
画像生成AIモデル「Kolors」の使用経験

こんにちは、Browncatです。
中国のKuaishou Technology社(快手科技)は7月6日、画像生成AIモデル「Kolors」をリリースしました。
Kolorsは学習ネットワークはSDXLと同じくU-Netですが、テキストエンコーダとして、CLIPやT5ではなくChatGLM3を用いているのが特徴です。
そこでKolorsの生成結果を、Midjourney、DALL-E 3、Stable Diffusion 3(SD3) Medium、SD3系のStable Image Ultra、およびSDXLと相互比較してみました。(初版2024.7.17/改訂2024.8.1)
Kolorsの概要
Kolorsの論文「Kolors: Effective Training of Diffusion Model for Photorealistic Text-to-Image Synthesis」(KolorsのGitHubリポジトリに掲載)によれば、Kolorsの概要は以下の通りです。
テキストエンコーダとして、CLIPやT5ではなくChatGLM3-baseを採用。テキストは英語と中国語の両方に対応する。
ネットワークアーキテクチャはTransfomerではなく、SDXLで用いられているU-Netを用いる。
学習のため収集した画像のキャプションはノイズが多く不正確なため、テキストと画像のペアをマルチモーダル大規模言語モデル(MLLM)を用いてテキストと画像のペアを再キャプション化(DALL-E 3と同様のアプローチ)。
論文には各画像生成AIモデルが採用しているテキストエンコーダと対応する言語の一覧表があり、参考になります。

生成例
生成環境(ローカル)
Kolorsは、ComfyUIのラッパーが用意されていますので、当初はそれを利用させていただいていました。
記事初版発行後、何人かの方から、より汎用性の高いカスタムノードのセット「MinusZoneAI/ComfyUI-Kolors-MZ」を教えていただき、現在はこちらを利用しています。
教えてくださった西川和久さん(Xアカウント:@PhotogenicWeekE)と、AI画社さん(Xアカウント:@chinkanseki)のお二人に感謝いたします。
生成環境(オンライン)
なお、ComfyUI等のローカル生成環境がなくても、オンラインで手軽にKolorsを試せる方法があります。
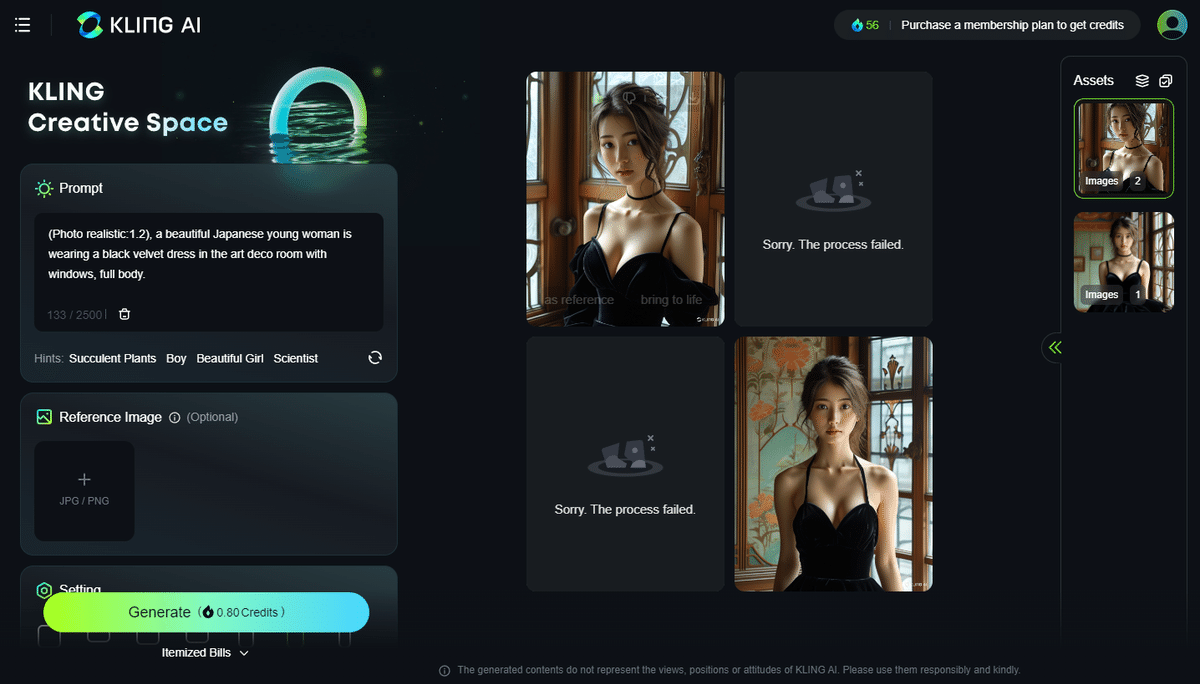
主にAI動画生成サイトとして知られている「Kling Creative Space」は、Kolorsと同じ開発元(快手)が運営しています。
このKling Creative Spaceは動画だけでなく静止画(AI Images)の生成にも対応していて、こちらで生成できる静止画がまさしくKolorsです。
登録制で(メールで登録可)、1回の生成当たり0.8クレジットを消費しますが、無料のクレジットが毎日60クレジット分与えられるため、よほど大量に生成しない限り、事実上無料で使えるといえるでしょう。
ここで生成したKolors画像は、もちろん、Klingの動画生成にも利用できます。
比較対象
Kolorsと比較するモデル・プラットフォームは、SDXLのほか、Kolorsが論文で画質(Multi-Dimensional Human Preference Score:MPS)のベンチマークに用いていたSD3、DALL-E 3、Midjourney V6とします。
ただしSD3ファミリーについては、Stable Diffusion 3 Mediumと、その上位のStable Image Ultraの両方を比較します。
Kolorsは他より画質がよいと訴えていますが、実際のところはどうでしょうか?
生成例は画像ごとにできるだけプロンプトを共通にしましたが、表現上の理由から、どうしても完全には同一にできなかったことをお許し願います。
また生成例の画像サイズはできるだけ896(W) x 1152(H)としましたが、DALL-E 3のみ1024(W) x 1024(H)としました。
KolorsのTIPS
KolorsはStable Diffusion(SD)に似ていますが、SDと異なり、ネガティブプロンプトをなくし、品質系プロンプトもなるべくシンプルにしたほうが良好な結果が得られるという所感があります。
1. 黒いドレスを着た女性
【Kolors】

