文系かつ体育会系がPythonを学び、 シェアサイクルの利用に与える要素を分析してみた。

■ 目次
はじめに
実行環境
利用予測の流れ
具体的なコードの記述
モデルの構築
考察
終わりに
1.はじめに
私は学生時代の16年間を野球一筋で生きてきた満29歳のサラリーマンです。今が人生史上最も勉強し、机とパソコンに向かっている日々をすごしています。これまで知らなかった世界を学び知ることができるのが楽しいと感じる日々です。
シェアサイクルに関わる仕事をすることがあり、次第にシェアサイクルへの興味が増していきました。奥深いシェアサイクルを分析することができるのはpythonであると知り、プログラミングに対しても興味を抱きました。
また、プログラミングをスキルとして身に着け、会社や組織に依存しない個人になりたいと思っています。
pythonを学びながら、シェアサイクルの分析ができるという一石二鳥の状態をAidemyで叶え、実際にトライしてみました。
シェアサイクルという言葉が日常に定着してきたと感じる近年、シェアサイクルは人々の生活に欠かせない移動手段になりつつあるのではないでしょうか。様々な場面で活躍する移動手段ではあるが、利用されるためにはどんな条件を満たせばいいのか、利用される条件を様々な視点で分析し予測してみたいと思います。
2.実行環境
PC:Lenovo Think Book
環境:Colaboratory
Python ver : 3.8.5
3.利用予測の流れ
kaggleからサンプルデータ取得
データクレンジング・前処理等はkaggleを参考に実施
サンプルデータを可視化
サンプルデータの利用状況の把握と相関分析
機械学習による予測の実施
4.具体的なコードの記述
サンプルデータ
#必要なライブラリをインポート
import pylab
import calendar
import numpy as np
import pandas as pd
import seaborn as sn
from scipy import stats
import missingno as msno
from datetime import datetime
import matplotlib.pyplot as plt
import warnings
pd.options.mode.chained_assignment = None
warnings.filterwarnings("ignore", category=DeprecationWarning)
%matplotlib inline#データ読み込み
dailyData = pd.read_csv("/content/train.csv")
#データセットの形状
dailyData.shape
#最初の数行のサンプル確認
dailyData.head(2)
#カラムの変換・追加作成
dailyData["date"] = dailyData.datetime.apply(lambda x : x.split()[0])
dailyData["hour"] = dailyData.datetime.apply(lambda x : x.split()[1].split(":")[0])
dailyData["weekday"] = dailyData.date.apply(lambda dateString : calendar.day_name[datetime.strptime(dateString,"%Y-%m-%d").weekday()])
dailyData["month"] = dailyData.date.apply(lambda dateString : calendar.month_name[datetime.strptime(dateString,"%Y-%m-%d").month])
dailyData["season"] = dailyData.season.map({1: "Spring", 2 : "Summer", 3 : "Fall", 4 :"Winter" })
dailyData["weather"] = dailyData.weather.map({1: " Clear + Few clouds + Partly cloudy + Partly cloudy",\
2 : " Mist + Cloudy, Mist + Broken clouds, Mist + Few clouds, Mist ", \
3 : " Light Snow, Light Rain + Thunderstorm + Scattered clouds, Light Rain + Scattered clouds", \
4 :" Heavy Rain + Ice Pallets + Thunderstorm + Mist, Snow + Fog " })
#データ変換
categoryVariableList = ["hour","weekday","month","season","weather","holiday","workingday"]
for var in categoryVariableList:
dailyData[var] = dailyData[var].astype("category")
#カラムの削除
dailyData = dailyData.drop(["datetime"],axis=1) 
matplotlib・seabornライブラリを活用した可視化
fig, axes = plt.subplots(nrows=2,ncols=2)
fig.set_size_inches(12, 10)
sn.boxplot(data=dailyData,y="count",orient="v",ax=axes[0][0])
sn.boxplot(data=dailyData,y="count",x="season",orient="v",ax=axes[0][1])
sn.boxplot(data=dailyData,y="count",x="hour",orient="v",ax=axes[1][0])
