
【ローカルLLM】自分専用の専門書籍をAIで作成する方法【マルチエージェント】

はじめに
ローカルLLM(Large Language Model)を利用して、技術専門書を自分のパソコンのAIに作成してもらう方法を紹介します。
もちろん、簡単な方法は「〜に関する専門書を作成して」で終わりますが、専門的な内容の場合は、そもそもAIがデータを持っていなかったり、納得のいく品質にならない事がほとんどです。そこでRAG手法を利用し、ローカルLLMで簡単に利用できる、複数のモデルを混ぜて性能を爆上げする手法で生成します。
ollama + OpenWebUIのローカル環境を利用します。Windowsでの導入方法を下記事で紹介しています。
RAG(知識)の用意
LLMの特定の知識を拡張する手法としてRAG(Retrieval-Augmented Generation)があります。外部知識をLLMが辞書のように参照するやり方で、さまざまな方式があります。
ここでは、Linuxコマンドのmpv(動画を再生するコマンド)に関する書籍を例としてLLMに作成してもらおうと思います。
RAGデータは、公式ドキュメントを参照するのが一番簡単だと思います。
Linuxでは主要なコマンドにmanマニュアルが用意されています。たとえば
man mpv
としてドキュメントを参照する事ができます。
RAGデータとするために、text・markdown・htmlに変換する方法もありますが、ここではpdfに一度変換したいと思います。
# ps2pdfをインストール
sudo apt install ps2pdf
# pdfに変換
man -t mpv | ps2pdf - mpv-man.pdf
IT系の技術情報としてRAGとして利用する場合は、英語ドキュメントの方が高品質になる事が多いので、日本語翻訳物よりもオリジナルの英語版をおすすめします。
RAGの登録
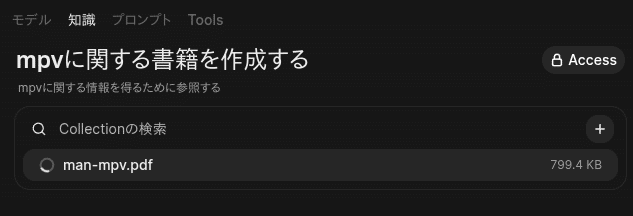
作成したpdfをOpen WebUIの「知識」として登録します。

※ 性能を出すためには、適切なembeddingモデルやpdf抽出ソフトウェア等が設定されている必要があります。詳細はこちら、
これで、mpvの知識登録が完成しました。「Collection」となるので、manドキュメント以外にも複数の情報を登録して一括参照する事もできます。
※ 個人向けAIネットサービスでも似たようなRAG利用サービスはありますが、企業などでちゃんとした契約を結んでいない場合は、個人情報や(書籍などの)著作物をネットにアップするのは政府ガイドラインでも御法度とされている行為です。特に「お客様のデータは品質向上のために利用しますw」が利用契約にある場合は真っ黒の可能性が高いです。便利なサービスに見えても台無しになっている事が多いのは、本当になんとかして欲しいと思います。Dify等をローカルで構築していても、embedding処理を外部APIに頼ると同じ事(内部データをすべて送信します…)になります。つまり、すべてローカルで利用する事はかなりの利点がある事になります。
書籍の作成
プロンプト入力
それでは、以下のプロンプトを利用して書籍を作成します。


次のショートカットを登録しておくと、{{目的}}のみを置換できるので便利です。
## 指示
- {{目的}}に関する書籍を、以下の条件を厳守して作成してください。
- 必ず本文を具体的かつ詳細に記述し、概要やタイトル案だけで終わらせないでください。
## 条件
- 全体構成:6章以内を目安とし、入門者向けの内容としてください。ただし、内容が充実する場合は章数を増やしてもかまいません。
- 各章の要件:各章ごとに、以下を含めてください:
- 明確な章タイトル
- 章全体の概要
- 詳細かつ実用的な本文(具体例、ステップバイステップの解説、図解の説明などを含む)
- 全体の文字数:必ず50,000文字以上の本文を作成してください。
- 単なる要約や箇条書きではなく、流れのある一貫した文章で記述してください。
- 禁止事項:
- タイトル案のみを提示すること
- 各章を数行の概要だけで済ませること
- 全体の内容が簡潔すぎて目的を満たさないもの文章の生成
最初のLLMモデルは Mistral-Nemo-Japanese-Instruct-2408 を利用しています。その他おすすめローカル日本語LLMは下記にて紹介しています。

良くある事ですが、プロンプトで「すべて生成」してと言っても、タイトルや概要だけしか生成してくれない事があります。次に、LLMモデルを変更してさらに改良を指示します。

コンテキストサイズも32kと大きく性能も高いアリババのQwen2.5モデルを文脈途中で変更して利用します。Qwen2.5は非常に性能が高いのですが、中国語(簡体字)を生成してしまうデメリットがあります。しかし、img2imgのように、文脈途中で変更利用するとそのリスクは低減します。いわゆる「マルチエージェント」の利点です。
画像生成でも異なるモデルを交互に利用すると性能が爆上がりするのと同様に、LLMでも性能が著しく向上します。

最後に日本語を正確に処理できる最初のモデル Mistral-Nemo-Japanese-Instruct-2408 で推敲します。


書籍の完成

Markdownを表示できるソフトウェア(筆者は主にFirefoxの機能拡張MarkdownViewerを利用しています)で表示したり、pdfへ変換したりします。
もちろん、生成そのままだとハルシネーションをふんだんに含んでいるので、内容を人間が精査する必要があります。しかし、それも人間の学習において有用な作業となります。


まとめ
ローカルのメモリ空間なので、数百ページにも渡るような書籍は生成できませんが、ちょっとしたドキュメント利用には十分事足りる有用なものが無限に生成できます。
特に、最後のハルシネーションチェックは、ノートまとめのような作業になるため、人間のリアル学習作業には非常に効率が良いのではと思います。
以下、関連する記事の【PR】です。