
チョコレートバーの評価を予測する回帰モデルを作成してみた【Python初心者】

KaggleのDatasetsにあった『Chocolate Bar Ratings』を用いてチョコレートバーの評価を予測する回帰モデルを作ってみました。
今回の回帰モデルは、Rating(チョコレートバーのエキスパートによる格付け)を当てるモデルです。
Rating以外の情報からRatingを予測する回帰モデルです。
このモデルはどのRatingに当てはまるかを予測します。
実行環境
Python3
Windows
Kaggle
Chrome
Google Colaboratory
データの内容
Company (Maker-if known) 【バーを製造している会社名】
Specific Bean Originor Bar Name 【特定の豆の原産地バーの名前】
REF 【レビューがデータベースに入力された日時】
ReviewDate 【レビューの発行日】
CocoaPercent 【ココアの割合】
CompanyLocation 【会社所在地の国】
Rating 【格付け バーのエキスパートによる評価】
BeanType 【豆の品種】
Broad BeanOrigin 【豆の原産地】
行ったこと
① データをKaggleで取得
② どのようなデータがあるか可視化
③ 可視化した項目をグラフや表にしてどのような傾向があるか分析
④ データの数が多いものは上位20個に限定してグラフ化
⑤ どのようなグラフや表を使うとよりデータが読み取りやすくなるか検討
⑥ モデルの構築
⑥-1 データの変換や欠損値の補充
⑥-2 データの分割
⑥-3 CatBoost ( Category Boosting)を使って回帰モデルを構築し予測精度
を評価
①データをKaggleで取得
# /kaggle/input/chocolate-bar-ratings/flavors_of_cacao.csvをpandasで読み込み、
pandas.DataF/kaggle/input/chocolate-bar-ratings/flavors_of_cacao.csvrame 型を取得します
train_df = pd.read_csv('/kaggle/input/chocolate-bar-ratings/flavors_of_cacao.csv')②どのようなデータがあるか可視化


データの可視化から見えてきたこと
・"Bean\nType" と"Broad Bean\nOrigin" に欠損値があることを確認
・"豆の品種"と”ソラマメ原産地"にそれぞれ 1つ欠損値がある。
・"Company \n(Maker-if known)" 416社のチョコバーを調査
・”Specific Bean Origin\nor Bar Name” 1039箇所の特定豆原産地またはバーの名前
・”Cocoa\nPercent” 45種類のカカオの配合%
・"Company\nLocation" 60カ国の製造元のある国を調査
・"Company\nLocation" 60カ国の製造元のある国を調査
・”Bean\nType” 使用されている豆のタイプは41種類
・”Broad Bean\nOrigin” 豆の原産地は100か所
③可視化した項目をグラフや表にしてどのような傾向があるか分析

グラフ化したことから見えてきたこと
データの量が多くグラフが見にくいため、見やすいデータに変更する必要があることが分かりました。
④データの数が多いものは上位20個に限定してグラフ化