sn.boxplot(data=dailyData,y="count",x="workingday",orient="v",ax=axes[1][1])
axes[0][0].set(ylabel='Count',title="Box Plot On Count")
axes[0][1].set(xlabel='Season', ylabel='Count',title="Box Plot On Count Across Season")
axes[1][0].set(xlabel='Hour Of The Day', ylabel='Count',title="Box Plot On Count Across Hour Of The Day")
axes[1][1].set(xlabel='Working Day', ylabel='Count',title="Box Plot On Count Across Working Day")
df_pivot = dailyData.pivot_table(index='season',values=['casual'], aggfunc='sum')
df_pivot2 = dailyData.pivot_table(index='season',values=['registered'], aggfunc='sum')
order_df = pd.merge(df_pivot, df_pivot2, left_on="season", right_index=True, how="inner")
print(order_df)
order_df.plot(kind="bar",figsize=(15,8))
#plt.ylim(4000,500000)
plt.show()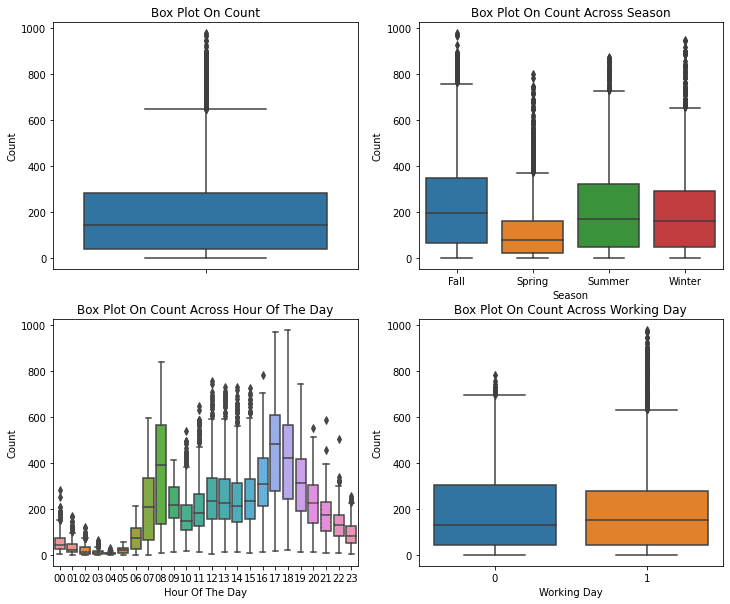

グラフから読み取れるのは下記の事項。
・春季は相対的に利用が少ない。
・中央値は午前7時から午前8時と午後5時から午後6時にかけて相対的に高くなっている。
・ 異常値の多くは「非稼働日」よりも「稼働日」に寄与している。
・季節に変わりなく、registered(登録者)の利用が70%以上を占めている。
#外れ値の除去
dailyDataWithoutOutliers = dailyData[np.abs(dailyData["count"]-dailyData["count"].mean())<=(3*dailyData["count"].std())]
#要素数の確認
print ("Shape Of The Before Ouliers: ",dailyData.shape)
print ("Shape Of The After Ouliers: ",dailyDataWithoutOutliers.shape)#相関分析
corrMatt = dailyData[["temp","atemp","casual","registered","humidity","windspeed","count"]].corr()
mask = np.array(corrMatt)
mask[np.tril_indices_from(mask)] = False
fig,ax= plt.subplots()
fig.set_size_inches(20,10)
sn.heatmap(corrMatt, mask=mask,vmax=.8, square=True,annot=True, cmap='GnBu')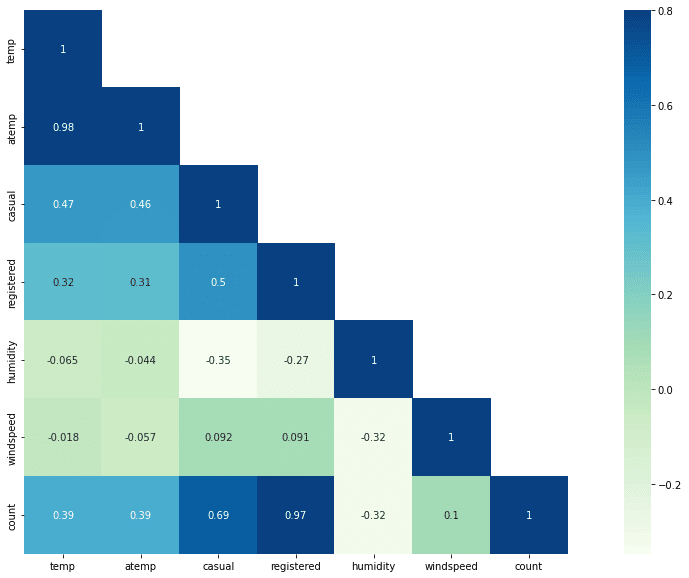
#相関分析
fig,(ax1,ax2) = plt.subplots(ncols=3)
fig.set_size_inches(12, 5)
sn.regplot(x="temp", y="count", data=dailyData,ax=ax1, color='Brown')
sn.regplot(x="humidity", y="count", data=dailyData,ax=ax2)
利用に与える["temp", "atemp", "humidity"]の相関分析の実施。
tempとhumidityはそれぞれ利用と正負の相関があり、両者の相関はあまり顕著ではありませんが、利用はtempとhumidityに少し依存していることがわかります。
seabornの回帰プロットは、2つの特徴量の関係を表す便利な方法の1つである。ここでは、利用と "temp", "humidity", を考えてみます。
fig,(ax1,ax2,ax3,ax4)= plt.subplots(nrows=4)
fig.set_size_inches(12,20)
sortOrder = ["January","February","March","April","May","June","July","August","September","October","November","December"]
hueOrder = ["Sunday","Monday","Tuesday","Wednesday","Thursday","Friday","Saturday"]
monthAggregated = pd.DataFrame(dailyData.groupby("month")["count"].mean()).reset_index()
monthSorted = monthAggregated.sort_values(by="count",ascending=False)
sn.barplot(data=monthSorted,x="month",y="count",ax=ax1,order=sortOrder, palette='Set3')
ax1.set(xlabel='Month', ylabel='Avearage Count',title="Average Count By Month")
hourAggregated = pd.DataFrame(dailyData.groupby(["hour","season"],sort=True)["count"].mean()).reset_index()
