
医療画像AIにおけるDomain shift

ドメインシフトとは
ドメインシフトとは、機械学習モデルの開発環境において学習に使用したデータ(以下、学習データ)と運用環境で予測対象となるデータ(以下、ターゲットデータ)の性質が異なることです。詳細には、学習データとターゲットデータでドメインと呼ばれる入力変数X、出力変数Y、(X, Y)の確率分布のいずれかが一致しないことを指しています。
ドメインシフトと精度
ドメインシフトがどれくらい発生しているのかによって、運用環境では開発環境よりも予測精度が悪くなってしまいます。では、なぜドメインシフトが起こると精度が落ちるのでしょうか?そもそも、機械学習とはコンピュータがデータから統計的な特徴を学習し、学習した特徴をもとに新しいデータに対して予測を行うことです。この際、モデルはあくまで統計情報を学習しているに過ぎないため、学習データとターゲットデータのドメインが異なると、モデルはターゲットデータに対して正しく予測することができません。そのため、一般的な機械学習モデルは学習データとターゲットデータのドメイン分布が一致することを前提に開発されます。しかし、機械学習システムを実運用するときには、しばしばこの前提が崩れドメインシフトが起こります。

https://www.slideshare.net/DeepLearningJP2016/dl-149549473
ドメインシフトの種類
ドメインシフトはドメイン分布の違いから大きく三種類に分類されます。
covariate shift
共変量シフトとも呼ばれ、学習時とテスト時で入力変数の周辺分布が異なる場合を指します。例えば、以下のようなある人の住んでいる都道府県からその人の年収を予測するという問題を考えます。ここで学習データとテストデータがそれぞれ東北地方と九州地方から集められたデータで構築されるとき、学習データとテストデータで東北 / 九州のデータ割合が異なる場合がcovariate shiftに該当します。このとき東北の人と九州の人の年収はほぼ同じであるため、入力変数の周辺分布のみが異なることになります。

target shift
target shiftはcovariate shiftと反対に、学習時とテスト時で出力変数の周辺分布が異なる場合を指します。例えば、同様の問題で学習データとテストデータが東北地方と関東地方から集められたデータで構築されるとき、学習データとテストデータで年収の分布が異なる場合に該当します。しかし、この場合において年収分布の違いは入力変数の分布、つまり学習データとテストデータ内の東北 / 関東データの占める割合の違いによって生じているため、Target Shiftの問題は共変量シフトの問題も内包しています。

concept shift
concept shiftの問題は学習時とテスト時で条件付き分布が異なる場合を指します。例えば、同様の問題で学習データとテストデータ間の各都道府県の割合は同じですが、学習データとテストデータが作られた年代が全く異なる場合などに該当します。 日本における平均年収は右肩下がりであるため、学習データとテストデータの年代が異なることによって、同じ入力変数(都道府県)にもかかわらず出力変数(年収)が大きく異なってしまうという状況が発生します。

(参考:https://speakerdeck.com/mkimura/neurips2020-papers-on-dataset-shift-and-machine-learning?slide=8)
ドメインシフトの原因
ドメインシフトは運用直後に起きるパターンと、運用後しばらく経ってから起きるパターンがあります。
運用直後に生じる場合は、「学習データがターゲットデータを代表していないこと」が原因で、たとえば以下のような状況が挙げられます。
· 学習時と異なるユーザーを対象としている(健常者と患者など)
· 実運用で使えない特徴量を学習時に使用している
· データを計測する機器の機種や設定が異なる
一方で、運用後しばらく経ってから生じる場合は「データの非定常性」が原因で、以下のような可能性が考えられます。
· ユーザーの行動変化
· 装置・センサーの経年劣化
· データ取得やデータ方法の処理方法の変更
上記のように、ドメインシフトは実行環境を移行するタイミングや経時的変化があった際に生じる危険があります。前者パターンは開発フェーズでドメイン設定を工夫することで未然に防げる可能性がありますが、後者パターンは予測が難しく、学習データも存在しないため、開発フェーズにおける対策は困難です。そのため、いずれドメインシフトが起こることを見越した上で、その影響を最小限にするための対策が求められています。
ドメインシフトへの対処
そこで、ドメインシフトへの対処として継続的トレーニングやドメイン適応といった手法が提案されています。
継続的トレーニング
継続的トレーニングとは、運用中に取得される新規データに対して、モデルを継続的に再学習させることです。これはモデルが自律的に学習し、新しいデータが本番環境に適応する能力をサポートすることを意味します。そのため、継続的トレーニングを行うことで経時的変化に伴うドメインシフトの影響を減らすことができます。
しかし、全てのドメインシフト問題が継続的トレーニングで解決するわけではありません。例えば、ビッグデータを扱っており再学習に時間がかかる場合や新規データの教師ラベルが存在しない場合、ドメインシフトが起こった直後で学習データが少ない場合などは別の対処法を考える必要があります。
ドメイン適応 [3]
一方で、ドメイン適応は上記のような継続的トレーニングでは解決できない場合にも活用できます。ドメイン適応は、トレーニング済みのモデルをターゲットデータに一般化できるようにドメイン間の格差を調整することで、ドメイン分布の不一致を解消することを目的としています。

