
AWS DOPの学習(耐障害性編)

はじめに
本記事は個人の備忘録として、DOPに向けた学習の中で理解が不十分だった部分や間違えた問題の内容をまとめたものになります。
サービスの全体像を解説した記事ではないため、ご了承ください。
本記事は以下のサイトを大いに参考にしています。
とてもわかりやすくまとめられているため、DOPを受験される方はご一読することをお勧めします。
Lambda
リリースのベストプラクティス
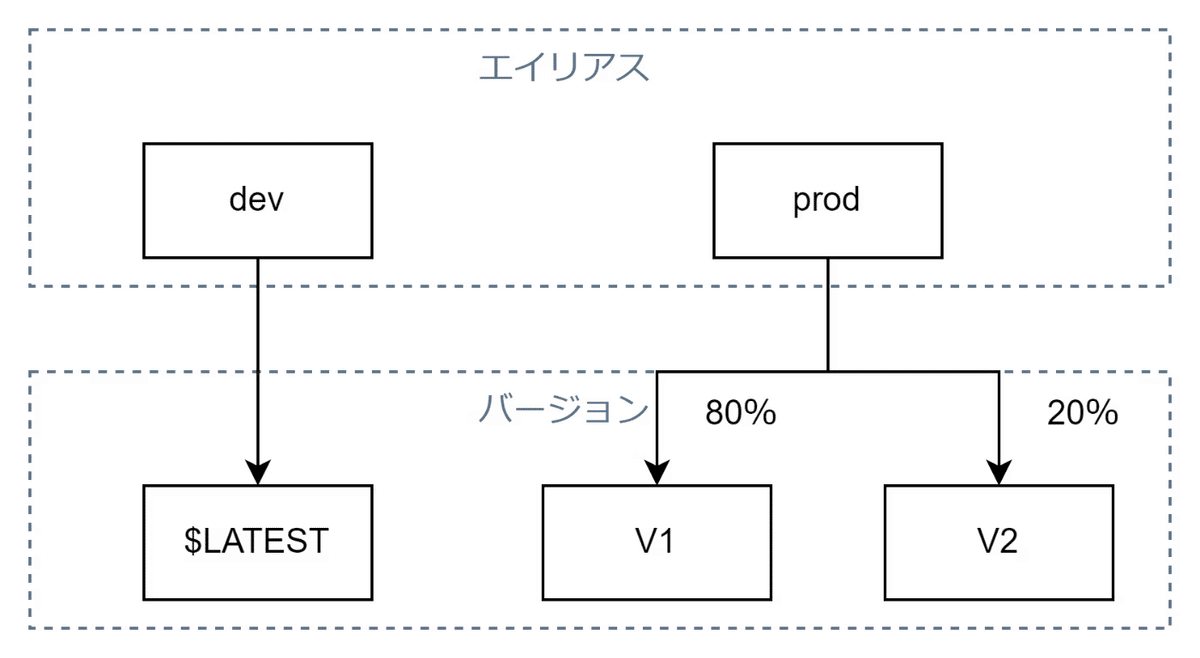
1.エイリアス切り替えによるバージョンアップ
エイリアスはLambda関数のバージョンに対するポインタの役割を果たす。
エイリアスごとに異なるLambda関数のバージョンを指定できるため、開発環境と本番環境で異なるバージョンを選択することが可能
また、エイリアスを複数用意してトラフィックを分散させることによりカナリアリリースも可能
2.環境変数を用いたソースコード修正なしのリリース
Lambdaの環境変数はKey/Valueの形式で定義できる。
環境やリリースごとに変わる可能性のある変数を環境変数として定義しておくことで、ソースコードを変更することなくAWS Lambdaの挙動を変えることができる。
スケーラビリティ
lambdaのデフォルト同時実行数は1000
予約済み同時実行(Reserved Concurrency)
1つのLambda関数が起動できるインスタンスを事前に決めておく方法。
特定の関数でさばくトラフィックがバーストしても、ほかの関数への影響は最小化することができる。
例)LambdaAは400まで
LambdaBは400まで
LambdaCは200までのようなイメージ
プロビジョニング済み同時実行(Provisioned Concurrency)
Lambdaインスタンスを事前に指定台数起動することでコールドスタート問題を解消し、より短い時間でLambda処理を完了させるために利用する。
※未使用時でも料金がかかるようになるため注意
Lambdaレイヤー
LambdaレイヤーとはLambda関数で使用できるライブラリとその他の依存関係をパッケージ化し、Lambda関数間で共有可能にする機能。
これよりLambda関数のアーカイブサイズを小さくする事も可能。
レイヤーには、ライブラリ、カスタムランタイム 、データ、設定ファイルなどを含める事が出来る。
API Gateway
API Gatewayでは重み付けによる負荷分散機能は存在しない。
API Gatewayは暗号化したエンドポイントしかサポートしていない。
エンドポイントタイプ
Edge-Optimized:
クライアントに最も近いAWS Edge LocationでAPIをホストし、低レイテンシーでアクセス可能にする。
デフォルト設定ではEdge-Optimizedになる。
Regional:
特定のAWSリージョン内にAPIを展開し、そのリージョン内のすべてのエンドユーザーに向けて高パフォーマンスな接続を提供する。
Private:
VPC内でAPIをホストし、パブリックインターネットを経由せずにプライベートネットワーク内でアクセス可能にする。
ステージ
APIのエンドポイントURL単位に作成するデプロイメント単位
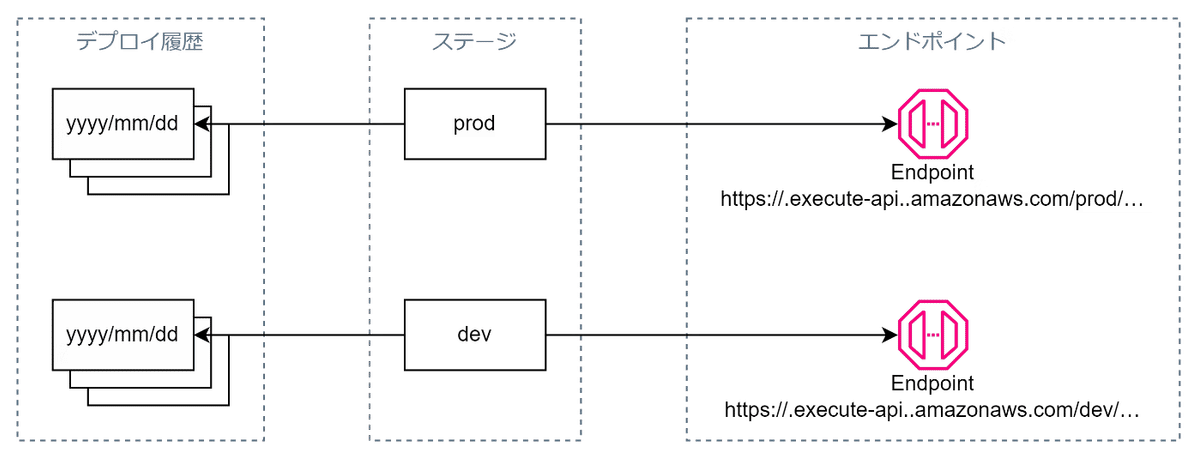
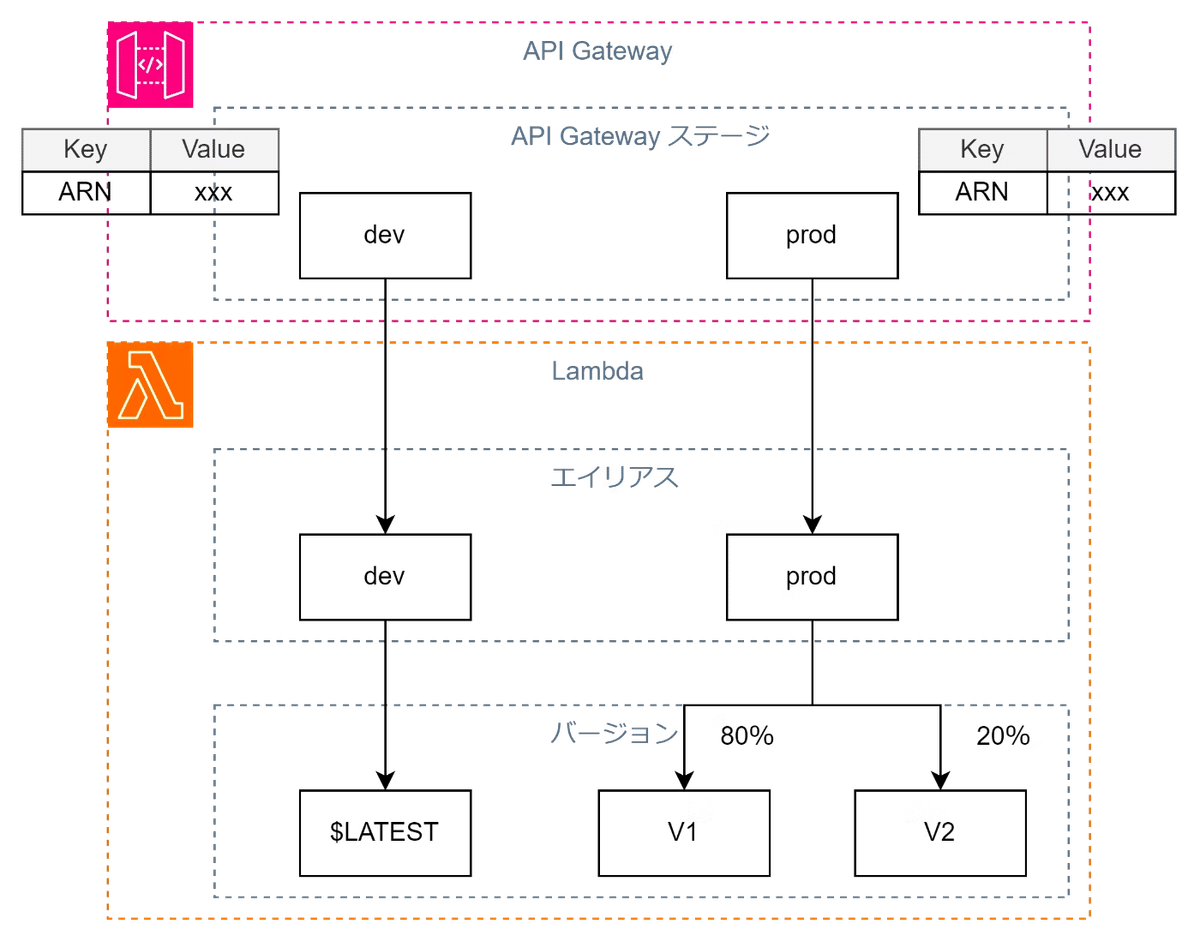
ステージ変数というAPI Gatewayのステージごとに設定できる環境変数に、LambdaのエイリアスARNなどの更新頻度の高いパラメータを定義して使用する。
Lambdaと同様、環境変数であるステージ変数を使うことで変数を更新するたびにAPI Gateway自体の再構築が不要となるので更新に伴うダウンタイムが短くなります。
カナリアリリース
既存のステージに結び付くCanaryと呼ばれる特別なステージを作成して行われる。
Canaryステージを定義するとデプロイ操作がいったん、Canaryのみに行われ、その後、トラフィックをシフトしてメインにもデプロイを反映する昇格か変更を切り戻す削除かを選ぶことができる。
APIキー
APIキーを持つユーザのみアクセス可能なAPIを作成できる。
APIキーに使用量プランを設定することで、クォータ(アクセス可能回数)、レート(アクセス頻度)、バーストを設定できる。
また、APIキー毎のアクセス回数を取得することができる。
使用料プラン
APIキーに設定することで、APIキーごとに下記の制限を追加できる。
スロットリング(一定の時間内に、事業者が特定の操作に対して送信できるリクエストの数を制限するプロセス)
