
ChatGPTの中身はコナン君!? -LLMの仕組みをアナロジーする-

お久しぶりです。今回はChatGPTの仕組みについて考えていきたいと思います。
この記事の半分くらいは自分の考察で、裏付けのないものもあるので、そんな考えもあるんだーくらいで読んでください!(なんせ自分は建築学生なので)
1, ChatGPTの仕組み
大学の課題や文章生成、アイデアの壁打ち等々でお世話になりまくっているChatGPT。そんな、ChatGPTはどのようにして文章を生成しているのでしょうか?
ここでは、厳密な仕組みや厳密な数式を用いた説明はしません。あくまで、簡単な説明に留めます。
ChatGPTの内部で技術的にやっていることは、「次の単語を予測」して表示しているだけです。
「次の単語を予想する」そんな穴埋め問題をたくさん解く訓練をしていたら賢く(賢く見えるように)なったのです。
具体的に見ていきましょう。

ネット上にある多くのテキストデータを用いて、この「次の単語予測」をひたすら繰り返します。何億、何兆回もやるのです。
この反復の学習により、「次の単語の候補の確率」が最適な値になってきます。
おそらく、「この記事」も学習に使われるでしょう。(AIの成長に貢献!笑)
2, 次の単語を予測してるだけ、、、
先に見てきたようにChatGPT君は次の単語を予測し続けているだけです。
しかし、次のような出来事が起こっています。


・アメリカ数学オリンピック予選(AIME)の正解率 83.3%
・博士課程の学生レベル
・医師国家試験で正答率 98.2%
この他にも、普段のチャットで「こいつすげー」って何回もなります。
どうも次の単語を確率的に予測しているだけの「思考しないただの箱」になせる技とは考えにくいです。
本当にChatGPTは「単語と単語の関係」を表面的にただ学習しているだけなのでしょうか?
こんな疑問が生まれてきます。
3, 世界モデルを学習している
3.1 世界モデルを学習している
ここで、私が一番好きなAI研究者の紹介をします。元OpenAIのチーフサイエンティストである、Ilya Sutskeverさんです。

彼は「ChatGPTは世界モデルを学習している」と語ります。一体どういうことなのでしょうか。彼の言葉を引用し、見ていきましょう。
私たちが大量の異なるインターネット上のテキストから次の単語を正確に予測するように大規模なニューラルネットワークを訓練する際に行っていることは、実際には「世界モデル」を学習しているということです。一見すると、テキスト内の統計的な相関関係を学んでいるだけのように見えるかもしれません。しかし、テキスト内の統計的な相関関係を「ただ学ぶ」ため、つまりそれらを非常に効率的に圧縮するために、ニューラルネットワークはテキストを生み出したプロセスの何らかの表現を学んでいるのです。このテキストは実際には世界の投影なのです。
私はこれを最初に読んだとき、感動して崩れ落ちました。
では、彼は何をいっているのでしょうか。解説をしていきたいと思います。
まず、引用文の「テキスト内の統計的な相関関係を「ただ学ぶ」ため、つまりそれらを非常に効率的に圧縮するために」の部分が何を意味しているのか考えてみましょう。
先にも書いた通り、ChatGPTにとってゴールは次の単語を正確に予測することです。そのために、言語同士の関係のみを学び、そこから言語を生成しても良いのですが、それでは効率が悪いのです。日本語の単語数が10000を優に越していることを考えればそれは明らかでしょう。
どうにか効率良く学習したい。ChatGPT君はこう考えます。
(ChatGPT君にとって、次の単語の予測値と正解値が一致すれば良いので、どうやって予測するのかはどうでも良いし、(なら効率が良いものが採用されるのでは?)それを人間は指定できないのです。出力結果がなぜそうなるのか不明であるという、AIのブラックボックス問題が生じるのはこのためです。)
では、ChatGPTが行っている効率の良い方法とはなんなのでしょうか。
それは、「世界モデル」を学習することです。(Fig1)
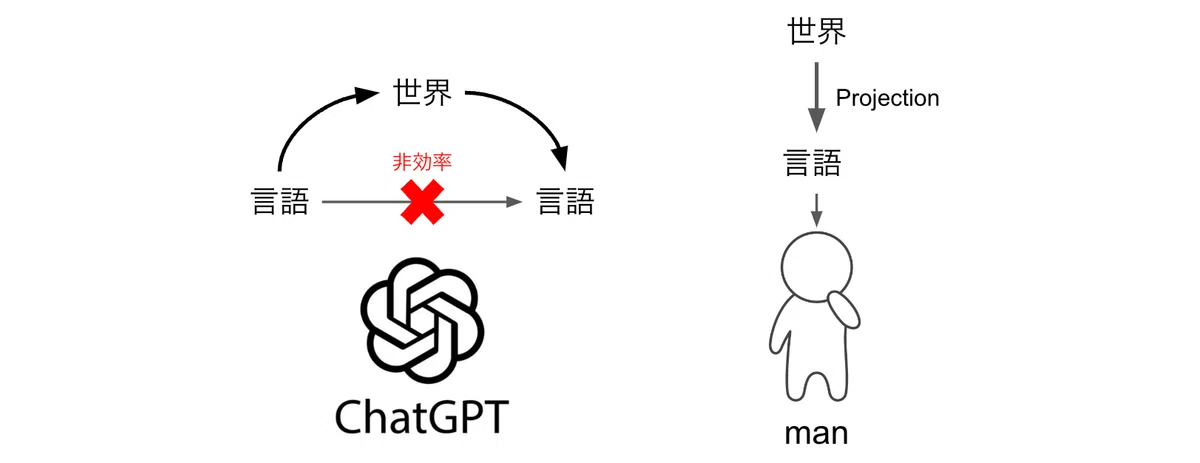
ChatGPT: 言語→世界→言語
人間: 世界→言語
人間は(感性で)体験している「世界(世界モデル)」を「言語」によって、理解し、思考し、他者と意思疎通し、共有し、表現し、記録として残します。(Fig1, Fig2-1,2)