⑤どのようなグラフや表を使うとよりデータが読み取りやすくなるか#検討

#データの可視化_分布編(バイオリンプロット)
#⑥豆の品種と格付けの関係をバイオリンプロットにしたい → 豆の品種と格付けでおいしいカカオを生産できているか読み取れる?
#Bean\nType 7
#Rating 6
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
df_2 = pd.DataFrame(data=train_df)
# Ratingを降順でソート
df_s = df_2.sort_values('Rating',ascending=False)
# Rating上位20の抽出
df_Company = df_s.iloc[0:20, :]
# 列(column)リストからインデックスを指定して列名を取得
X = df_Company.columns[7]
y = df_Company.columns[6]
# グラフサイズの指定
plt.figure(figsize=[30,10])
sns.violinplot(data = df_Company , y = y, x = X)
可視化してみた項目
※今回のブログでは割愛したがグラフや表で可視化した項目
① どの会社が多く選ばれているのか棒グラフにしたい。
→ どの会社のデータが多く使用されているか
1位:Soma、2位:Bonnat 、3位:Fresco
② 特定豆原産地またはバーの名前を棒グラフにしたい。
→ どの豆の原産地が多く使われているか
1位:Madagascar、2位:Peru 、3位:Ecuador
③ ココア割合をヒストグラムにしたい。
→ どのココア割合が多いか
ココアの割合70%が一番多い
④ 格付けと会社名の関係性をグラフにしたい。
会社名と格付けの点数との関係をグラフにしたい
(棒グラフ、バイオリンプロット)
→ おいしいチョコレートを作る技術があるか?
格付け上位が多い会社名
1位:Amedei、2位:Soma 、3位:Benoit Nihant
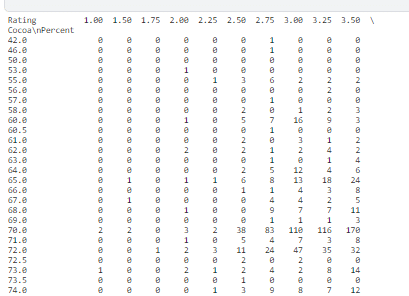
⑤ ココアの割合と格付けの関係を散布図、ピボットテーブルにしたい
→ おいしい(トレンド)のココア割合がわかる
1位:Amedei 社 70%のカカオが一番Ratingの評価がよい
⑥ 豆の品種と格付けの関係をバイオリンプロットにしたい
→ 豆の品種と格付けでおいしいカカオを読み取る
豆の品種 TrinitarioとBlendの評価が高い
⑦ 豆の品種と豆の原産地の関係を散布図、積み上げ棒グラフにしたい
→ 豆の品種と原産地の気候的特徴が読み取れる?
豆の原産地で1番多い Madagascar
豆の品種で1番多い Amazon, ICS
最適なグラフや表にしたことから見えてきたこと
・データを様々なグラフを用いて表現することで、データの関係性や特徴を
視覚的に表現でき、データのもつ特徴をより考察しやすくできることが分
かりました。
・データの可視化の仕方の違いが、より深く考察できる可能性を生んでいる
と感じました。
・データを最適化することで、新しい角度から見ることができるようになり
今まで見落としていた視点での考察が可能になると感じました。
⑥モデルの構築
⑥-1 データの変換や欠損値の補充
#欠損値の補完
train_df["Bean\nType"]=train_df["Bean\nType"].fillna(train_df["Bean\nType"].mode()[0])
train_df["Broad Bean\nOrigin"]=train_df["Broad Bean\nOrigin"].fillna(train_df["Broad Bean\nOrigin"].mode()[0])#モデルの構築
#モデルを構築する前にエラーの出やすいラベルの名前を変更する
train_df
label="Rating"
col=['Company','Specific_Bean_Origin_or_Bar_Name',
'REF', 'Review_Date','Cocoa_Percent', 'Company_Location',"Rating",
'Bean_Type', 'Broad_Bean_Origin']
#名前を変更。\nとかが邪魔だから。
train_df.columns=col
#列名が変更できていることが確認できる。
train_df.head(5)