相当に質感がある画像になっていて、衣装もベルベットの質感がよくされています。背景は窓付きのアール・デコ調の部屋と指定していますが、それらも再現されています。
プロンプト:
(Photo realistic:1.2), a beautiful Japanese young woman is wearing a black velvet dress in the art deco room with windows, full body.
【Stable Image Ultra】

SD3シリーズの最高峰なだけあって画質は間違いなく良いです。
Kolorsとどちらかが良いかといえば、好みは分かれると思いますが、表現の重厚さはStable Image Ultraのほうが若干上という印象です(他も含め)。ただし、Stable Image Ultraは有償ですが(生成1回あたり0.1USD)、Kolorsは無料(オープン)です。
Stable Image Ultraは表現規制の影響なのか、衣装プロンプトとして「black velvet dress」とただ書くと多くの場合露出度ゼロの冬のドレスが生成されます。そのためStable Image Ultraでは、衣装のプロンプトを「sleeveless summer black velvet dress」としています(cleavageはAPI版では禁止ワードにされています)。
プロンプト:
【Positive】 cinematic photo, a beautiful Japanese young woman is wearing a sleeveless summer black velvet dress in the art deco room with windows. 35mm photograph, film, bokeh, professional, 4k, highly detailed
【Negative】 drawing, painting, crayon, sketch, graphite, impressionist, noisy, blurry, soft, deformed, ugly
【Stable Diffusion 3 Medium】