sn.pointplot(x=hourAggregated["hour"], y=hourAggregated["count"],hue=hourAggregated["season"], data=hourAggregated, join=True,ax=ax2, palette='Set2')
ax2.set(xlabel='Hour Of The Day', ylabel='Users Count',title="Average Users Count By Hour Of The Day Across Season",label='big')
hourAggregated = pd.DataFrame(dailyData.groupby(["hour","weekday"],sort=True)["count"].mean()).reset_index()
sn.pointplot(x=hourAggregated["hour"], y=hourAggregated["count"],hue=hourAggregated["weekday"],hue_order=hueOrder, data=hourAggregated, join=True,ax=ax3)
ax3.set(xlabel='Hour Of The Day', ylabel='Users Count',title="Average Users Count By Hour Of The Day Across Weekdays",label='big')
hourTransformed = pd.melt(dailyData[["hour","casual","registered"]], id_vars=['hour'], value_vars=['casual', 'registered'])
hourAggregated = pd.DataFrame(hourTransformed.groupby(["hour","variable"],sort=True)["value"].mean()).reset_index()
sn.pointplot(x=hourAggregated["hour"], y=hourAggregated["value"],hue=hourAggregated["variable"],hue_order=["casual","registered"], data=hourAggregated, join=True,ax=ax4, palette='Set2')
ax4.set(xlabel='Hour Of The Day', ylabel='Users Count',title="Average Users Count By Hour Of The Day Across User Type",label='big')
月別、季節別、時間別、平日別、利用者別に利用回数を可視化の実施。
6月、7月、8月が比較的需要が高いことがわかます。
平日の午前7時~8時、午後5時~6時の間にレンタサイクルを利用する人が多いことがわかります。平日の午前7時〜8時、午後5時〜6時は通勤通学の利用が多いことが考えられる。土曜日と日曜日はこのパターンは見られず、午前10時から午後4時までの間に借りる人が多い。 午前7時〜8時、午後5時〜6時の間は、純粋に登録ユーザーによる利用がピークとなっています。
5.モデルの構築
これまでの可視化等はkaggleを参考に進めましたが、モデルの構築についてはAidemyの「データ分析講座」にあった「教師あり学習(回帰)」の学習と課題を参考に実施してみました。
初回コード
学習した内容をもとに複数モデルからベストなモデルを導いていくことを目的に実施。エラーが多発しトライアンドエラーの連続。。。
ようやくエラーがなく機能した実際のコードがこちら。
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import Ridge
dataTrain = pd.read_csv("/content/train.csv")
dataTest = pd.read_csv("/content/test.csv")
data = dataTrain.append(dataTest)
data.reset_index(inplace=True)
data.drop('index',inplace=True,axis=1)
data = data.dropna(how='all')
X_train, X_test, y_train, y_test = train_test_split(data.drop('count', axis=1),data['count'], random_state=42)
X_train.head(10)
print(X_train.shape)
X_train = X_train.drop(['datetime',"casual","registered"], axis=1)
print(X_train)
y_train = y_train.fillna(y_train.mean())
print(y_train)
print(X_test.shape)
X_test = X_test.drop(['datetime',"casual","registered"], axis=1)
print(X_test)
y_test = y_test.fillna(y_test.mean())
print(y_test)
max_score = 0
best_model = ""
#線形回帰
model = LinearRegression()
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
if max_score < score:
max_score = score
best_model = "線形回帰"
#ラッソ回帰
model = Lasso()
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
if max_score < score:
max_score = score