クォータ制限
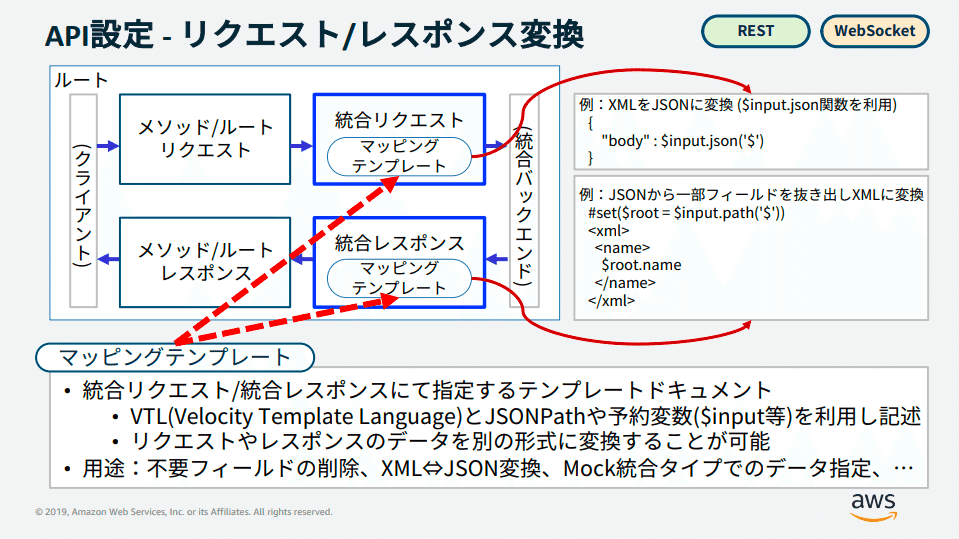
マッピングテンプレート
Amazon API GatewayとAWS Lambdaを連携させる際に使用される、リクエストやレスポンスのデータ変換を定義するためのテンプレート。
マッピングテンプレートは、リクエストのペイロードをLambda関数が期待する形式に変換したり、Lambda関数のレスポンスをクライアントが理解できる形式に変換するために使用される。
これにより、異なるデータフォーマット間の互換性を確保し、システム全体の柔軟性と拡張性を向上させることができる。
Lambdaプロキシ統合
API Gatewayを使用してHTTPリクエストをAWS Lambda関数に直接ルーティングする統合タイプの一つです。この統合では、API Gatewayが受け取ったリクエスト全体(ヘッダー、パスパラメータ、クエリパラメータ、ボディなど)をそのままLambda関数に渡し、Lambda関数がレスポンスを生成してAPI Gatewayに返すという動作を行います。
Lambdaプロキシ統合の特徴
シンプルなデータパス:
API Gatewayが受け取ったHTTPリクエストをそのままLambda関数に渡すため、リクエストのデータパスがシンプルになります。
柔軟なリクエスト処理:
Lambda関数がリクエスト全体を処理できるため、リクエストの解析やカスタムロジックの実装が容易です。
一貫性のあるレスポンス形式:
Lambda関数は、決められた形式でレスポンスを返します。これにより、API Gatewayがクライアントに対して一貫性のあるレスポンスを提供できます。
Lambda
Lambda オーソライザーでは、単一の Lambda 関数のコーディングと設定のみが必要。この関数は、HTTP ヘッダーおよびトークンの抽出と既存の認証サービスの呼び出しを行い、アクセスを許可または拒否するポリシーを送り返す。
ECS
「EC2」「Fargate」、AWS外のオンプレミス環境で実行されるコンテナ環境をECSで簡単に管理できる「Amazon ECS Anywhere」の3つの起動タイプをコンテナ実行環境としてサポートしています。
EC2タイプのECSを使用するには、ECSクラスタがEC2をノードとして認識できるようECS Agentのインストールが必要。
また、インスタンスプロファイルに適切な権限を付与する必要がある。
※インスタンスプロファイルはEC2からAWSサービスにアクセスする際には必須。
タスク定義でawslogsドライバを使用することで、ログが標準出力ではなくCloudWatchLogsに送信されるように設定できる。
クラスター
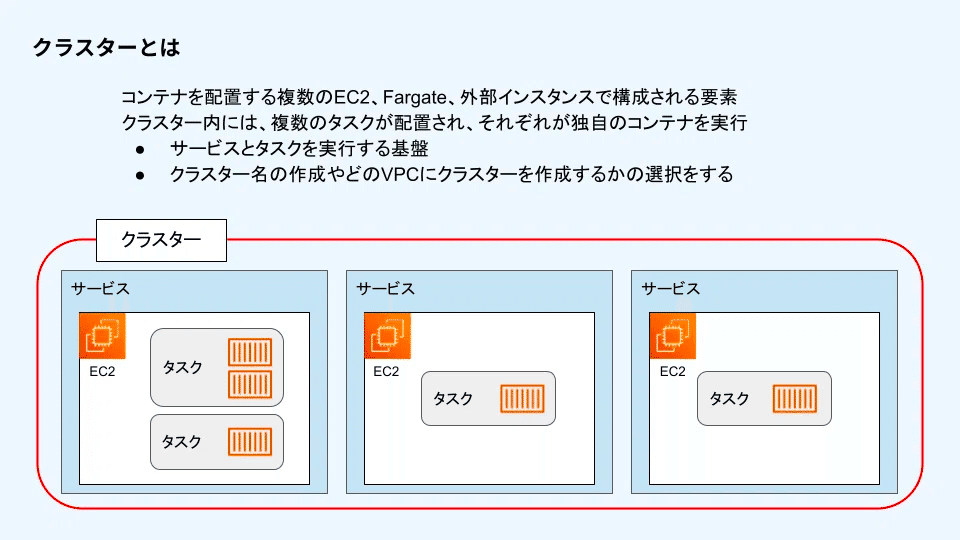
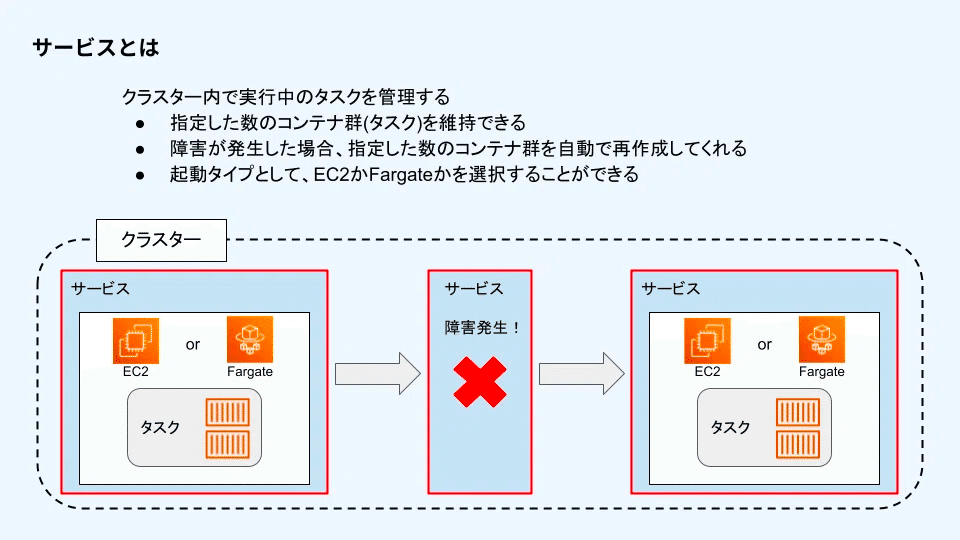
サービス
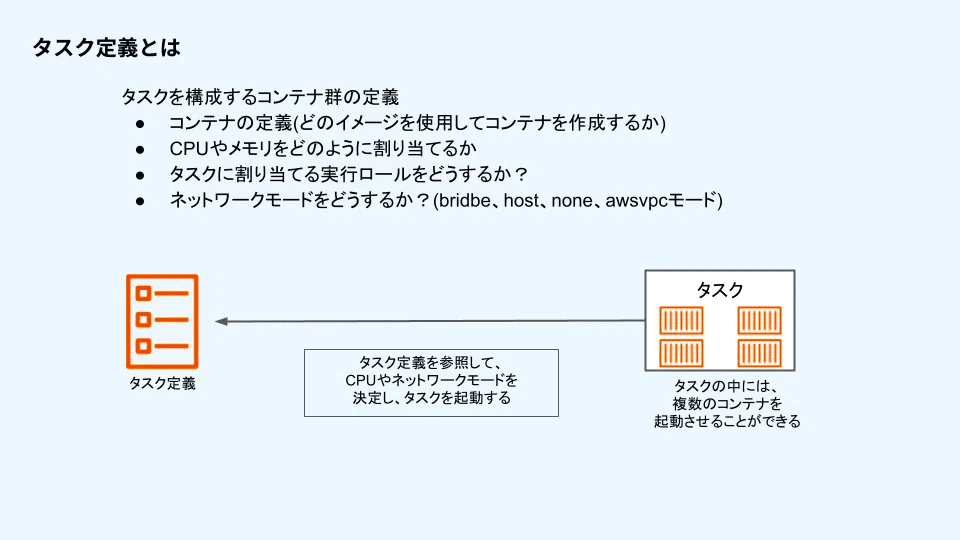
タスク定義
イメージの場所などを記載したコンテナ定義や要求CPU・メモリ、ネットワークモードなど、どのようなコンテナを作成するのかを定義したコンテナ群定義。
タスク定義は一度作成すると設定内容を変更することはできない。
変更したい場合は新しいタスク定義を別で作成するか、リビジョンと呼ばれるバージョン単位で内容を上書きする必要がある。
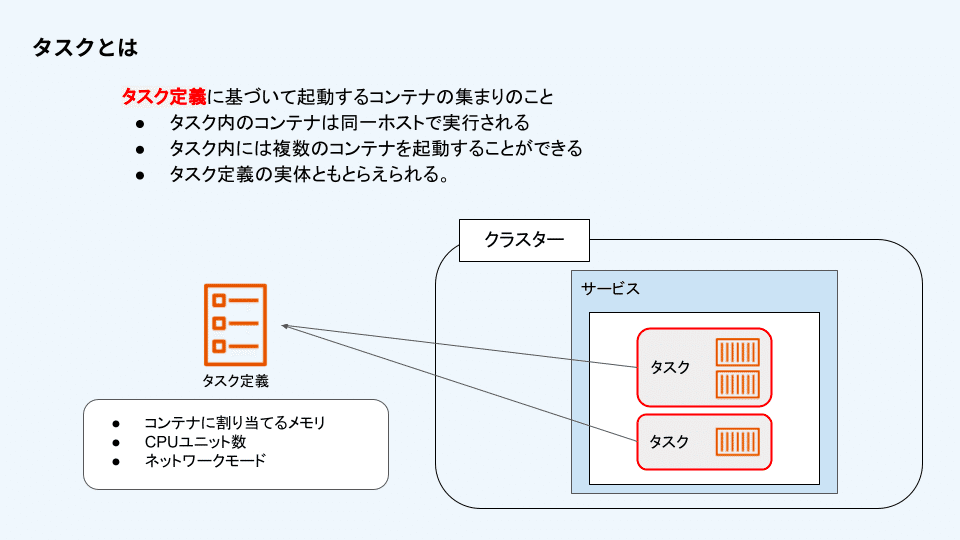
タスク
タスクロール
ECSタスクがAWSサービスと連携する際に使用されるIAMロール。
AWSサービスへのアクセス権を定義する。
タスク実行ロール
EC2インスタンスまたはFargateタスクがECSサービスと通信するためのIAMロール。
タスク実行ロールはタスク内のコンテナがAWSサービスへアクセスする権限を与え、セキュアな環境での運用を可能にする。
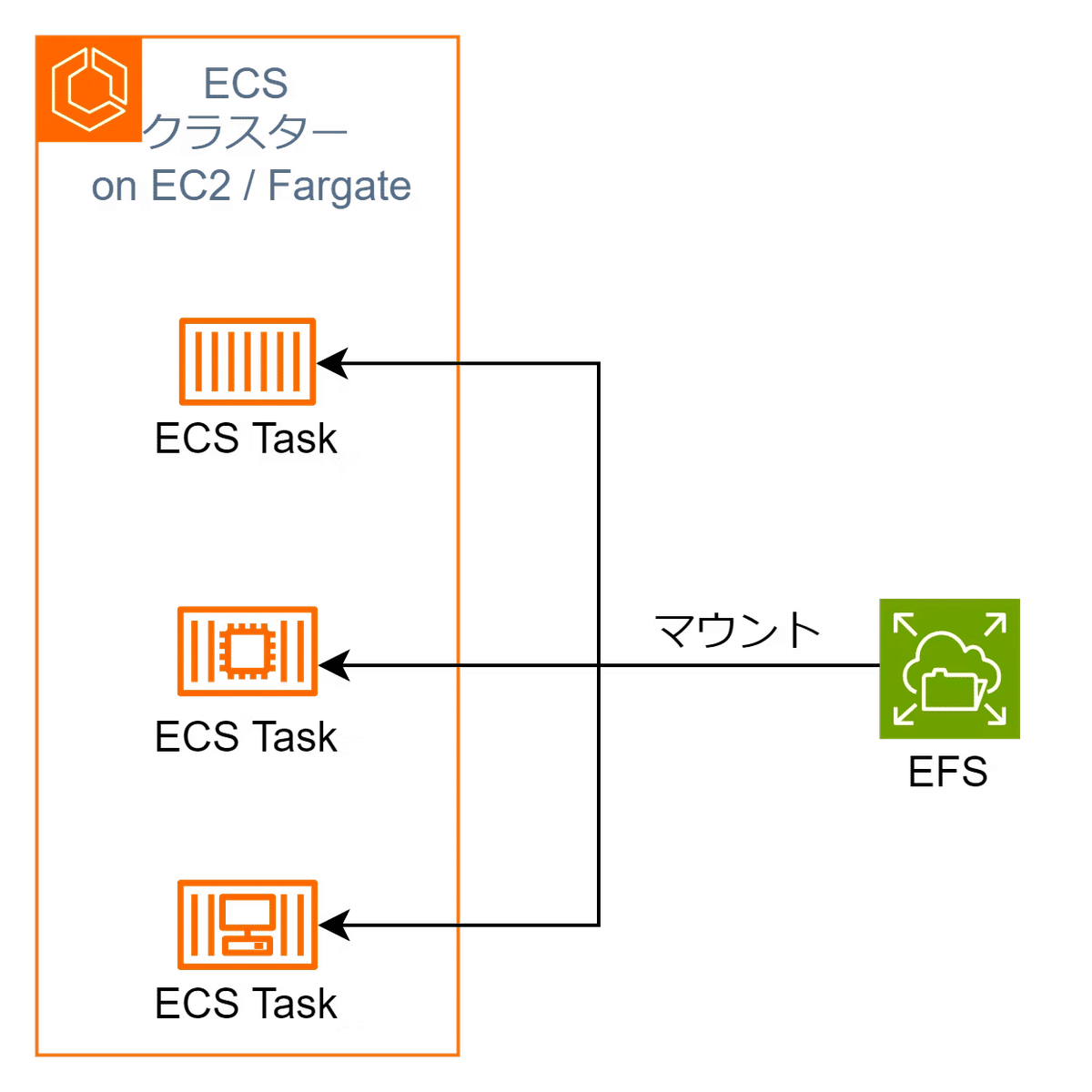
ストレージ
コンテナのストレージは揮発性のため、永続化ストレージが必要。
コンテナが水平方向にスケーリングするときの共有ストレージとして利用できることから、EFSがベストプラクティス。
ストレージとしてEBSを使用するとEC2タイプしか選択できなくなるが、レイテンシーが改善される。
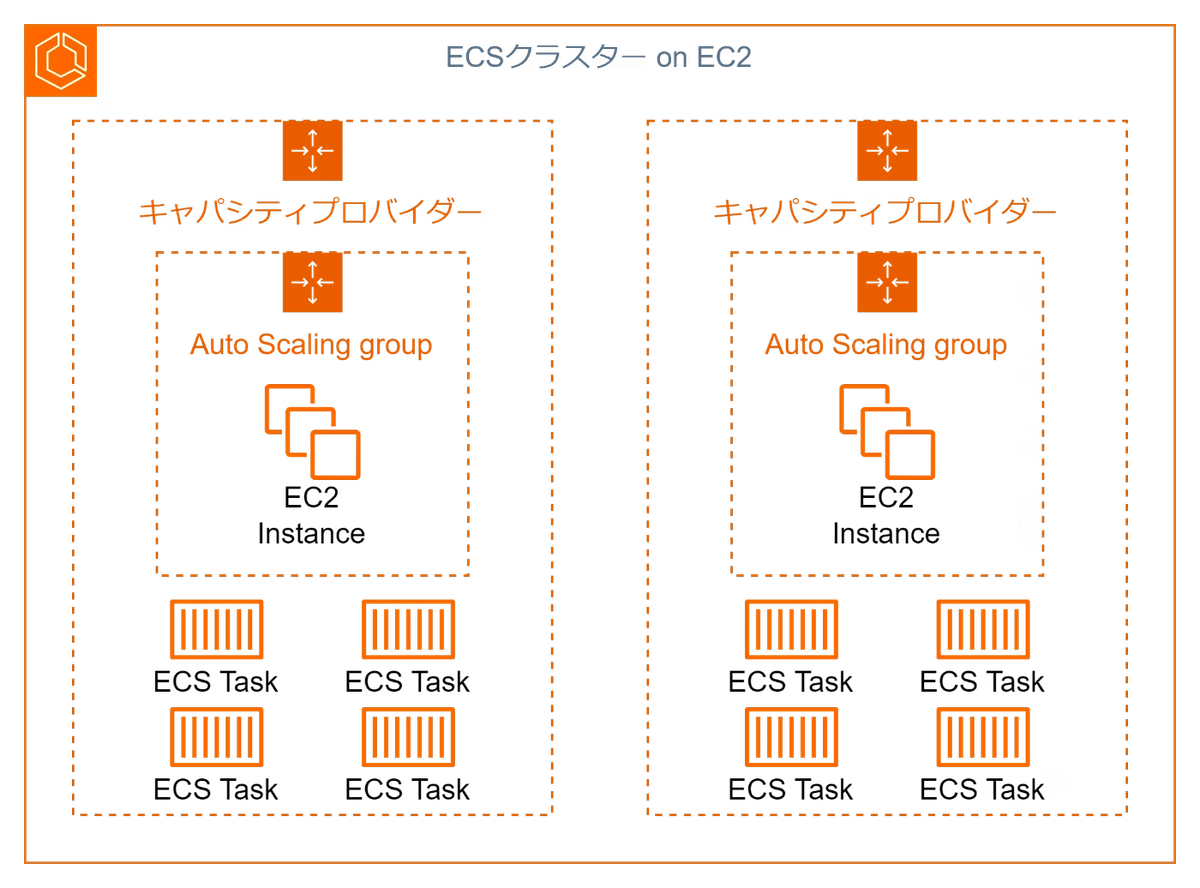
スケーリング