言語を通じて互いの世界モデル1,2を共有する。そこから新しい世界モデル3を作る。
「言語」で会話をしているけど、会話をしているのは「世界」について
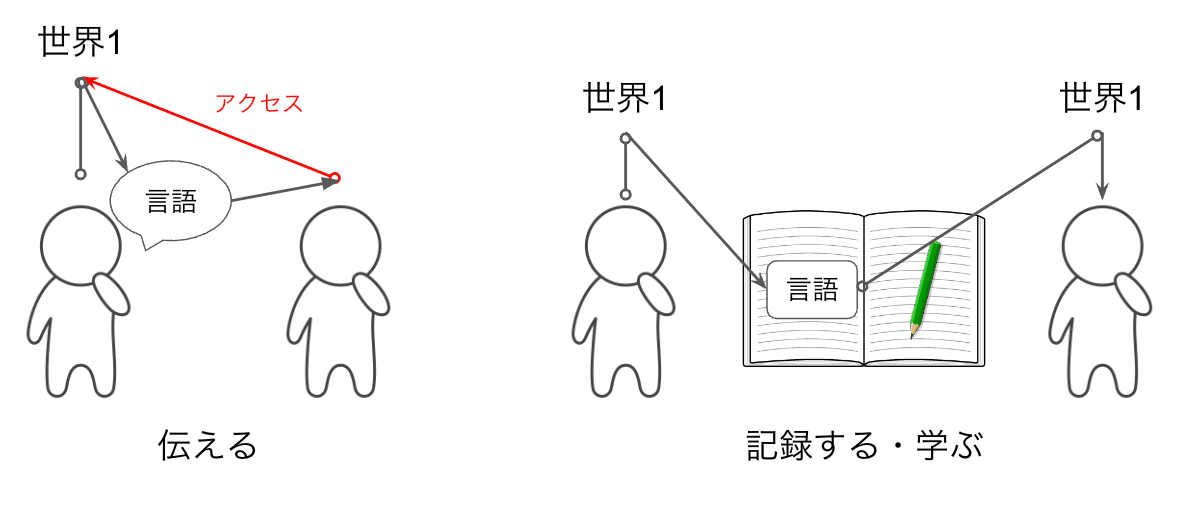
ChatGPT君の学習データである「言語」とは「世界」を表現・記録したものなのです。世界中70億人の人々が体験した多くの「世界」が「言語」という形に圧縮されており、ChatGPT君はそれを学習をしているのです。
少し、脱線になってしまうのですが、よく言われる「言語化」が大切な理由は上からも明らかですね。(相手は「言語」を介してでしか「世界モデル」を理解できない)また、一般教養(多様な世界モデルを知ること、世界モデルを表現する言語をたくさん知ること)が大切なのも明白です。
より多くの語彙を身につけることは、手持ちの絵の具が増えるようなものです。8色の絵の具で描かれた絵画と、200色の絵の具で描かれた絵画。どちらの絵が色彩豊かで美しいか?いわずもがな、200色のほうでしょう。語彙力を身につけることは、今まで8色でしか表現できなかった世界が、200色で表現できるようになるということなのです。
Ilyaさん引用文の「ニューラルネットワークはテキストを生み出したプロセスの何らかの表現を学んでいる」の「テキストを生み出したプロセス」が指すものとは、まさに「世界モデル」のことです。(Fig3)
引用文「このテキストは実際には世界の投影なのです。」からも分かるように、次の単語を予測するにはその文章に投影された世界というものを理解する必要があり、結果としてそれが次の単語を予測する手法として最適なのです。(Fig1)
ですから、学習時の「予測値と正解値の誤差を小さくする」とは「その言語の背後にある世界モデルを正確に捉える」ことと同値なのです。(Fig3)
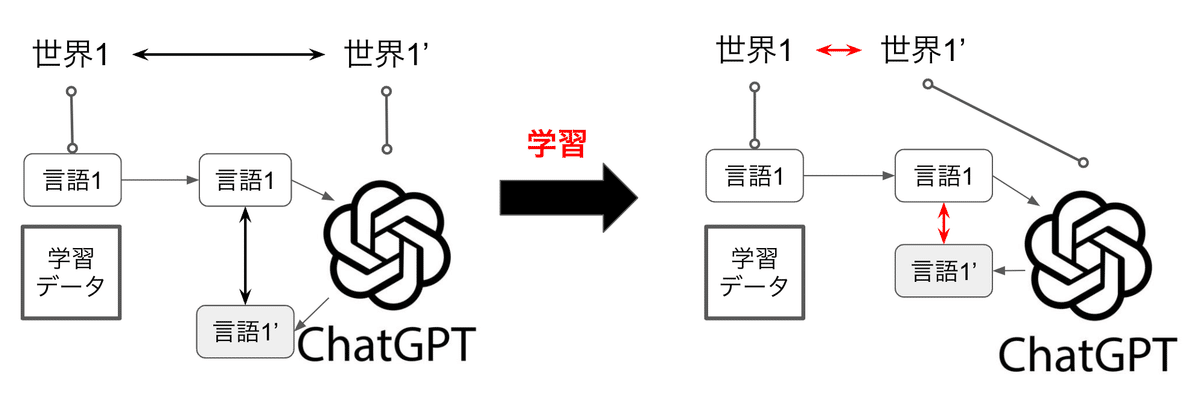
この章をまとめると以下のようになります。
次の単語を正確に予測するためには、ただ単に単語の出現頻度やパターンを記憶するだけでは不十分
その言語がどのように作られたか、つまり背景にある「世界モデル」(文脈や世界の知識)を学習
「世界モデル」は、言語を作り出す現実の世界の構造やルールそのものである。
言語の学習は結果的に、人間の知識や現実世界の概念を学ぶことに繋がっている
3.2 時空間表現を学習している
先に述べたブラックボックスの問題もあり、「ChatGPTは世界モデルを学習している」という仮説を正確に証明することができません。
しかし今日では、「モデル解釈性 (model interpretability)」や「説明可能なAI (Explainable AI, XAI)」といった「説明性」の研究が勧められており、少しずつ理解できるようになっております。
ChatGPTが内部で何を行っているのか、その説明を試みる研究に関して、
"LANGUAGE MODELS REPRESENT SPACE AND TIME"という論文を見つけました。
大規模言語モデル(LLM)の能力については、このようなシステムが単に膨大な量の表面的な統計を学習するだけなのか、あるいは現実世界を反映したより一貫性のある基礎的な表現を学習するのか、議論が巻き起こっている。我々は、世界、米国、ニューヨーク市の場所に関する3つの空間データセットと、歴史上の人物、芸術作品、ニュース見出しに関する3つの時間的データセットを用いて、Llama-2ファミリーのモデルの学習された表現を分析することで後者の証拠を発見した。これらのモデルは、複数のスケールにわたって空間と時間の線形的な表現を学習していることが明らかになった。この表現は、プロンプトの変動にも耐えうる堅牢さを持ち、都市やランドマークなど異なる種類のエンティティ間で統一されていることが確認された。さらに、空間座標や時間座標を安定して符号化する「空間ニューロン」や「時間ニューロン」を特定した。さらなる調査が必要であるものの、これらの結果は、現代のLLMが現実世界の豊かな時空間表現を学習しており、世界モデルの基本的な要素を備えていることを示唆している。