best_model = "ラッソ回帰"
#リッジ回帰
model = Ridge()
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
if max_score < score:
max_score = score
best_model = "リッジ回帰"
print("モデル:{}".format(best_model))
print("決定係数:{}".format(max_score))●結果
モデル:リッジ回帰
決定係数:0.16
かなり低い数値に。。。
2回目コード
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import Ridge
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
dataTrain = pd.read_csv("/content/train.csv")
dataTest = pd.read_csv("/content/test.csv")
data = dataTrain.append(dataTest)
data.reset_index(inplace=True)
data.drop('index',inplace=True,axis=1)
data = data.dropna(how='all')
#正規化
data["temp"] = data["temp"] / data["temp"].max()
data["humidity"] = data["humidity"] / data["humidity"].max()
data["windspeed"] = data["windspeed"] / data["windspeed"].max()
#ワンホットエンコーディング
data2 = pd.get_dummies(data, columns=['season', 'weather'])
print(data2)
X_train, X_test, y_train, y_test = train_test_split(data2.drop('count', axis=1),data2['count'], random_state=42)
print(X_train.shape)
X_train = X_train.drop(['datetime',"casual","registered"], axis=1)
print(X_train)
y_train = y_train.fillna(y_train.mean()) #ラベルがないところは消すor0にする
print(y_train)
print(X_test.shape)
X_test = X_test.drop(['datetime',"casual","registered"], axis=1)
print(X_test)
y_test = y_test.fillna(y_test.mean())
print(y_test)
max_score = 0
best_model = ""
#線形回帰
model = LinearRegression()
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
if max_score < score:
max_score = score
best_model = "線形回帰"
#ラッソ回帰
model = Lasso()
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
if max_score < score:
max_score = score
best_model = "ラッソ回帰"
#リッジ回帰
model = Ridge()
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
if max_score < score:
max_score = score
best_model = "リッジ回帰"
print("モデル:{}".format(best_model))
print("決定係数:{}".format(max_score))初回のモデルでは「正規化」の未実施、”season”,"wather"が「カテゴリカルデータ」のままであったことから修正を実施。決定係数の向上を目指しコードの修正を行った。
●結果
モデル:線形回帰
決定係数:0.17
数値の向上にあまりつながらない結果に。。。
モデルの構築については奥が深く、何度もデータの修正を行っていくことが必要だと実感しました。データをよく理解し見ることが重要であることも実感。何を求めたいのか目的をはっきりさせることも大切だと体験しました。
6.考察
モデルの構築についてはうまくいきませんでしたが、データの可視化から読み取れるものもありました。
シェアサイクルの利用は天候に左右される傾向が強く、人々の生活圏にあることが重要なのではないだろうかと思いました。人々の恒常的な生活の一部にしていくことも重要であると考えられます。
季節別でみると春・冬が夏・秋と比較して利用が少なく推移しておりましたが、平日の午前7時~8時、午後5時~6時代については1年を通して利用されていることから人々の生活に欠かせない(通勤・通学)ものであるという条件は非常に大きな影響を持っているのではないでしょうか。
7.終わりに
今回はkaggleのコンペを参考に分析予測を実施してみました。初心者ということもあり、「わからないことだらけ」という状況ではありましたが、ひとつひとつじっくり考えればなんとか読み取れるぐらいにはなれたと思います。人のコードを読みながら、考え、web検索し、アレンジしていく(あまりできてないですが。。。)の繰り返しだったなと感じています。
今後は日本のシェアサイクル利用の分析・予測を行っていきたいなと思います。シェアサイクル企業がデータを開示しオープンデータ化する傾向も強くなってきているようなので、多くのデータが集めることでより精度の高い分析予測ができるようにスキルを身に着けていこうと思います。