EC2インスタンスのスケーリングとタスクのスケーリングの2つを考える必要があるが、キャパシティプロバイダを使うことで、タスクのスケーリングに合わせてEC2のスケーリングもやってくれるため、EC2インスタンスのスケーリングを考える必要がなくなる。
Fargateの場合はキャパシティプロバイダーがなくてもスケーリング可能だが、キャパシティプロバイダを使用するのがベストプラクティス。
SHA Tracking
Amazon Elastic Container Services (ECS) では、ECR から取得したコンテナイメージを、スケジュール済みのタスクおよびその稼働場所 (Amazon EC2 または Fargate) に相関付けることができます。アプリケーションの採用、インシデント対応、ライフサイクル管理を追跡するためにコンテナイメージのデプロイ先を識別するための可視性および変更不可な属性が追加されました。
Amazon ECS の SHA 追跡では、CloudWatch イベントに送信されるタスク状態変更イベントを使用して、コンテナイメージのデプロイ先の追跡を明確に識別できるようにします。SHA 追跡は、アプリケーションのライフサイクル操作をサポートするために、Amazon ECR、ECS、Fargate、CloudWatch イベントに統合されています。過去のデプロイを分析して、いつ、どこで、どの位の期間アプリケーションが実行されたかを識別することにより、CloudWatch イベントを使用した採用の追跡を改善できます。アプリケーションが更新されたときに完全なパッチ監査サポートを提供するためにクラスター、コンテナ、アプリケーションイメージを相関付けることができるため、ユーザーに一貫したエクスペリエンスを提供できます。
Kinesis
大量のリアルタイムデータストリームを収集、処理、分析するためのAWSのプラットフォーム。特にデータをリアルタイムで捉えて迅速に分析する必要があるアプリケーション向けに設計されている。
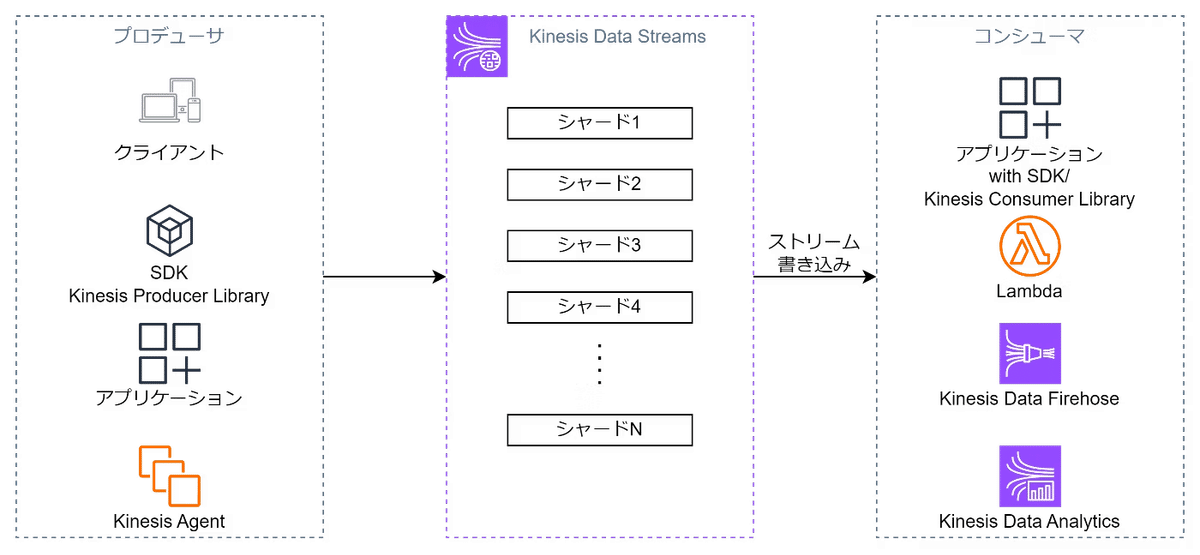
Amazon Kinesis Data Streams
リアルタイムで大量のデータを収集し、そのデータストリームを数秒以内に処理することができるサービス。
データを"ストリーム(一連のデータレコードのシーケンス)"として扱う。
ユーザーはデータをストリームにプッシュし、続いてそのデータをリアルタイムで消費し、処理することができます。
データはシャードというパーティション単位に分割される。
各シャードで並行処理が可能。
シャード数の増減によりスケールが行われる。
シャード数はキャパシティモードと呼ばれる設定に基づいて管理される。
キーワードは「リアルタイム」
オンデマンドモード
データストリームの作成時に事前のシャード数の指定が不要で、シャードの数が自動的に調整され、データのスループットに応じてスケーリングされる。
変動するデータ量に対して瞬時に対応し、迅速にスケーリングできるため、予測困難なトラフィックパターンに適している。
ただし、シャード数の自動スケーリングに伴い、コストも変動するため、予算の制約がある場合は検討が必要。
プロビジョニングモード
データストリームの作成時に必要なシャード数を明示的に指定するモード。安定的で予測可能なトラフィックが予想される場合や、特定の処理に対して一貫したスループットが必要な場合に適している。
ユースケース
リアルタイムデータ監視: サーバーログやアプリケーションログをリアルタイムで監視し、異常やエラーを即座に検出する。
リアルタイムメトリクスの生成: ウェブサイトやアプリケーションのトラフィックデータをリアルタイムで分析し、使用状況のダッシュボードを生成する。
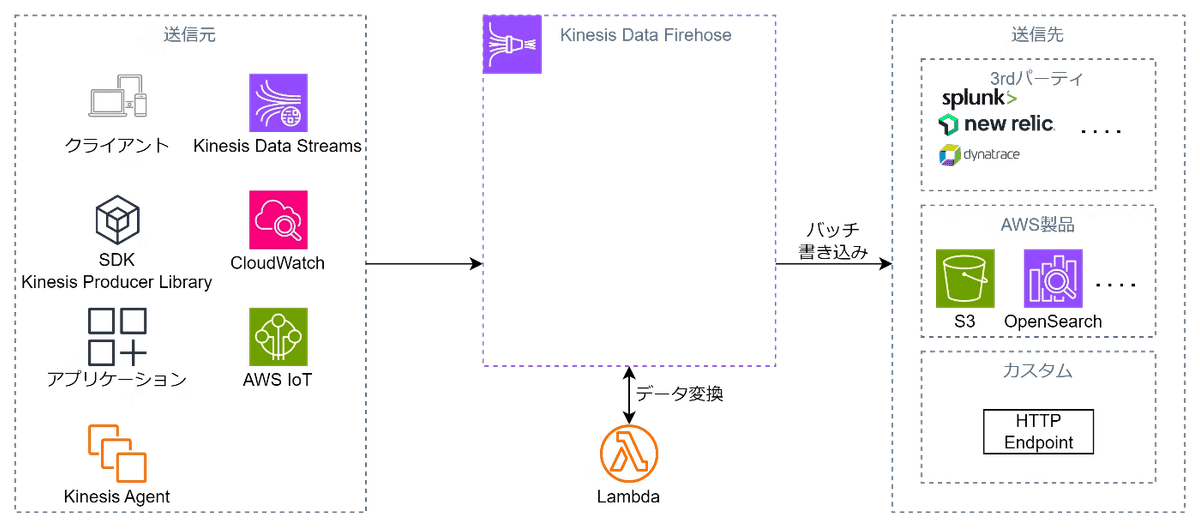
Amazon Kinesis Data Firehose
リアルタイムデータストリームを収集して、AWSのストレージサービス(Amazon S3、Amazon Redshift、Amazon OpenSearchなど)に直接ロードするためのサービス。
Firehoseはデータを自動的にバッチ処理し、変換し、圧縮してから指定された配信先に送信する。
Data Streamとの違いはデータがバッチ処理される点とデータ変換が行える点。
スケーリングは自動で行われる。
Kinesis Data Firehouseはlambdaによりデータを変換後に配信することも可能
各サーバからKinesis Data Firehouse(Streamも)にデータを配信するにはKinesisエージェントが必要
ユースケース
ログデータの保存と分析: システムログやアプリケーションログをAmazon S3に保存し、後から分析するために利用。