⑥-2 データの分割
KFoldでデータを5分割にした
#モデルの構築
#Ratingのデータとそれ以外のデータに分けるために、別々のリストを作成します。
label="Rating"
col=['Company','Specific_Bean_Origin_or_Bar_Name',
'REF', 'Review_Date','Cocoa_Percent', 'Company_Location',
'Bean_Type', 'Broad_Bean_Origin']#モデルの構築
#データの分割 KFold
from sklearn.model_selection import KFold
#今回は5fold(5分割でやってみましょう)
cv = KFold(n_splits=5, random_state=100, shuffle=True)
x_train=train_df.loc[:,col]
y_train=train_df.loc[:,label]
#foldという列を準備してあげて、それぞれのデータが何番目のfoldに属するのかをデータフレームに入力します。
for i ,(trn_index, val_index) in enumerate(cv.split(x_train, y_train)):
train_df.loc[val_index,"fold"]=i
train_df[train_df["fold"]==0]
train_df[train_df["fold"]!=0]#モデルの構築
#データの分割 KFoldを毎回分けるのが大変なので、CSVファイルとして保存
#何回もfoldごとに分けるのがめんどくさい時はto_csvして保存すると後から楽です。
train_df.to_csv("kfold.csv",index=False)
kfold=pd.read_csv("kfold.csv")
#pathは上記のkfoldのcsvデータがある場所に設定してあげる必要があります。分割したデータをCSVファイルとして保存して毎回分割しなくてもいいようにした。
#モデルの構築
kfold
categorical_col=["Company","Specific_Bean_Origin_or_Bar_Name","Company_Location","Bean_Type","Broad_Bean_Origin"]
num_col=["REF","Review_Date","Cocoa_Percent"]#モデルの構築
#ちゃんと%を数値データに変換できています
kfold["Cocoa_Percent"]カカオの割合が%を含んだstr型(文字列)だったので、
float型(数値 浮動小数点型)に変更し、数値データとして扱えるようにした。
#モデルの構築
#『categorical_col』と『num_col』を定義する
categorical_col=["Company","Specific_Bean_Origin_or_Bar_Name","Company_Location","Bean_Type","Broad_Bean_Origin"]
num_col=["REF","Review_Date","Cocoa_Percent"]
col_name=categorical_col+num_col
#モデルに入力する際にはcategorical_colと数値データを一緒にする必要があるので。
#、col_name=categorical_col+num_colとしています。
train.loc[:,col_name]⑥-3 CatBoost ( Category Boosting)を使って回帰モデルを構築し予測精度を評価
CatBoostとは「Category Boosting」の略で2017年にYandex社から発表された機械学習ライブラリです。
カテゴリカル変数が多いデータに強く、カテゴリカル変数を高度に処理してくれるアルゴリズムが含まれています。
今回の回帰モデルは、Rating(格付け)を当てるモデルです。
Rating以外の情報からRatingを予測する回帰モデルです。
このモデルはどのRatingに当てはまるかを予測します。
#モデルの構築
#pool関数 並列処理
from catboost import Pool
import numpy as np
train_pool = Pool(train.loc[:,col_name].reset_index(drop=True),train.loc[:,label].reset_index(drop=True), cat_features=categorical_col)
validate_pool = Pool(val.loc[:,col_name].reset_index(drop=True), val.loc[:,label].reset_index(drop=True), cat_features=categorical_col)
#モデルの構築
# train_pool
from catboost import CatBoostRegressor
model = CatBoostRegressor(random_seed=42)
model.fit(train_pool,
eval_set=validate_pool, # 検証用データ
early_stopping_rounds=100, # 10回以上精度が改善しなければ中止
use_best_model=True, # 最も精度が高かったモデルを使用するかの設定
plot=True) # 誤差の推移を描画するか否かの設定CatBoostでの予測評価結果

Root Mean Squared Error【 RMSE 】(二乗平均平方根誤差)が小さければ小さいほど、誤差の小さいモデルであると言えます。
RMSE は機械学習モデルの予測値がどれだけずれているかを図る指標です。
モデルの予測と正解のデータから計算されたRMSEが最小になるようにモデルを学習させるというような使い方をします。
今回のモデルのRMSE値は、bestTest=0.3847787121となっているので許容できる数値となっていると判断しました。
【追記】
パラメータである『early_stopping_rounds』の値を100→850に変更し『early_stopping_rounds=850』にしたところ、RMSE値が
bestTest = 0.383293783となり最も良い数値が出ました。
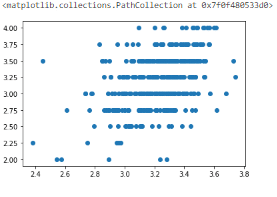
また、相関関係があるかを確認するためにグラフ化しました。
今回のデータは離散値であるため、線形回帰モデルに見えづらいですが
右肩上がりにプロットが固まっている傾向がみられるので
相関関係がある特徴が捉えられていると思います。
今後の課題として
LightGBMでもモデルを構築してCatBoostとの結果の違いを比較してみたいです。
さいごに
機械学習を学んで正直、難しくてつまらないと感じる時期もありました。
ですが実際に、自分で分析・可視化・モデル構築・予測をしていくことで
徐々に楽しさがわかってきました。
特に、様々な角度からデータ加工・可視化できたのがとても楽しかったです。
Excelでは描いたことのないグラフを描け、
まだまだ知らない分析方法があることを知ることができました。
これからも分析の知識を増やし、データ加工・可視化・機械学習・データ分析のスキルをもっと身に着け、仕事に生かしていきたいです。
半年間の勉強でやっと、スタートラインに立つことができました。
今後も日々精進して、機械学習を学んでいきたいと思います。
ありがとうございました。