[備忘録] E資格対策 補講動画 (4/4): 自走できるAI人材になるための6ヶ月長期コース

今回は「キカガクさんの半年にわたる講義の備忘録」ではなく、受講する特典の「E資格対策用の補講動画」の備忘録 4記事目です。
備忘録
セクション15: 深層学習〜計算グラフ〜 (0h 53m)
・計算グラフとは
計算過程をグラフで表したもの
部分的(局所的)な計算のみに着目できる
・計算グラフを利用したBackward の計算方法の説明
足し算:そのまま前に戻す
掛け算:ひっくり返した値を掛け算
・セクション16 で実装する問題の説明
・Affine変換
この計算のこと「u = xW + b」
MatMul 行列の掛け算
b は1次元のものを2次元にするため Repeat
もっと詳しく知りたいならこの本を読んでくださいとのこと。
セクション16: 深層学習〜NN実装〜 (2h 01m)
Google Colaboratory & Numpy でNNを実装する
・入力層→中間層 (2→3)
・Sigmoid 関数 / ReLU 関数
・中間層→出力層 (3→2)
・Softmax 関数
over flow を防ぐ方法
複数パラメータかどうかで分岐が必要
・レイヤとしてまとめて行く(Class を使う)
ー変数 params / grads
ーメソッド forward / backward
・逆伝播の実装
Shallow copy / deep copy
self.grads[0][...] = dW
・Sigmoid / ReLU 関数の手書きノート
・Sigmoid / ReLU 関数の実装
非線形なのでx の情報を保持しておく必要あり
・Softmax with Loss
Cross entropy の実装
・最適化手法 (SGD 確率的勾配降下法) の実装
・NN関数をupdate する
重みWは0.01 をかけた値を初期値にすることが多い
b は初期値ゼロを初期値にすることが多い
for layer in reversed(self.layers)・iris データの読み込んでNNを実行する
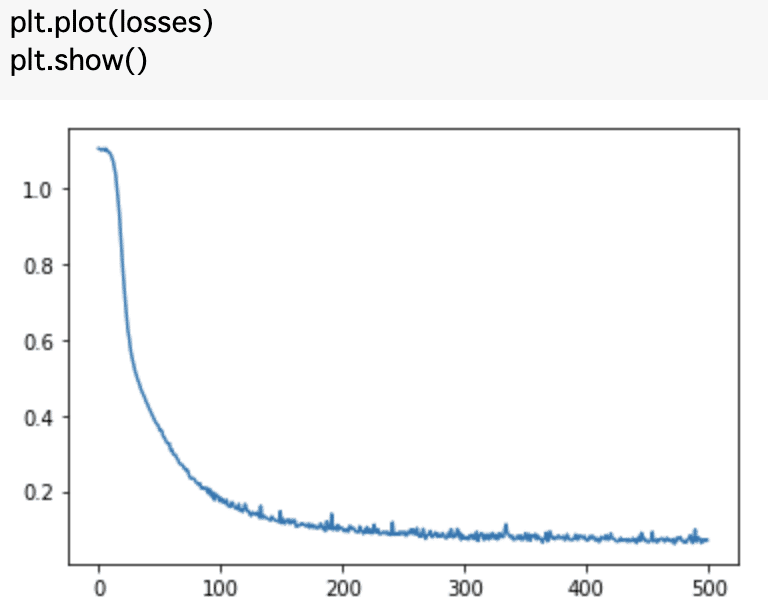
・推論を実施する
セクション17: 新シラバス (1h 28m)
・正規化
ー Batch Normalization
ー Layer Normalization
ー Instance Normalization
・モデル圧縮
モデルの性能を保ちながら軽量化すること
ー Pruning (枝刈り)
閾値以下の重みを0にする
ー Quantization (量子化)
学習済みモデルに対して適用する
ー Distillation (蒸留)
一度訓練したモデルの知識を別の軽量なモデルに継承する
教師モデル、生徒モデル
・分散処理
データ並列、モデル並列
GPU: Graphics Processing Unit
GPGPU: General Purpose computing on GPU
・MobileNet
ー Depthwise Separable Convolution
ー Pointwise Convolution
・DenseNet
Dense Block がポイント
成長率 (Growth Rate) Hyper Parameter: k
・Pix2Pix
スタイル変換を行う (生成モデル)
Conditional GAN の仲間
・WaveNet
Convolution を用いた音声生成
Dilated Causal Convolution
・Transformer (Attention を利用する)
時系列データを扱うNN
例) 機械翻訳
query key value / key & value = memory
Source - Target - Attention
Self - Attention (自己注意)
・AlphaGo
「深層学習+強化学習」を用いた囲碁プログラム
ー Policy Network: 次の一手を決定するDNN
SL Policy Network (Supervised Learning: 教師あり学習)
RL Policy Network (Reinforcement Learning: 強化学習)
ー Value Network
ー モンテカルロ木探索
ー 次の一手の勝率判定
「Rollout Policy によるプレイアウト」 + 「Value Network」