リアルタイムストリーミングデータのETL: ストリーミングデータをリアルタイムで加工して、データウェアハウスに直接ロードする。
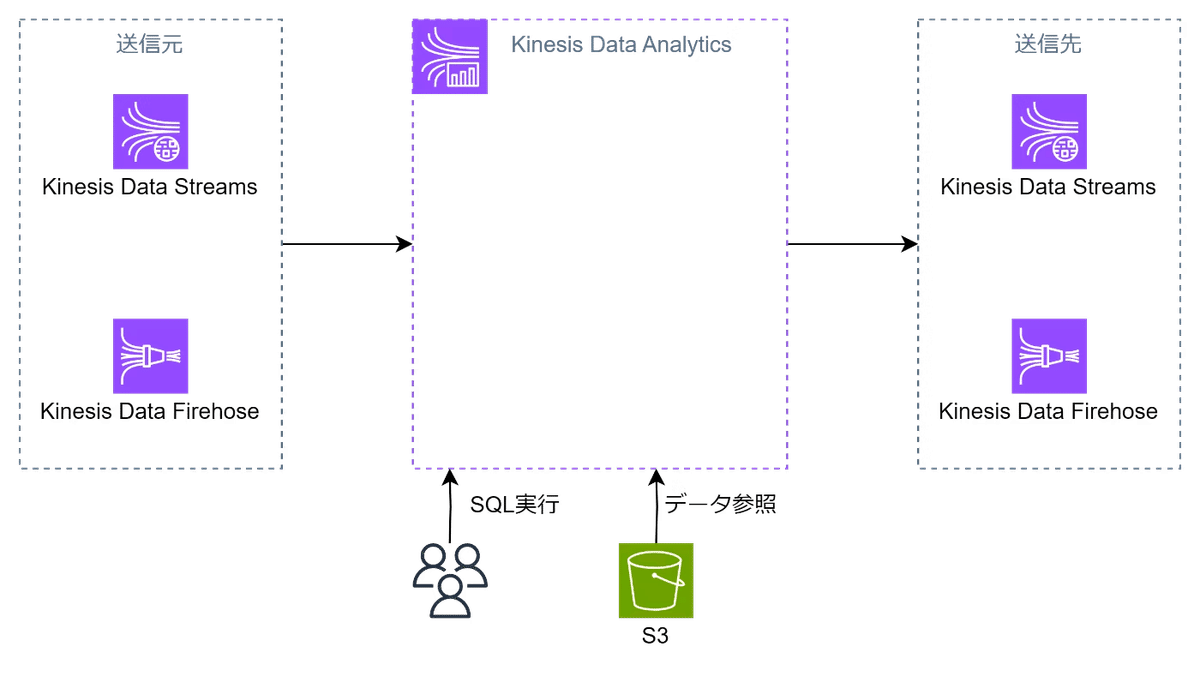
Amazon Kinesis Data Analytics
リアルタイムデータストリーム上でSQLを用いてデータを分析し、インサイトを即座に抽出するサービス。
このサービスを使うことで、ユーザーはストリーミングデータに対して継続的なクエリを書くことができ、分析結果を他のAWSサービスに直接フィードすることが可能。
データ分析サービスとしての側面が強い。
分析を行うのはKinesis内のデータ(DataFirehouseまたはDataStreamのソース)であり、S3内のデータを分析することはできない。
出力先もKinesisサービス。
ユースケース
リアルタイムアナリティクス: ソーシャルメディアフィードやマーケティングデータからリアルタイムでトレンドを抽出し、マーケティング戦略を即座に調整する。
異常検出: 金融取引データをリアルタイムで分析し、不正行為や異常なパターンを検出する。
Route53
高可用、スケーラブル、そして完全マネージド型の権威DNSサーバ。
Route53は権威DNSサーバであると同時にドメインレジスターでもある。
主にRecord、Hosted Zone、Routing Policyの3つから構成される。
権威DNSサーバ:
・ ドメイン名とIPアドレスの対応表を「ゾーン」という単位で管理。
・ 名前解決の問い合わせをされた際、自身が管理する情報のみ応答。
キャッシュDNSサーバ:
・ クライアントからドメイン名の名前解決の問い合わせを受ける。
・ 該当するドメイン名を管理する権威DNSサーバに問い合わせる。
・ 名前解決された問い合わせ結果は、一定期間キャッシュする。
・ 名前解決の問い合わせが同じ内容であればキャッシュ情報を使用。
Record
ドメイン名をIPアドレスに対応付ける。
RecordにはDomain/subdomain Name、Record Type、Value、Routing Policy、TTLという5つの設定項目がある。
Domain/subdomain Name:ドメイン名
Value:IPアドレス
TTL:DNSリゾルバでのキャッシュ期間
Record Type:A、AAAA、CNAMEから選択可能
Routing Policy:後述
Hosted Zone
ドメインを管理する単位。
特定のドメインに関連するDNSレコードの集合体で、各Hosted Zoneには一意の名前が付与されます。
Hosted Zone内でレコードセットを設定することで、ドメインの挙動や解決ルールを定義できる。
例えば、www.example.com をどのIPアドレスに解決するかなどがホステッドゾーンで設定される。
Hosted ZoneにはPublicとPrivateが存在し、インターネットからつなぐ場合にはPublic、VPC内部での通信に閉じる場合にはPrivateを利用する。
なお、PublicとPrivateで同じドメインを登録するとインターネットからのアクセスにはPublic Hosted Zoneが応答し、VPCからのアクセスにはPrivate Hosted Zoneが応答する。
※ドメイン:インターネット上で特定のリソースを識別するための名前(url等)
※DNS:ドメイン名をIPアドレスに変換するシステム
Routing Policy
1. シンプルルーティングポリシー
単一のリソースにトラフィックを転送する。
主に単一のエンドポイントを持つシンプルな用途に適する。2. フェイルオーバールーティングポリシー
プライマリとセカンダリの2つのリソースを設定し、プライマリが利用できない場合にセカンダリにトラフィックを自動的にフェイルオーバーさせます。4. 地理的近接性ルーティングポリシー
バイアスを設定することで特定のリソースにルーティングするトラフィックの量を変更できます。バイアスは、リソースにルーティングされるトラフィックのルーティング元である地理的リージョンのサイズを拡大または縮小します。5. レイテンシールーティングポリシー
クライアントの地理的位置に応じてトラフィックを最も低いレイテンシを持つエンドポイントに導くことができる。グローバルに展開されたアプリケーションで効果的です。7. 加重ルーティングポリシー
複数のリソースに対して異なる重みを設定し、トラフィックを分散させることができる。例えば、新しいバージョンのアプリケーションに一部のトラフィックを導入する場合に有用。
