
データメッシュを勉強していく:データパイプラインの調整を減らす

分析屋の下滝です。
『Data Mesh』本を読みながらデータメッシュを勉強していきます。本来なら順番に解説していくのですが、全部読めていないし理解もしきれていないので、興味ある箇所から見ていきます。
前回は、データメッシュが達成したい2つ目のゴール「成長の中においてアジリティを保つの中」の「中央集権型のアーキテクチャのボトルネックを無くす」を見ていきました。
今回は、2つ目のゴール「成長の中においてアジリティを保つ」の中の「データパイプラインの調整を減らす」(p.113)を見ていきます。
データメッシュのゴール
データメッシュは、従来のデータアーキテクチャ(データウェアハウス、データレイクなど)のアプローチにおける問題点に対処するアプローチだと言えます。
従来のデータアーキテクチャのアプローチでは、以下の3点が長い間前提とされていました。この前提に問題があるというのが、議論の焦点になります。
・データを役立てるためには、データは中央集権化されて管理されなくてはならない。管理のための中央組織が存在する。
・データマネジメントのアーキテクチャ、技術、組織はモノリシックである。
・新たな技術がパラダイムを推進し、アーキテクチャと組織を形成する。
『Data Mesh』では、これらの点を踏まえて以下の図に示すゴールと、そのゴール達成のために行うことが整理されています。
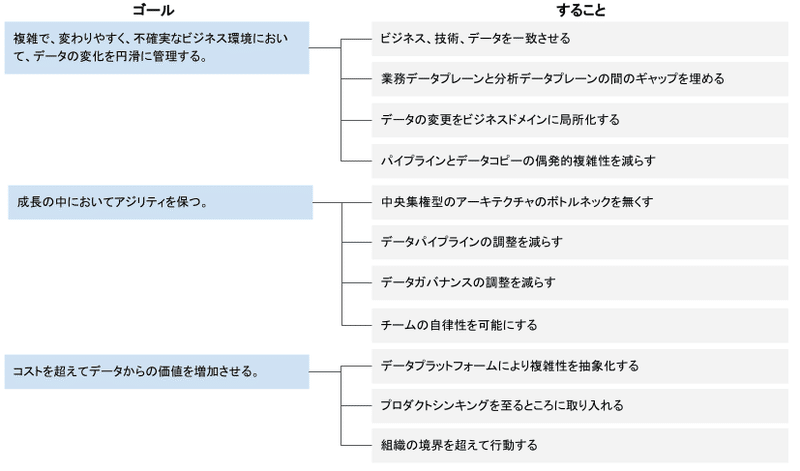
今回の記事では、2つ目のゴール「成長の中においてアジリティを保つ」の中の「データパイプラインの調整を減らす」(p.113)を見ていきます。
ゴール:成長の中においてアジリティを保つ
『Data Mesh』によれば(以下、ほぼ翻訳です)、ビジネスの成功は、その多面的な成長にかかっている、とされます。新たな買収、新たなサービスライン、新商品、地理的なの拡大などです。これらは、新しいデータソースの管理や新しいデータドリブンなユースケースの構築を意味します。
多くの組織は、成長するにつれて、データから価値を生み出すこと、新たなデータを取り込むこと、ユースケースに対応するのが遅くなっていきます。
成長の中においてアジリティを保つためのデータメッシュのアプローチは、いくつかのテクニックでまとめられます。組織全体にまたがるボトルネック、調整、同期を減らすことを目指すテクニックです。アジリティは、依存関係を最小限にして独立して結果を達成するビジネスドメインの能力に基づきます。
より具体的には、以下を行います。
1.中央集権型のアーキテクチャのボトルネックを無くす
2.データパイプラインの調整を減らす
3.データガバナンスの調整を減らす
4.チームの自律性を可能にする
今回の記事では、2つ目の「データパイプラインの調整を減らす」を見ていきます。
データパイプラインの調整を減らす
データメッシュは、従来のアーキテクチャで発生する以下の調整を減らします。
・アーキテクチャにおいて発生する調整
・人同士のやりとりが発生する調整
ただし、前回の記事でも触れたように、今回の内容も調整(coordination)に関する問題がテーマとなるのですが、調整自体の定義が明確ではないように思えました。