ドメイン適応の手法は数多く存在しますが、全てのタスクに万能な手法は存在しません。そのため、データサイエンティストは、学習モデルや利用可能なデータ、発生しているドメインシフトの性質に応じて、適切な手法を選択する必要があります。この場では、現実世界で最も起こり得る「ソースドメインにはラベルがあるが、ターゲットドメインにはラベルがない」場合のドメイン適応の手法についてご紹介します。
shallow domain adaptation
インスタンスベース
インスタンスベースのドメイン適応は、ソースのラベル付けされたデータに基づいてターゲットのリスクを最小限に抑えることによりcovariate shiftに対処することを目的としています。この方法では、ターゲットドメインとソース ドメインの入力変数に対して密度比を推定し、その値に基づいてソースドメインのサンプルに重み付けを行うことで、サンプル選択バイアスを補正します。
特徴ベース
特徴ベースのドメイン適応は、ドメイン全体で不変の特徴表現を抽出する変換を学習することにより、ソースデータをターゲットデータにマッピングすることを目的としています。この手法は、元データの特徴表現を変換し、新しい表現空間で元データの基礎となる構造を維持しつつ、ドメイン間のギャップが最小限になるように最適化します。
deep domain adaptation
deep domain adaptationは、Deep Learningを使ったタスクで生じたドメインシフトに対処する手法です。Deep Neural Network(DNN)を利用しており、主に不一致ベース、再構築ベース、または敵対ベースに分類されます。
不一致ベース
ドメイン分布の不一致を無視して、ドメイン間で共通する特徴のみを学習させるアプローチです。ロングは初めて、ドメイン適応でDNNを利用してドメイン間で共通の特徴を学習するDeep Adaptarion Network(DAN) を提案します。
・DAN
DAN は、タスク固有の表現に複数の適応レイヤーを追加することにより、ドメイン全体の周辺分布を一致させることでcovariate shiftに対処することを目的としています。

DNNが学習する特徴は層が深くなるにつれて一般的な特徴から特定のものに移行するため、DANでは一般的な特徴を学習する畳み込み層conv1-conv3 は凍結します。そして、やや特定の特徴を学習するconv4–conv5 によって抽出された特徴はファインチューニングし、特定のタスクに合わせて調整されている全結合層fc6–fc8はMK-MMD(multiple kernel variant of maximum mean discrepancies)に適合します。MK-MMDを利用して、すべてのタスク固有の表現を RKHS(reproducing kernel Hilbert space) に埋め込むことで、異なるドメイン分布の平均埋め込みを明示的に一致させることができます。
再構築ベース
ソースドメインからエンコーダのパラメータを学習し、デコーダに適応することで、ターゲットデータを再構築するアプローチです。オートエンコーダーを利用して、再構成エラーを最小限に抑え、ドメイン間で不変で伝達可能な表現を学習することにより、ドメイン間の不一致を調整します。再構築ベースの代表的な手法には、Deep Reconstruction-Classification Network (DRCN)などがあります。
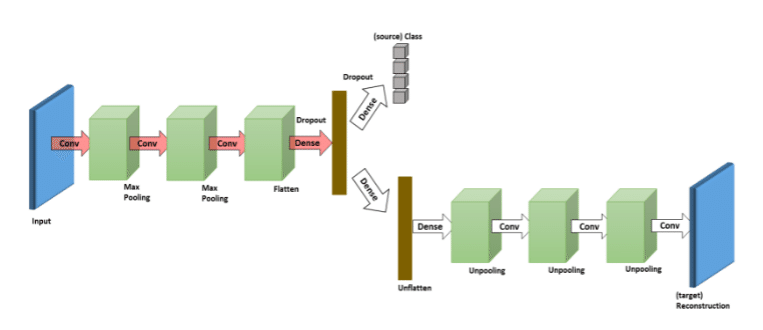
・DRCN
DRCN は、ソース ラベルを予測するための標準的な畳み込みネットワーク (エンコーダ) と、ターゲット サンプルを再構築するためのデコンボリューション ネットワーク(デコーダ)で構成されます。このモデルは、教師あり学習戦略と教師なし学習のアプローチを併用して、エンコーダのパラメータを学習し、ソースデータのラベルを予測し、デコーダのパラメータを学習して、ターゲットデータを再構築します。エンコーダのパラメータは、ラベル予測タスクと再構成タスクの両方で共有されますが、デコーダのパラメータは再構成タスクに対してのみ使用されます。
敵対ベース
クラス分類器がターゲットデータと学習データを区別できないようにモデルを学習させるアプローチです。ここでは敵対ベースの中でも汎用性が高く、引用数の多い Domain Adversarial Neural Networks(DANN) について簡単に紹介します。
・DANN
DANNは、ソースドメインのラベル付きデータとターゲットドメインのラベルなしデータによってNeural Networkを学習させます。(ターゲットドメインのラベル付きデータは必要ありません)