位置情報ルールは『特定の地域に特定のリソースをルーティング』するために使う
地理的近接ルールは『近くのリソースにルーティング』させるために使う
トラフィックフロー
複雑なルーティングのサポートをしてくれるサービス。
複数のRouting Policyを組み合わせて使用する場合に発生するレコード設定の複雑な階層構造管理を可能ににしてくれる。
このサービスを利用するとWeighted Routing Policyでトラフィック分割しながらリリースできる仕組みを作りつつ、バックエンドがダウンした時に備えたFailover Routing PolicyでSorry画面に自動で向くようにする、といったことが可能になる。
ビジュアルエディタ
トラフィックフロービジュアルエディタを使用すると、簡単なGUI操作でレコードの複雑な階層構造をトラフィックポリシーとして定義し、レコード間の関係を視覚的に管理することができます。また、トラフィックポリシーの作成数に上限はありません。
バージョニング
作成したトラフィックポリシーはバージョン管理をすることができます。そのため、ポリシーに変更が発生した際も最初から作成し直す必要もありません。また、デフォルトでは1つのトラフィックポリシーに対し、1000バージョンまで管理することができます。
地理的近接性ルーティングポリシー
Route53の地理的近接性ポリシーはトラフィックフローを使用する場合のみに使用できます。
※AWS公式によると、トラフィックフローの料金は「50.00USDポリシー記録ごと/月」でした。割と高めの料金かなと思いますので、設定した場合、不要であれば削除を忘れないようにしましょう。
RDS
RDSはAurora以外のDBでもマルチAZに対応している。
マルチリージョンにするにはリードレプリカを使用する。
マルチマスタークラスター(複数の書き込み可能インスタンスを用意)が可能なのはAuroraのみでRDSでは不可。
書き込みスループットを向上させるにはAuroraを使用する。
マルチAZ DBインスタンス
Multi-AZインスタンスでは、高可用性のために 2 つのAZにそれぞれインスタンスを配置して、片方を Active もう片方を Standby としてデータをレプリケートする。
待機系である Standbyにはアクセスされることはない。
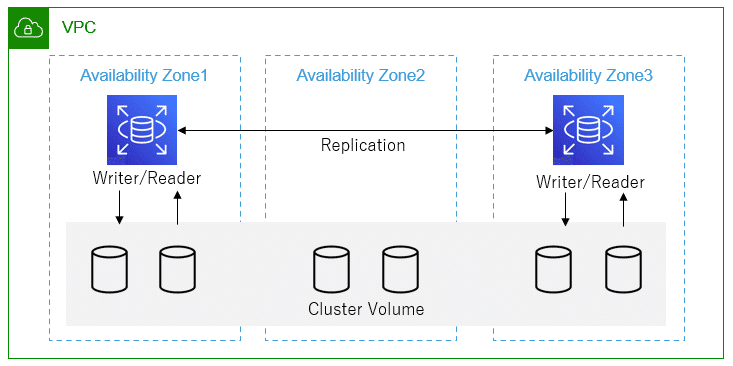
マルチAZ DBクラスター
3つの異なるアベイラビリティーゾーンにある1つのプライマリレプリカと2つの読み取り可能なスタンバイリードレプリカで構成される。
プライマリ(ライター)DBインスタンスは、読み取りおよび書き込み操作ができ、すべてのデータ変更ができる。
スタンバイ(リーダー)DBインスタンスは、プライマリのフェールオーバーターゲットとして機能し、読み取りトラフィックも提供される。
Aurora
Auroraのマルチクラスター構成は同一リージョン内でのみ可能。
別リージョンとの同期にはグローバルデータベースを作成する。
リードレプリカはリージョンを跨いで設定可能。
リードレプリカ
プライマリのインスタンスに障害が発生すると、Auroraレプリカがプライマリに昇格しフェイルオーバーする。
フェイルオーバーの時間に関しては、多くの場合は60秒未満とされている。
Auroraレプリカが複数個ある場合は、以下の優先度に従ってレプリカを昇格される。
①指定した優先度が高い(0に近い)リードレプリカ
②優先度が同じ場合はサイズの大きいリードレプリカ
③優先度とサイズが同じ場合は任意のリードレプリカ
DRでリードレプリカの昇格を自動化し、障害発生時にプライマリDBになるようにするには、
AWS Systems Manager Parameter Storeを使用して Auroraエンドポイントを保存し、EventBridgeでDBの障害を検知し、Lambdaによりリードレプリカを昇格してパラメータストアのエンドポイントを更新する。
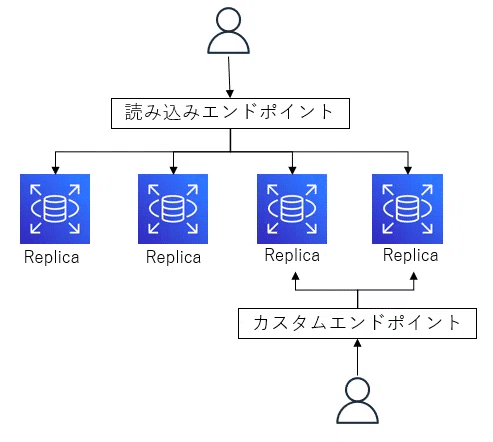
アクセス方法に関しては、以下の2種類が設定可能
①読み込みエンドポイント:読み込みエンドポイントを指定すると、各読み取り専用レプリカに分散したアクセスが可能
②クラスターエンドポイント:書き込み権限があるインスタンスにのみアクセスされる。
③カスタムエンドポイント:特定のインスタンスにアクセス可能。クライアントの要求をインスタンスの特定のサブセットに均等に分配することができ、読み取り専用のインスタンスだけにトラフィックを送る読み取り専用エンドポイントや、特定の種類のクエリを処理するためのインスタンスグループを指定することが可能。パフォーマンスの向上が見込める。