表現規制やライセンス問題でいろいろと非難されているStable Diffusion 3 Mediumですが、ベースモデルの画質に関しては、リリース直後のSDXLベースよりはるかに良いことを強調します(以前に別記事でStable Diffusion 3 MediumとSDXLのベースの比較をしました)。
ただし、Kolorsとの比較になると、やはり表現の細やかさでKolorsのほうがStable Diffusion 3 Mediumより上と思います。
Medium固有の問題として、ポートレートやクローズアップの画像が作りにくいというのがあります。そのためプロンプトに「(closeup:1.8)」をわざわざ入れています。
プロンプト:
【Positive】 cinematic photo, a beautiful Japanese young woman is wearing a black velvet cleavage dress in the art deco room with windows, (closeup:1.8). 35mm photograph, film, bokeh, professional, 4k, highly detailed
【Negative】 drawing, painting, crayon, sketch, graphite, impressionist, noisy, blurry, soft, deformed, ugly
【DALL-E 3】

DALL-E 3は、OpenAIのChatGPT4oを利用して生成しました。
DALL-E 3はプロンプト理解力が高い一方で、以前はフォトリアルな表現が苦手で、プロンプトに「Photo realistic」と書いてもなかなかイラスト感が抜けなかったのですが、最近はだいぶ改善されてきました。
それでもKolorsと比較すると、まだリアル感が物足りません。
プロンプト:
Photo realistic, a beautiful Japanese young woman is wearing a black velvet dress in the art deco room with windows, full body.
【Midjourney V6】

この画像に関していえば、画質はKolorsよりMidjourney V6のほうが断然上です。
ただし一般的には、Midjourneyは画像とプロンプトの内容によって得意不得意があります。
Kolorsの論文では画質を表すMPS値がMidjourneyよりKolorsのほうがわずかに上となっています。Midjourneyのいいほうの画像をみると、そんなことはないだろうとも思えますが、Midjourneyはばらつきのある生成結果で評価したのかもしれません。
なおMidjourney V6の生成にあたり、パラメータ値は下記のように、バージョン(--v)とアスペクト比(--ar)に限定し、Stylization, Weirdness, Variety等の品質系パラメータは指定せず、全部デフォルトにしました。
プロンプト:
Photo realistic, a beautiful Japanese young woman is wearing a black velvet dress in the art deco room with windows, full body --v 6.0 --ar 3:4
【SDXL】

SDXLのリリースから1年近く経過しましたが、最近も、ベースモデルよりはるかに表現力が高いモデルが日々登場し続けています。
そこで今回はSDXLベースモデルではなく、比較的最近のモデルで比較いたします。
この画像は とーふのかけら さんが開発したモデル「VoidnoiseCoreXL_R1892」を用いて生成したものです。
結果としては、Stable Diffusion 3 Mediumを上回る画質が得られています。ではKolorsとどちらが良いかは、こちらの画像については甲乙つけがたいです。
プロンプト:
【Positive】 cinematic photo a beautiful Japanese young woman is wearing a black velvet dress in the art deco room with windows. . 35mm photograph, film, bokeh, professional, 4k, highly detailed
【Negative】 drawing, painting, crayon, sketch, graphite, impressionist, noisy, blurry, soft, deformed, ugly
2. かき氷と女性
【Kolors】

こちらも、質感の高いフォトリアルな画像が生成されていて、特に透明なグラスに入ったかき氷の表現が秀逸です。しかもここには示しませんが、シードをかえて生成しても比較的安定な表現が得られます。
なお「かき氷」はプロンプトでは「Hawaiian shaved ice」としています(他も同様)。
プロンプト:
(Photo realistic:1.2), the Japanese young woman like a kawaii idol in ice blue frilled dress is sitting at the table and (Hawaiian shaved ice:1.2) is put on the table in front of shaved ice store, looking at viewer, smile
【Stable Image Ultra】

人物の質感はKolorsより上です。かき氷の表現についても良好ですが、若干Kolorsより苦手かなという印象。
プロンプト:
【Positive】 cinematic photo, the Japanese young woman like a kawaii idol in ice blue frilled dress is sitting at the table and one medium-size Hawaiian shaved ice is put on the table in front of shaved ice store, looking at viewer, smile. 35mm photograph, film, bokeh, professional, 4k, highly detailed
【Negative】 drawing, painting, crayon, sketch, graphite, impressionist, noisy, blurry, soft, deformed, ugly
【Stable Diffusion 3 Medium】