この論文によると、ChatGPT君は「時間」と「空間」(の表現)を学習していると語っています。
ドイツの哲学者カントは著書『純粋理性批判』において、次のように語ります。
「人間は、知覚したものを「空間」と「時間」の形式に当てはめ、その2つのフィルターを通して初めて対象を直感(≒認識)することが可能になる。」
そうです。「時間」と「空間」とはまさに我々が世界を認識する方法なのです。下の文章での「感性」とは、「時間」と「空間」という形式を通して受容する事を意味します。
人間は(感性で)体験している「世界(世界モデル)」を「言語」によって、理解し、思考し、他者と意思疎通し、共有し、表現し、記録として残します。(Fig1, Fig2-1,2)
つまり、下に示すように、1と2から3が導かれます。
世界モデル(我々が知覚する世界)は「時間と空間の形式に当てはめられたもの」である
ChatGPTは「時間と空間の表現」を学習している。
ChatGPTは世界モデルを学習している。
以上により、Ilyaさんと論文の2つでChatGPTが世界モデルを学習しているという事を考察できました。
*カントについて詳しく知りたい人はぜひこちらをお読みください!!
4, 次の単語を予測するということ
今までで、世界モデルを学習しているということを考察してきましたが、ここでは、そもそも次の単語を予測するとはどういうことか、正確に予測できることは何を意味するのか。についてわかりやすく考えてみたいと思います。(ようやくタイトル回収です笑)
つまりここでは、下が成り立つ理由について説明します。
学習時の「予測値と正解値の誤差を小さくする」とは「その言語の背後にある世界モデルを正確に捉える」ことと同値なのです。(Fig3)
ここでもすみません。Ilyaさんの言葉を引用させていただきます。
彼はこの理由について、天才的な説明をしてくれています。
なぜ次の単語の予測精度が高くなることがより深い理解、真の理解につながるのかを明確にするアナロジーを提供したいと思います。例を考えてみましょう。探偵小説を読んでいるとします。複雑なプロット、ストーリーライン、さまざまなキャラクター、多くの出来事、手がかりのような謎があって、はっきりしません。そして、本の最後のページで、探偵がすべての手がかりを集め、全員を集めて言います。「さて、犯罪を犯した人物の正体を明らかにします。その人の名前は_____です。」その単語を予測してください。
次の単語を予測するということは、ずばり「誰が犯人なのかを推理する」ことと同じなのです。
では、犯人を推理するために何が求められるでしょう?
もちろん、事件をよく理解することです。
探偵(犯人を推理)とChatGPT(次の単語を推理)には、以下のアナロジーが成立します。
事件をよく観察し、吟味し、類似事件(ないしは知識全般)からヒントをもらい、アリバイがあるのか考え、何が証拠で、誰の何の行動が不可解なのか、全てを整理して事件の全体像を把握する必要がある。
今まで出てきた単語をよく観察し、吟味し、類似事例(ないしは知識全般)からヒントをもらい、どの単語がどう文章に作用しているのか、全てを整理して背後にある世界モデルの全体像を把握する必要がある。
そうです。ChatGPTの中身はコナン君だったのです。(強引)