カスタムエンドポイント
カスタムエンドポイントにはREADERとANYという2種類のタイプがある。READERの場合はロールがReaderのインスタンスのみカスタムエンドポイントに設定できる。READERの場合は、通常の読み込みエンドポイントと同様にWriter以外に対して名前解決される。
ANYの場合はロールがWriter/Reader両方をカスタムエンドポイントに設定できる。タイプがANYの場合WriterとReaderを区別せず同確率で負荷分散し、書き込み可能かを事前に判断できないため、読み込み専用としての使用が必要。
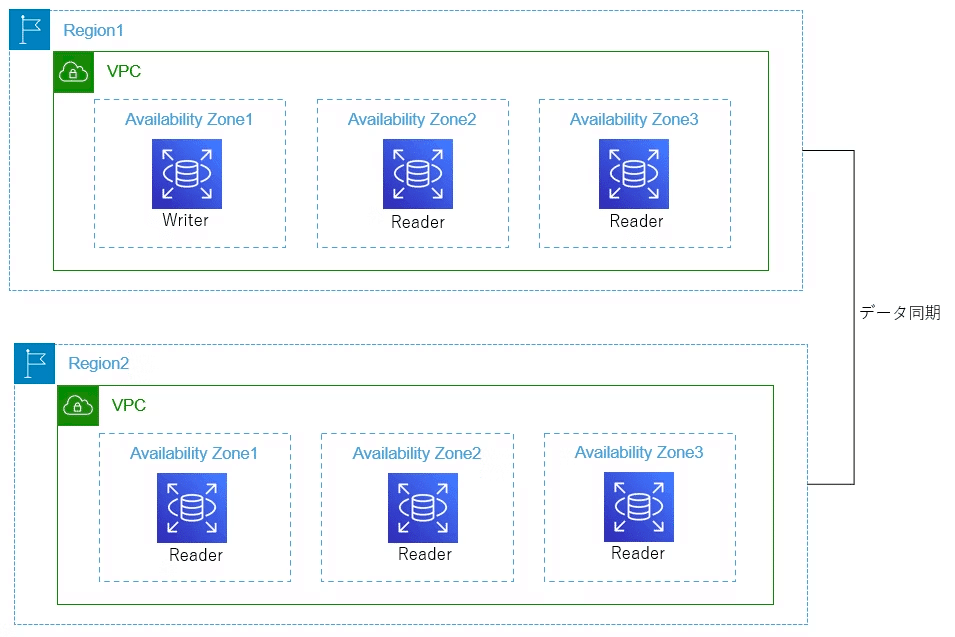
グローバルデータベース
リージョンまたぎでDBを同期する機能。
DR時のRTOの確保に有用。
セカンダリリージョンのクラスターは読み取り専用になる。
マルチマスタークラスター
Auroraマルチマスタークラスターを使用すると、クラスター内のすべてのインスタンスが読み書き可能となる。
利用にあたっては、以下の制約がある。
リージョンをまたいでマルチマスタークラスター講師を作成することはできない。
・MySQLが対象
・インスタンス数は最大2つ
・インスタンスの停止不可
・通常のクラスターより書き込みパフォーマンスが落ちることがある
・バックトラック機能の利用不可
バックトラック
Amazon Auroraは、バックトラックと呼ばれる機能を提供しています。これにより、誤ってデータを変更したり削除したりした場合に、特定のポイントまでデータベースを巻き戻すことができます。バックトラックは不測の事態に対する迅速な対応を可能にします。
Elasticache
RedisのレプリケーショングループはマルチAZには対応しているが、マルチリージョンには非対応。
マルチリージョンに対応するにはDynamoDBのグローバルテーブルを使用する。
主なユースケースはDBキャッシュとセッションストア
一時的なキャッシュ+低レイテンシーを求めるならElastiCache
データ永続+グローバルをもとめるならDyanamoDBのグローバルテーブルが適する。
スケーリングを行いたい場合はRedisを使用する。
Redisをクラスターモードで使用することで、シャードとリードレプリカが自動でスケールされる。
※Amazon ElastiCacheを利用するためにはアプリケーションのコードに大幅な変更を加える必要があるため、Amazon ElastiCacheの利用有無はアーキテクチャ検討の初期で見切ることが大切
スナップショット
Amazon ElastiCacheは定期的にスナップショットを作成し、データをAmazon S3に保存します。これにより、データの永続性を確保し、障害やデータ損失の際にはスナップショットからデータを復元できます。スナップショットは手動で作成することも可能で、必要なときにデータの状態を確実に保存できます。
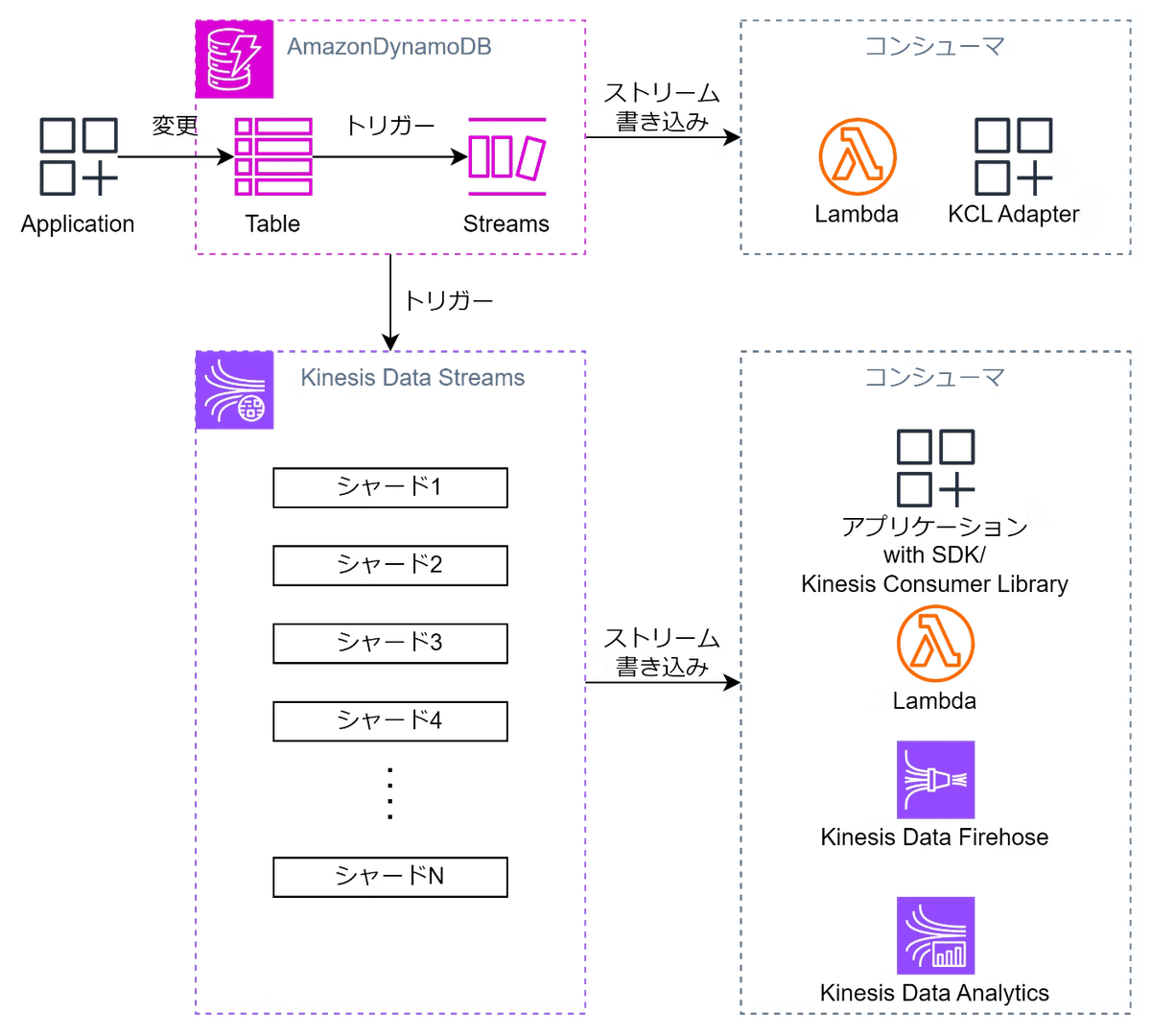
DynamoDB
DynamoDBはTalbeと呼ばれる単位で構成され、各テーブルが必ず1つのPrimary Keyを保持している。
DynamoDB Streams
データベース内の変更をリアルタイムで捕捉する機能を提供する。
これにより、データの変更に対してトリガーを設定して、リアルタイムアプリケーションやイベント駆動型サービスを構築できる。
以前はDynamoDBのストリーミングはDynamoDB Streamsのみでしたが、最近になってKinesis Data Streamsとも連携できるようになった。
オンデマンドモード
トラフィックに応じて自動的にスケーリングされるモード。
急激なトラフィック変動に対応し、柔軟な利用が可能。
プロビジョニングモード
事前に設定したスループット容量に基づいて課金される。
トラフィックの変動が予測可能な場合に適する。
DynamoDB Accelerator
DynamoDB Accelerator(DAX)は、インメモリキャッシュを提供し、ミリ秒単位のレイテンシでデータへのアクセスを可能にします。
GlobalTable
DynamoDB のリージョンレベルでのレプリカテーブルを作成する機能。
アプリケーションがあるリージョンのレプリカテーブルにデータを書き込むと、DynamoDB は書き込みを他の AWSリージョンのレプリカテーブルに自動的に伝播する。
各リージョンで低レイテンシの書き込みと読み取りを提供する。