しかしながら、調整の対象となるアーキテクチャ要素は決まっており、データパイプラインです。
従来のデータアーキテクチャパターンである、データウェアハウスやデーレイクでは、データパイプラインは、技術軸(特定の機能)をもとにコンポーネントに分割されています。「インジェクト(取り込み)」「処理(変換)」「提供」といったコンポーネントへの分割です。
このような分割のスタイルでは、新しいデータソースや新しいユースケースが必要になったときに、すべてのコンポーネントにおいて調整が必要になります。というのも、機能を実装するコードの間の依存関係があるだけでなく、実際に実装するチーム間に依存関係があるためです。
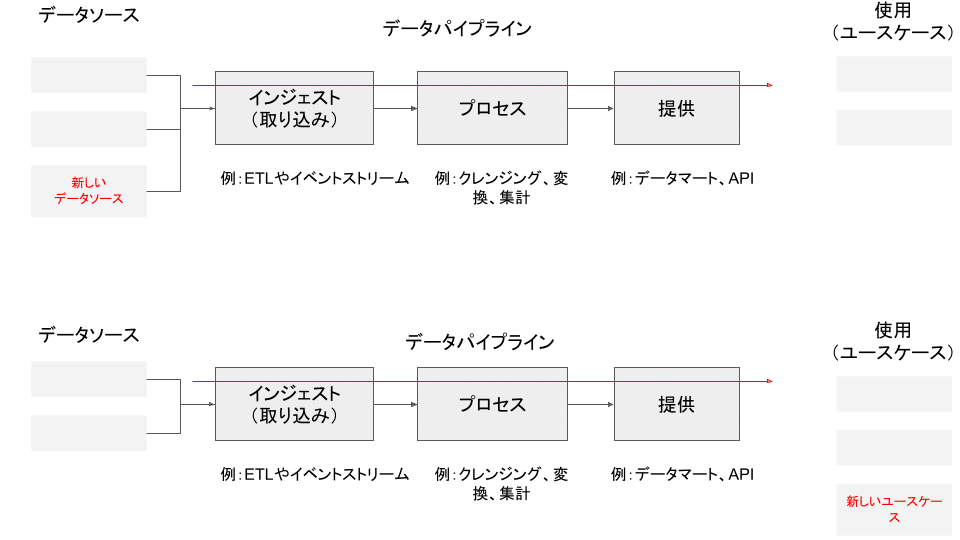
なお、この図では、新しいデータソースと新しいユースケースは、それぞれ別で発生することもあると示しました。データパイプラインに変更が及ぶとした場合に、ありえるパターンとしては以下だと思われます。
1.新しいデータソースが追加されて、データパイプラインに変更が及ぶ
2.新しいユースケースが必要とされて、データパイプラインに変更が及ぶ
3.新しいユースケースが必要とされて、新しいデータソースが追加されて、データパイプラインに変更が及ぶ
4.新しいデータソースが追加されて、新しいユースケースが必要とされて、データパイプラインに変更が及ぶ
実務としてそのどのケースが多いのかは、読者の方が判断してください。
さて、データメッシュでは、技術(機能)による分割ではなく、ドメインによる分割を行います。ここでいうドメインは、ドメイン駆動設計におけるドメインの概念です。各ドメイン内には、データプロダクトと呼ばれる、データメッシュにおけるアーキテクチャ要素が含まれます。

各データプロダクトは、内部の実装としてデータパイプラインを持ちます。
各データプロダクトは、そのドメイン内に関係するデータを、他のデータプロダクトやデータの消費者に提供・共有するためのインタフェース(アウトプットポートと呼ばれます)を公開します。図ではコントラクトとなっていますが、同じようなものだと思われます(厳密には異なると思われます)。
データプロダクトは、他のデータプロダクトとは独立して開発、進化することができます。
ドメインによる分割を行うことで、調整の必要性を削減することができます。多くのケースで、関係のあるドメインのデータプロダクトチームが、新しいユースケースでの新しいデータソースに対応します。関係のないドメインには、影響がありません。
もし、新しいユースケースがドメイン外の新しいデータプロダクトを必要とする場合は、次のようにできるようです。原文を理解しきれなかったので引用します。
… the consumer can make progress by utilizing the standard contracts of the new data product, mocks, stubs (https://oreil.ly/XV0zh), or synthetic data interfaces, until the data product becomes available.