『犯人はあなたです!』と毛利小五郎(コナン)が決め台詞を放つと扉が閉まり、その間に入るCM中に犯人像をあれこれ考える私のように、ChatGPTは次の単語を推理しているのです。
5, スケーリング則
少し話は変わりますが、ChatGPTには「学習を大規模にしたらしただけ、性能が向上する」という面白い法則(スケーリング則)があります。
ここでは、スケーリング則とそれが何を意味するのかについて考えていきます。
5.1 スケーリング則
スケーリング則とは、「より複雑なAIモデル、より多くの学習データ、より長い学習時間を確保すればするほど、性能が向上する」ことをいいます。

モデルサイズ、データセットサイズ、トレーニングに使用する計算量を増やすにつれて、性能が向上する
ここで、グラフの縦軸の値がTestデータなのがポイントです。これはすごく奇妙なことなのです。
一般に、統計学・機械学習の分野において、モデルのパラメータ数を上げると過学習してしまうことがいわれています。「過学習とは、学習データにフィットし過ぎて、未知のデータに対応できない状態の事をいいます。」シンプルな曲線で良いのに、学習データにフィットさせようと15次関数を作ってしまうみたいなイメージです。(下写真)

では、ChatGPT君はモデルのパラメータ数を上げても、なぜ過学習しないのでしょうか?
5.2 絵の具を増やす
この問いに対しても、「世界モデルを学習しているから」という主張をしたいと思います。
3.1の世界モデルの説明のところで、齋藤孝さんのこんな言葉を引用しました。
より多くの語彙を身につけることは、手持ちの絵の具が増えるようなものです。8色の絵の具で描かれた絵画と、200色の絵の具で描かれた絵画。どちらの絵が色彩豊かで美しいか?いわずもがな、200色のほうでしょう。語彙力を身につけることは、今まで8色でしか表現できなかった世界が、200色で表現できるようになるということなのです。
ここにスケーリング則を説明するヒントが隠れていると私は考えました。
つまり、「より複雑なAIモデル、より多くの学習データ、より長い学習時間を確保すればするほど、性能が向上する」のは、
「より複雑なAIモデル、より多くの学習データ、より長い学習時間を確保すればするほど、絵の具の数が増える(世界モデルの解像度が上がる)」からではないでしょうか。
絵の具の数を増やしているだけなのです。過学習しない理由が直感的でわかりやすいと思います。
大規模な学習をすればするほど、ChatGPT君がもつ世界の解像度が上がるため、未知のデータに対しても、適切な予測ができるのです。
さらに、この説明で、ファインチューニングについても、「絵の具の数を部分的に増やす」と説明できます。
ファインチューニングとは
既存の機械学習モデル、特に大規模な事前学習済みモデルを、特定のタスクやデータセットに合わせて最適化するプロセスのこと。これにより、モデルは一般的な知識を持つ状態から、特定の用途に対して高い精度を発揮するように調整される。
6, マルチモーダル
世界モデルを学習することが、次の単語予測にとって重要であり、またこれからのAI技術の基盤を作っていく上で大切であるということを今まで扱ってきました。世界モデルを学習することがある意味で、ChatGPT君の目的であると言えます。
ここで、世界モデルを学習する方法は「言語」だけではないということについて考えます。
我々人間は一生の間にたった10億単語しか出会いません。これはAIが学習している単語数に比べてはるかに少ないです。