Point-in-Time Recovery
誤って削除されたテーブルやアイテムを特定の時点まで復元できる機能を提供する。
AWS Database Migration Service
データベースの移行を簡単に行うためのフルマネージドサービス。
DMSを使用すると、オンプレミスやクラウド内のデータベースをAWSに移行したり、AWS内のデータベース間で移行することができる。
AWS Schema Conversion Tool(SCT)
異なるデータベースエンジン間の移行時のデータ変換やフィルタリングをサポートする。
RedShiftやDynamoDBといった非RDSのサービスにも移行が可能。
また、データベースの変更をトリガーとして、ソースデータベースとターゲットデータベースを同期させて、リアルタイムでのデータ同期が可能
ELB
ELBのアクセスログにはLBに送信されたリクエストの詳細情報が含まれており、リクエストの受信時刻、クライアントのIP、リクエスト経路、レスポンス情報が含まれており、リクエストの処理時間を確認することもできる。
ALB
HTTPプロトコル用のLB。
パスベースルーティングはALBでも可能。
ALBやASGのヘルスチェックはデフォルトではHTTPプロトコルのポート80が使用される。
カスタムポートを使用している場合はALBとASGのヘルスチェック対象ポートを変更することが必要。
(アプリケーションが正常起動していないのにヘルスチェックをパスしてしまう。)
Web層がアプリケーション層やDB層と通信できることをALBで検証するには、Web層内にアプリケーション層とDB層のチェックを行うエンドポイントを作成し、Web層に関連するターゲットグループのヘルスチェックのエンドポイントに上記エンドポイントを設定する。
ALBのアクセスログを有効化することでS3に直接アクセスログを出力することが可能。
アクセスログにはリクエスト受信時刻、クライアントIP、遅延時間、リクエスト経路などの情報を含むためトラブルシューティングに活用できる。
ALB上のセキュアリスナーにSSL/TLS証明書をアタッチすることで転送中のトラフィックを暗号化することができる。
IPv6アドレスの対応
IPv6アドレスで動作させるには、以下の手順を実行します:
VPCとサブネットにIPv6 CIDRブロックを割り当てる。
セキュリティグループでIPv6トラフィックを許可する。
IPv6対応のALBを作成する(デュアルスタックIPアドレス)。
ターゲットグループを設定し、ターゲットを登録する。
必要に応じて、Route 53でAAAAレコードを設定する。
これらの手順を実行することで、ALBがIPv6アドレスでのトラフィックを受け入れ、処理できるようになります。
NLB
TCP,UDPプロトコル用のLB
AutoScalingグループ
AutoScalingグループはEC2の増減を行うためのものであり、RDSのスケールには使用できない。
起動テンプレートを使用してスケール時に作成されるインスタンスのレシピを指定することができる。
起動テンプレートを更新すると次回以降のスケール時に作成されるインスタンスは更新後のテンプレートのものだが、既存のインスタンスは置き替わらないため注意
Target Tracking Scaling
事前に設定したメトリクスの目標値を保ちながら自動的にスケーリング
Simple Scaling/Step Scaling
特定のメトリクスの閾値を超えた場合に、指定された数だけインスタンスを追加または削除
Scheduled Actions
予め定義された時間に定義された台数だけスケーリングする。
サービスローンチのタイミングやキャンペーンを打つタイミングで台数を増やすといったシナリオが考えられる。
Predictive Scaling
機械学習を使用して CloudWatch からの履歴データに基づいたキャパシティー要件を予測しスケーリングポリシーを定義
ターミネートポリシー
インスタンスの終了時にどのインスタンスを優先的にターミネートするかを制御する。
自動決定のDefaultと古い順、新しい順の設定がある。
ライフサイクルフック
スケーリングアクションの前後にカスタム処理を挿入するためのメカニズム。
スケール時に開始されるインスタンスがASGに登録されるまでの猶予や、終了されるインスタンスの削除までの猶予を設定する。
ライフサイクルフックでの猶予時間の間にEventBridgeを介してEC2に必要な作業を実行する。