DANNはNNを使った特徴抽出器(黄緑)と分類器(青とピンク)によって構成されます。分類器には二種類存在し、一方はソースドメインのラベル付きデータで通常の教師ありタスクを解き(青)、もう一方はソースドメインかターゲットドメインかを分類するドメイン識別問題を解きます(ピンク)。このときドメイン分類器と特徴抽出器の間に勾配を逆転させる層を一枚挟むことで、特徴抽出器がドメインを識別できない方向に学習が進み、ドメインに不変な特徴が得られます。
医療現場における事例
ドメインシフトが起きる可能性は医療データに置いても例外ではありません。例えば、都心で集めた患者データで骨折のX線写真から治療期間を予測するモデルを学習させ、地方の病院で運用する場合を考えます。このとき、X線写真のみを用いて予測モデルを学習させる場合、都心より地方の方が平均年齢が高いため、運用時においてモデルが予測した治療期間よりも実際の治療期間が長くなる危険性があります。同じような現象は人種間、性別間でも発生する可能性が潜んでいます。こうした事例はcovariate shiftが起こっているパターンです。一方で、concept shiftはデータ取得手順の違いなどが原因で起こります。例えば以下の画像は、眼底写真においてコントラストが違っていたり、MRIにおいて撮像手法が違っていたり、グラム染色画像において染色方法が違うことによってドメインシフトが起きている例です。こうしたドメインシフトを防ぐためには、ベンダー企業が医師にドメインシフトの危険性を伝え、医師がAI製品を適切な条件下で使用することが重要です。また同時に、上記で紹介したような継続的トレーニングやドメイン適応といった対処も求められます。

まとめ
本記事では、AI製品を運用する上で大きな論点となりうるドメインシフトについて解説しました。
· ドメインシフトとはソースドメインとターゲットドメインの性質が異なること
· ドメインシフトには、covariate shift、target shift、concept shiftの三種類がある
· ドメインシフトの原因は「データの非定常性」と「ソースデータがターゲットデータを代表していないこと」
· ドメインシフトへの対処方法として、継続的トレーニングやドメイン適応などがある
Deep Learningの登場で便利なAI製品が次々と開発されていますが、それらは決して魔法の道具ではありません。そのため、ドメインシフトのような運用上のリスクが存在することを理解し、適切に対処することが求められます。
参考文献
[1]Deep Learning JP, ‘[DL輪読会]ドメイン転移と不変表現に関するサーベイ’, 00:59:39 UTC. Accessed: Dec. 27, 2022. [Online]. Available: https://www.slideshare.net/DeepLearningJP2016/dl-149549473
[2]‘NeurIPS2020 papers onDataset Shift and Machine Learning’, Speaker Deck. https://speakerdeck.com/mkimura/neurips2020-papers-on-dataset-shift-and-machine-learning?slide=8 (accessed Dec. 27, 2022).
[3]A. Farahani, S. Voghoei, K. Rasheed, and H. R. Arabnia, ‘A Brief Review of Domain Adaptation’. arXiv, Oct. 07, 2020. Accessed: Dec. 27, 2022. [Online]. Available: http://arxiv.org/abs/2010.03978
[4]H. Guan and M. Liu, ‘DomainATM: Domain Adaptation Toolbox for Medical Data Analysis’. arXiv, Sep. 23, 2022. Accessed: Dec. 30, 2022. [Online]. Available: http://arxiv.org/abs/2209.11890
[5]M. Long, Y. Cao, J. Wang, and M. I. Jordan, ‘Learning Transferable Features with Deep Adaptation Networks’. arXiv, May 27, 2015. Accessed: Dec. 27, 2022. [Online]. Available: http://arxiv.org/abs/1502.02791
[6]M. Ghifary, W. B. Kleijn, M. Zhang, D. Balduzzi, and W. Li, ‘Deep Reconstruction-Classification Networks for Unsupervised Domain Adaptation’. arXiv, Aug. 01, 2016. Accessed: Dec. 27, 2022. [Online]. Available: http://arxiv.org/abs/1607.03516
[7]Y. Ganin et al., ‘Domain-Adversarial Training of Neural Networks’. arXiv, May 26, 2016. Accessed: Dec. 27, 2022. [Online]. Available: http://arxiv.org/abs/1505.07818
カーブジェン・エンジニアチームで一緒に働きませんか?
<募集ポジションはこちら>
<カジュアル面談希望はこちら>
https://carbgem.com/contact/
①お問い合わせ内容→「採用について」を選択
②必要事項をフォーム入力の上、「お問い合わせ内容詳細」に希望職種を明記