を読み込めないと用途が限られてしまいます。画像生成のプロンプト推測用途であれば、llava系(llava-llama3/phi3)の方が速度・メモリにおいて優れているので、あえてllama3.2-visionを利用する利点は少ないように思います。
以下、関連する記事の【PR】です。