
【初心者向け】最近のローカル日本語LLM【ローカル万歳】

はじめに
Ollama Open WebUIやLM Studioのローカルで簡単に利用できる最近の実用的な日本語対応のLLMを紹介しようと思います。※ Python言語を利用してアクセスするのではなく、「モデルのダウンロードとGUIソフトウェアの設定」で実行できるものです
Open WebUIの詳しい導入方法は下記事で紹介しています。
公式レポジトリはこちら
Qwen 2.5
中国アリババ社のLLMです。以前からありましたが、企業向けのみに公開されていたモデルです。最近バージョン2.5がオープンになり、Ollamaライブラリでも利用可能になりました。

筆者のRTX 3060(12GB)では、7Bモデルか14Bモデルが最適な規模になります。7Bモデル(Q4_K_M)であれば32kトークンでもGPUメモリにすべて載りました。
ollama pull qwen2.5とすると、デフォルト7Bモデルがダウンロードされます。
Qwen2でも同じですが、Qwen2.5の(筆者の主観的な感想ですが)良い点は、トークンサイズが大きく用途の癖がなくバランスが良い点です。Llama3.1等の競合する多言語モデルと比較しても、日本語の性能は高いです。※ ただし、日本語チューニングされたモデルと比べると日本語や日本特有の内容の性能は劣ります。
デメリットは中国語モデルであるため、時々簡体字を吐いてしまう事です。つまり、文章をデータとして整形したりする用途には向かないでしょう。ただし、Qwen2と比べると、簡体字が出てきてしまう頻度がかなり減っています。
Cyberagnet/Mistral-Nemo-Japanese-Instruct
筆者の主観ですが、現在のローカル日本語モデルでは(Elyzaを抜いて)最強モデルだと思います。ただし、まだollamaで利用できるモデルがないため、LM Studio上の利用になります。
※ 本来ならGGUFフォーマットはollamaで利用できるはずなのですが、下記紹介のGGUFは現バージョンのollamaで利用できません。
しかし、少しスキルは必要ですが、llama.cpp等で自分でGGUF変換すればollamaで利用できます
下記GGUFモデルを利用します。LM Studio側から検索すればワンクリックでダウンロードできます。
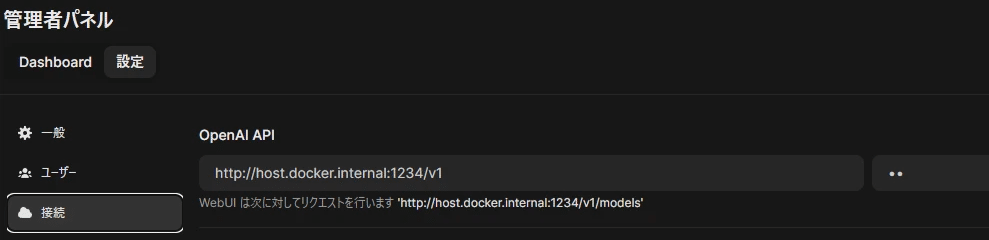
Open WebUIで利用する場合は、LM StudioでOpenAI APIサーバーを立てます。

左側のアイコン「Developer」モードにした後、「Select a model to load」でMistral-Nemo-Japanese-Instructモデルを読み込み、「Start Server」でOpenAI互換のAPIサーバーを立ち上げる事ができます。
サーバーを立ち上げた後は、Ollama Open WebUIからOpenAI APIとしてアクセスできます。
Llama-3-ELYZA-JP
東大ベンチャー企業のELYZA社のLLMです。
下記GGUFモデルを利用します。
日本語モデルとしては優秀なのですが、8kトークンなので、用途は限られます。ただし軽量で性能が良いので、非力な筆者のデスクトップ(GTX 1660ti+1650)ではデフォルトLLMとして利用しています。
信頼性も高く、ちょっとした事の翻訳や、自動化やデータ整形&変換に活用しています。
以下関連記事の【PR】です。
この記事が気に入ったらサポートをしてみませんか?