ライフサイクルフックは、Auto Scaling グループにカスタムスクリプトの成功または失敗に関するフィードバックを提供する。Auto Scaling グループはその情報を使用して、新しい EC2 インスタンスへのトラフィックの送信を開始するか、EC2 インスタンスを終了する。
Launchイベント
新しいインスタンスが ASG に追加される際にトリガーされる。
新しいインスタンスはまだ運用に組み込まれておらず、処理が途中の状態。
起動スクリプトの実行に利用される。
Terminateイベント
インスタンスがスケーリングアクションや手動で終了される際にトリガーされる。
インスタンスはまだ完全に終了していない状態。
終了前の確認処理の実施としてログの取得やデータの退避に利用する。
イベント通知
ASGは、スケーリングイベントや状態変更(HealthCheckの変化)に対してSNSトピックやEventBridge、Lambda関数に通知を送ることができ
ヘルスチェック
AutoScalingのヘルスチェック対象はデフォルトではEC2のヘルスチェックのみ。ELBのヘルスチェックを実施するには追加の設定が必要。
Amazon EC2ステータスチェック
・インスタンスの状態がrunnning以外の場合、もしくはステータスimpairedの場合に異常とみなされます。デフォルトで有効になっていて無効化できない。
・単純にEC2インスタンス自体の状態確認をチェックすることができる。
Elastic Load Balancing(ELB)
・ELBのターゲットグループのヘルスチェックでunhealthyとなったインスタンスを異常とみなします。デフォルトは無効になっています。
・Auto ScalingグループとELBが関連付けられている場合にオプションで選択可能です。
・OSレベルの状態確認だけではなく、EC2インスタンスのサービスが停止しているといったアプリケーションレベルでのチェックができます。
カスタムヘルスチェック
・ユーザーが独自で用意した監視をヘルスチェックとして使用し、unhealthyとなったインスタンスを異常とみなす。デフォルトでは無効。
EC2 Auto Scalingインスタンスの終了または再起動時にデプロイメントが失敗する場合、以下の点を確認および設定することが重要
インスタンス終了保護が有効かどうか
CodeDeployエージェントが正しくインストールおよび設定されているか
CodeDeployの同時デプロイ数を超えていないか
IAMロールおよびポリシーが適切かどうか
ヘルスチェックの設定が正しいか
ライフサイクルフックが正しく設定されているか
起動テンプレートまたは起動設定が適切かどうか
ウォームプール(Warm Pool)
スケーリングアクションがトリガーされた際に、即座に使用可能な事前に起動したインスタンスのプール。
あらかじめ起動されているがアクティブでないインスタンスを維持し、需要の急増(スパイク)に迅速に対応できるようになる。
ウォームプールのインスタンスは停止状態にしておくこともできる。
※コストに注意
AWS Health API
AWS Personal Health Dashboardに通知されるAWS Health イベント(メンテナンス情報、障害情報、etc...)の様々な情報を取得できるAPI
VPC エンドポイント
VPC内のリソースがインターネットを介さずに、他のAWSサービスやVPC内の他のリソースにプライベート接続できるようにするための機能。
VPCエンドポイントにはインターフェイスエンドポイントとゲートウェイエンドポイントの2種類が存在する
インターフェイスエンドポイント
AWS PrivateLinkを使用してVPC内のリソースと他のAWSサービスをプライベートに接続するエンドポイント。
各エンドポイントは、Elastic Network Interface(ENI)を使用して実装され、ENIは各サブネットに配置されます。
ゲートウェイエンドポイント
S3とDynamoDBへのトラフィックをプライベートにルーティングするためのエンドポイント。
VPCルートテーブルにエントリを追加することで、これらのサービスに対するトラフィックを制御する。
Cloud Front
502 Bad Gatewayとは、ウェブサイトのサーバーの通信状態に問題があることを示すエラーメッセージで、SSL証明書の期限切れの可能性が高い。
NAT Gateway
NatGatewayはAZごとに作成する必要がある。
AZにまたがったサービスではないことに注意。
Amazon DLM
Amazon DLM は、EC2 インスタンスや EBS ボリュームをバックアップの生成 → 保存 → 削除のライフサイクルを自動化してくれるツール。