
AI生成画像の顔を自動修正する

手作業の顔修正を自動化してみたかった
キャラ作成時の作業手順
キャラ自体は作成済みなのですが、当時の手順をComfyUIで自動化できないかと挑戦しました。
当時のキャラ作成の手順は以下のフローのように書けます。よいキャラを出すための乱数選抜に加えて、顔を切り抜く位置やマスクを手で調整するのが手間でした。周回ゲーム用にとキャラを80人以上作ったので、数が多いのも大変でした。

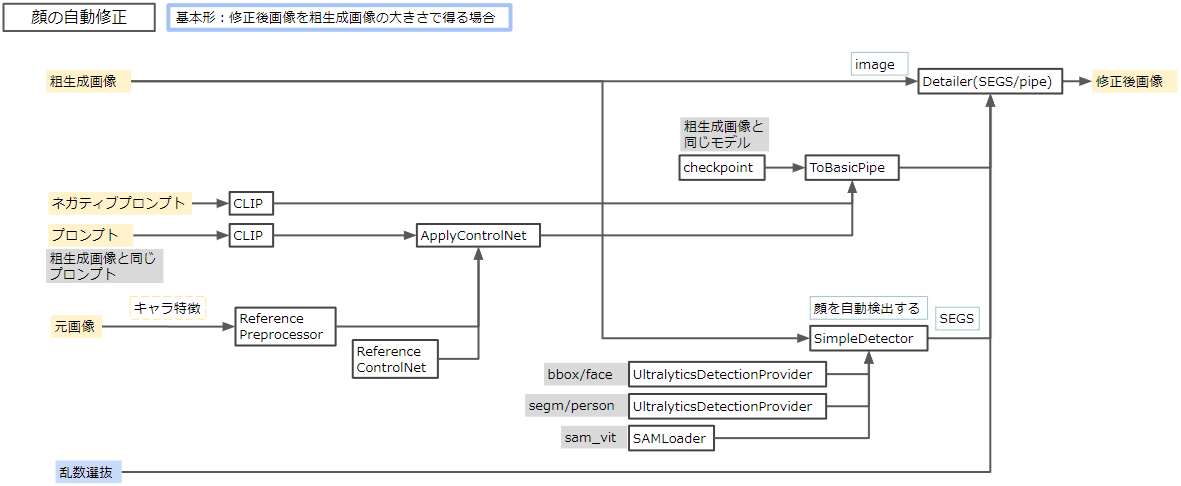
顔の自動修正
上記のうち、顔修正の部分を自動化したフローを考えました。
次の3つの処理を組み合わせます。
・顔を自動検出する
・修正前のキャラ絵から、キャラの特徴を抽出
・顔部分をimg2imgし、貼り付ける
フロー案
キャラの特徴については、以前使っていた自作GUIではテキストのプロンプトしか使えなかったのですが、ComfyUIではEmbeddingsやControlNetを使えます。
注意点として、モデルとプロンプトは修正元の生成画像と同一のものを使います。特に今回の場合、元画像は旧来のTrinArtモデル (trinart_stable_diffusion_v2) で生成したものなので、以降のテストでもTrinArtを使っています。
他のモデルを使っても動作はするのですが、修正後の顔が使ったモデルのものになります。その場合、修正というよりは書き換えに近いものになります。
ComfyUIワークフロー
考えたフローをComfyUIで組みました。

SimpleDetector, Detailer(SEGS) は ComfyUI-Impact-Pack に入っています。
Reference ControlNet は ComfyUI-Advanced-ControlNet に入っています。
いわゆる reference_only 相当の機能を持ちます。
結果
自動修正のテストでは、修正前の生成画像(512x512サイズ)を使いました。試したキャラはUnity関係の記事でもよく出ている子で、ある意味で看板娘です。
さて、顔検出時で使うSimpleDetectorでは、crop_factor(倍率)によって検出領域の周囲を含めて切り抜く大きさを変えられます。切り抜く量が変わるとimg2imgにかける画像が変わります。周囲をあまり含めないで画像を切り抜くと、そのぶん画像に顔の占める割合が増え、img2imgの精度が上がると予想されます。
そこでcrop_factorを振って顔の自動修正の結果を比べました。