こちらも黒いドレスと同様、Kolorsのほうが画質が上と感じます。
プロンプト:
【Positive】 cinematic photo, the Japanese young woman like a kawaii idol in ice blue frilled cleavage dress is sitting at the table and one small Hawaiian shaved ice is put on the table in front of shaved ice store, looking at viewer, smile, (closeup:1.8). 35mm photograph, film, bokeh, professional, 4k, highly detailed
【Negative】 drawing, painting, crayon, sketch, graphite, impressionist, noisy, blurry, soft, deformed, ugly
【DALL E-3】

フォトリアリズムという観点からすればKolorsのほうが上ですが、一方で、人物のしぐさや表現の明晰さ、文字画像の生成という点では、DALL-E 3のほうが好印象という結果になります。
プロンプト:
photo realistic, the Japanese young woman like a kawaii idol in ice blue frilled dress is sitting at the table and Hawaiian shaved ice is put on the table in front of shaved ice store, looking at viewer, smile
【Midjourney V6】

Midjourneyらしさを非常に感じる画像です。こちらとKolors、Stable Image Ultra、DALL-E 3とどれが良いかは、もはや好みによるのではないでしょうか。
プロンプト:
photo realistic, the Japanese young woman like a kawaii idol in ice blue frilled dress is sitting at the table and Hawaiian shaved ice is put on the table in front of shaved ice store, looking at viewer, smile --v 6.0 --ar 3:4
【SDXL】

こちらもSDXLベースモデルではなく、比較的最近のモデルで比較いたします。
本例は こたじろう さんが開発したモデル「tsubakiMix_v15」を用いて生成したものです。
結果としてはやはりKolorsに匹敵する画像が得られていますが、かき氷に限っていえば、Kolorsのほうが若干良いです。
プロンプト:
【Positive】 cinematic photo a beautiful Japanese young woman is wearing a black velvet dress in the art deco room with windows. . 35mm photograph, film, bokeh, professional, 4k, highly detailed
【Negative】 drawing, painting, crayon, sketch, graphite, impressionist, noisy, blurry, soft, deformed, ugly
中国語対応
Kolorsは英語だけでなく中国語のプロンプトにも対応しているということで、試しに唐の詩人・李白の詩「採蓮曲」の前半をそのままプロンプトにして生成した結果を示します。

プロンプト(下記参照)に書かれた詩の内容の通り、蓮摘みの女性が背景の蓮や反射する日の光とともに見事に表現されています。
プロンプト:
写实
若耶溪边采莲女,笑隔荷花共人语。
日照新妆水底明,风飘香袂空中举。
注:「写实」は「フォトリアル」を意味する前置プロンプトで、詩の内容と無関係です。
プロンプトに利用した詩の日本語訳は以下の通りです。日本語訳はこちらを参考にしました。
若耶溪のほとりで、蓮を採る女たち、 笑い、さざめき、蓮の花ごしに語りあう。 日の光は、化粧したての姿を照らして、明るく水中に写し出し、 流れる風は、香しい袖をひるがえして、高く空中に吹き抜ける。
「採蓮曲」全文の簡体字による記述と解題については、こちらのページをご覧ください(中国語)。
ちなみに「採蓮曲」は日本語訳の文献にあるように、エルヴェ=サン=ドニのフランス語訳、ハイルマンとベトゲのドイツ語訳を経て、マーラー「大地の歌」の第4楽章に採用された経緯があります。
詩の後半は、男子たちが登場して複雑な情景になるため、今回はプロンプトに含めませんでした。
他の生成例(Kolorのみ)
Kolorsの他の生成例を、他のモデルとの比較をせずにいくつか掲載します。
1「オーディオ好き」
AIbijoさんの「AI青春コンプレックス」イベントに投稿した作品です。

2 「カラフルな衣装のバレエダンサー」

まとめ
Kolorsを他のモデル・プラットフォームと比較し、その画質がStable Diffusion 3 Mediumのベースを上回り、Stable Image UltraやMidjourney V6に迫る画質であることがわかりました。
また中国語プロンプトの有効性も確認しました。
Kolorsの功績は、画像生成AIのネットワーク構造はSDXLから変えずに、テキストエンコーダの改良と、再キャプション化によって高画質なモデルを構築できたことでしょう。
この記事が気に入ったらサポートをしてみませんか?