そのデータプロダクトが実際に利用可能になるまで、データ消費者は新しいデータプロダクトの標準コントラクト、モック、スタブ、または合成データインターフェースを活用して進捗を遂げることができます。
以上のように、データメシュでは、新たなデータソースや新たなユースケースへの対応に伴う変化の範囲を特定の要素(データプロダクト)に局所化することで、アジリティを保とうとします。
最後に補足として、データプロダクトの内部の具体的な例は『Data Mesh』本では書かれていない(と思われる)のですが、『Data Mesh in Action』ではこのようなより具体的な例がありましたので紹介します。

「中央集権型のアーキテクチャのボトルネックを無くす」との違い
前回の記事を読んだ方は、今回の記事との違いが気になるかもしれません。
特に、中央集権的なアーキテクチャでなく、非中央集権的(分散)なアーキテクチャにするなら、データパイプライン自体も中央集権的な要素として残せないのではないか、という疑問が出るためです。
つまり、
・中央集権型のアーキテクチャのボトルネックを無くす(前回の記事)
・データパイプラインの調整を減らす(今回の記事)
は別々に扱えないテーマではないのか、と思えるためです。
今回は、直接この疑問に答えるわけではないのですが、考察を進めるにあたっての手がかりをもう少し議論します。
ベースとなる構造を以下に示します。中央集権型のアーキテクチャという意味です。中央にデータパイプラインがあると示しました。ここでは、変換コード(スクリプトなど)やストレージ(DWHやデータレイク)はデータパイプラインに含まれると考えています。
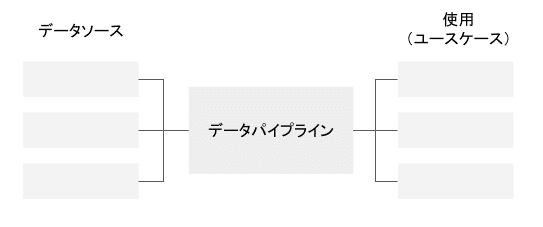
ソフトウェアエンジニアリング観点での疑問は、どのようにデータパイプラインを分解できるのか、です。ここではデータパイプラインの内部構造がどのようになっているのかに関して詳しく定義していません。別の言い方とするなら、どのような要素がどのように関係しているのかは定義していません。
抽象的には、データパイプラインは、今回の記事でみたように次のような要素(コンポーネント)で構成されると表現できます。

実際の企業での構造は、もちろん、具体的で複雑な依存関係からなる構造になります。
ここまで考えてきて、さて、どのようにさらに考えればいいのかと思っていると、とある有名な論文が思い浮かびました。
Parnasのモジュール化の論文です。どのような基準でシステムを要素(モジュール)に分解するのかに関しての古典的な論文です。1972年の論文なのでかなりの古さです。
On the criteria to be used in decomposing systems into modules (PDF)
(システムをモジュールに分解する際に使用すべき基準について)
今回の記事での文脈て当てはめると、データパイプラインをシステムと捉えた場合、どのように分解するのか、ということになります。あるいは、現状は、どのように分解されているのかということです。
論文をきちんとまだ読み直していないのですが、論文でここが関係するのではないか、という箇所を抜き出してみました(太字は私による)。異なる2つの分解方法について議論されています。
多くの読者は、各分解に使用された基準が何であったかを今、理解するでしょう。最初の分解において使用された基準は、処理の各主要なステップをモジュールとすることでした。最初の分解を得るためにはフローチャートを作る、と言ってもいいでしょう。これは分解またはモジュール化への最も一般的なアプローチです。これは全てのプログラマー教育の成果であり、私たちは粗いフローチャートから始めて、そこから詳細な実装に移るべきだと教えられています。フローチャートは、おおよそ5,000~10,000命令のオーダーでのシステムにとって有用な抽象概念でしたが、それを超えて進むと十分でないようです;何か追加的なものが必要です。
まさにデータパイプラインは、フローチャート的な分解だと言えるのかもしれません。このフローチャートのイメージがあったのでこの論文を思い出しました。
2つ目の分解です。
第二の分解は「情報隠蔽」[4]を基準として行われました。モジュールはもはや処理のステップに対応していません。たとえば、ラインストレージモジュールはシステムがほぼすべてのアクションで使用されます。アルファベット順のソートは、使用される方法によっては処理の段階に対応するかもしれないし、しないかもしれません。同様に、状況によっては、循環シフトはテーブルを一切作らず、要求されるごとに各文字を計算するかもしれません。第二の分解におけるすべてのモジュールは、それが他のすべてから隠している設計決定によって特徴づけられています。そのインターフェースまたは定義は、その内部の動作についてできるだけ少なく明らかにするように選ばれました。
情報隠蔽の概念を説明できるほど思い出せていないので、引用だけにしておきます。
さらに詳しい考察は、今後の記事で行いたいと思います。
株式会社分析屋について
ホームページはこちら。
noteでの会社紹介記事はこちら。
【データ分析で日本を豊かに】
分析屋はシステム分野・ライフサイエンス分野・マーケティング分野の知見を生かし、多種多様な分野の企業様のデータ分析のご支援をさせていただいております。 「あなたの問題解決をする」をモットーに、お客様の抱える課題にあわせた解析・分析手法を用いて、問題解決へのお手伝いをいたします!
【マーケティング】
マーケティング戦略上の目的に向けて、各種のデータ統合及び加工ならびにPDCAサイクル運用全般を支援や高度なデータ分析技術により複雑な課題解決に向けての分析サービスを提供いたします。
【システム】
アプリケーション開発やデータベース構築、WEBサイト構築、運用保守業務などお客様の問題やご要望に沿ってご支援いたします。
【ライフサイエンス】
機械学習や各種アルゴリズムなどの解析アルゴリズム開発サービスを提供いたします。過去には医療系のバイタルデータを扱った解析が主でしたが、今後はそれらで培った経験・技術を工業など他の分野の企業様の問題解決にも役立てていく方針です。
【SES】
SESサービスも行っております。