しかし、いずれも顔の改善の度合いが少ないように感じました。これはDetailerの仕様が原因だと思います。
Detailerでimg2imgする際は、切り抜いた画像を単純に拡大してから生成処理を行います。そのため、
・大きく切り抜くと元画像と大きな差が出ない
→img2imgしても精細にならない
・小さく切り抜くと拡大率が大きい
→初期画像がぼやけ、出力結果が不安定
という挙動になりやすいです。
顔の自動修正(改良)
顔を拡大したいが顔がぼやけるのであれば、ぼやけない方法で画像を拡張、つまり画像拡張(アップスケール)すればよいです。手作業の手順でも行っていたことを自動化することにしました。
フロー案

ポイントとなるのは顔の寸法を自動で取得する方法と、拡張画像の作り方です。顔の寸法取得については、顔検出をこちらにも使うことにしました。修正前の画像について顔検出して顔の寸法を取得し、後段では拡張画像について顔検出をかけ、拡張した顔を切り抜きます。
拡張画像の作り方としては、まずReal-ESRGANを4倍固定で使って画像拡張し、その後所望の倍率になるように縮小します。この縮小率も自動で計算します。
ComfyUIワークフロー
改良版のフローをComfyUIで組みました。

縮小率の計算には WAS Node Suite の Number Operation 等の計算用ノードを使いました。

後段のSimpleDetectorでは dilation を増やし、検出領域がバラバラになりすぎないよう調整しました。

また、改良版のReference ControlNetでは、全身像のほうの特徴をReferenceにしました。顔のほうをReferenceにすると、ガタガタの領域を特徴として利用してしまい、顔がきれいに修正されませんでした。
結果
crop_factorを振って顔の自動修正の結果を比べました。


改良前と比べると改良後のほうが少し精細になりました。
しかし劇的に改善されたわけではありません。それと、改良前ほどではないものの、シード値を選抜して良い修正結果を探す作業は必要です(例えば上の場合、修正後の髪色があまりフィットしていない。表情も要検討)。
改良版のメリットを挙げるなら、副産物として大きな最終出力が得られることです。もともとは512x512の生成画像から840x1200の完成画像を作ろうとしていて、その事情においては、512x512→1200x1200へ拡張する工程を飛ばせる事は長所です。
とはいえ、現時点の生成エンジンとモデルであれば最初から840x1200の画像を作れるため、最終出力が大きくなることはメリットといえるほどのものではないです。
さらなる改良案
おそらくこれ以上粘っても劇的によくなるわけではないのですが、いくつか改良案があります。
・LineArt等の線画の特徴量をControlNetに追加する
・顔をimg2imgで修正する際、Detailerによる内部的な拡大を使わず、512x512(モデルの対応するサイズ)にサイズ指定して顔を切り抜く
後者について、現状では顔検出の結果をそのままDetailerに入力しています。Detailerを使う修正ではいくつか問題があります。
・512x512より小さな寸法の顔画像がDetailerに入力されると、Detailer内部でぼやけた拡大がかかる
・修正画像の色調が元画像と合わない場合や、マスクのぼかしが狭い場合、修正部分の境界が認識できてしまう。これはpixel領域で修正画像を貼り付けているため
対策として、Detailer内部で拡大させず、512x512の寸法に固定して顔を切り抜き、かつlatent領域でマスクをかける方式のimg2imgを行いたいです。
しかし検出結果をもとに顔を切り抜くには、SimpleDetectorの出力形式であるSEGSを解析し、顔を中心に所定の寸法で切り抜くような処理を実装する必要があります。Impact Pack独自のSEGSフォーマットの解析がすでに面倒そうで、さらにComfyUI上で実装する手間がかかりますが、その労力をかけるだけの改善が得られるのかどうか…
まとめ
生成画像の顔の自動修正をComfyUIで組みました。顔がimg2imgしやすい大きさになるよう画像拡張し、拡張後の画像を使ってimg2imgすることで、顔の修正が少し精細になりました。