しかし、(現段階で)人間はAIより、世界モデルを正確に捉えれています。それは、私たちが世界をvisuallyに学習しているからです。
私たちの世界は非常にvisuallyであり、言語化できないものが、そこには多く存在しています。「視覚」による情報は世界モデルを学習をする上で、非常に役立つのです。
さらに言うと、言語だけしか扱えないAIは言語化できないものについて学ぶことができません。(学ぶのにとてつもなく苦労します。)
例えば、赤色とは何か。これを言語化するのはとても大変です。visuallyの恩恵を私たちは受けているのです。
赤色について、Wikipediaでは次のように説明されています。
赤は、光の可視スペクトルにおいて長波長端に位置する色であり、オレンジの隣で紫の反対側にある。支配的な波長はおおよそ625〜740ナノメートルである。
これでは赤色というものをイメージすることが難しいです。
一方、visuallyな情報だとパッと理解することができます。

ここで、重要になってくる技術が「マルチモーダル」です。
マルチモーダルとは、
複数の異なるモダリティ(形式)を組み合わせて情報を処理・統合すること。モダリティとは、人間や機械が情報を受け取ったり表現したりする方法を指し、たとえば視覚、聴覚、テキストなどが該当する。
今までChatGPT君の入力は「言語」だけでしたが、マルチモーダルでは、入力として「画像」が可能になるのです。
GPT-4がGPT-3と比べて大幅に性能が向上した要因の1つが、この「マルチモーダル」だとIlyaさんは語ります。
Visual(画像)によって、ChatGPT君は圧倒的に世界モデルの解像度が上がったわけです。

しっかり、画像の中の世界を捉えることができているように見えます。
今では以下のようなことも可能になっています。(ここで使われてるLLMはClaudeであり、ChatGPTではないですが、ChatGPTにも可能です)
This is wild.
— Min Choi (@minchoi) November 6, 2024
Just 2 weeks ago, Claude Computer Use dropped, and it's completely changing the AI assistants game
8 wild examples:
1. Claude, watch this site video, note issues & make a spreadsheet reportpic.twitter.com/deyKfuPffZ
7, まとめ
最後まで読んでいただきありがとうございます!!昨今のAIブームを引き起こした『ChatGPT』の仕組みについてざっくり理解していただけたでしょうか?
大学でAI分野を専攻しているわけでもない自分ですが、
「ChaGPTが魔法に見えた。勉強して明らかにしたい」
そんな知的好奇心をモチベーションとして、Pythonのprint("Hello, World!")からAIの勉強を始めました。これからもどんどん勉強して、AIの発展という『ドラマ』を特等席(最速)で閲覧し、皆さんにわかりやすく共有できるように頑張りたいと思います!!
これからの大AI時代を生きる皆さんの人生に少しでも貢献できれば幸いです。ありがとうございました。
Artificial Intelligence is nothing but "Digital Brain" inside large computer.
*この記事の参考動画はこちらです。