Pythonで解析する携帯電話価格データ:K-meansクラスタリングによる価格パターンの抽出

はじめに
みなさん、こんにちは!Python初めたてサラリーマンのtake-shu-です!
Python初めてたてすぎて首が座っていない(自走できず、参考資料を読みながらの実装)状態ではありますがww……
機械学習の分野でよく使用されるクラスタリングアルゴリズムを活用したプログラミングにチャレンジしましたので、ご紹介します。
説明べたなところがありますが…読者の皆さんに何らかの刺激や気付きを与えられれば幸いです!それでは、さっそく本題に入りましょう!
本記事の概要
この記事では、Pythonの機械学習ライブラリであるScikit-learnを使用して、K-meansクラスタリングアルゴリズムを実装したプログラムを紹介します。K-meansクラスタリングとは…データを事前に指定したクラスタ数に分割する手法であり、データのグループ化や分析に役立ちます!
本記事は、以下のような読者を想定して書いています。
クラスタリングアルゴリズムの基本的な仕組みを知りたい人
K-meansクラスタリングの実装方法や使い方を学びたい人
それでは、具体的なプログラムコードを解説しながら、K-meansクラスタリングの実装手順や結果の解釈方法について説明します。
また、バブルチャートを用いた可視化や結果の表形式表示なども紹介します。ただし、機械学習やデータ分析の基礎知識が必要となる場合があるため、その点は留意してください。
作成したプログラム
今回、私はKaggleの携帯電話の価格データセットを使用して、K-meansクラスタリングアルゴリズムを実装しました。
参考:https://www.kaggle.com/datasets/rkiattisak/mobile-phone-price
以下に、作成したプログラムの概要を示します。
データの読み込みと前処理: CSVファイルからデータを読み込み、必要な前処理を行います。カラム名の修正や数値データの整形などが含まれます。
データの標準化: 分析に使用する特徴量を選択し、データを標準化します。標準化により、異なるスケールの特徴量を統一的に扱うことができます。
K-meansクラスタリングの実行: 標準化されたデータを用いてK-meansクラスタリングを実行します。クラスタ数は6とし、ランダムシードを設定して再現性を確保します。
クラスタリング結果の可視化: クラスタごとに特徴量の平均値をバブルチャートで可視化します。価格と各特徴量の関係を視覚的に理解することができます。
クラスタリング結果の表形式表示: クラスタごとの特徴量の平均値を表形式で表示します。さらに、BrandとModel情報も含めて表示して、各クラスタはどのようなBrandとModelで構成されているかを確認します。
以上が、今回作成したプログラムの概要です。このプログラムを実行することで、モバイル電話の価格データを6つのクラスタに分割し、各クラスタの特徴や価格の傾向を把握することができます。
実際のコードは以下の通りです!
import pandas as pd
import re
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
import numpy as np
# データの読み込み
data = pd.read_csv('/content/Mobile phone price.csv')
# カラム名の修正
data.rename(columns={'Storage ': 'Storage', 'RAM ': 'RAM'}, inplace=True)
# 数値データの前処理
numeric_columns = ['Storage', 'RAM', 'Screen Size (inches)', 'Battery Capacity (mAh)', 'Camera (MP)']
# 数値のみ取得する処理を追加
for column in numeric_columns:
# 正規表現を使って数値を抽出し、最大値を選択
data[column] = data[column].apply(lambda x: max([float(val) for val in re.findall(r'\d+\.\d+|\d+', str(x))]))
# +で区切り、最大値を取得する処理を追加
data['Camera (MP)'] = data['Camera (MP)'].apply(lambda x: max([float(val) for val in str(x).split('+')]))
# GBを取り除く処理を追加
for column in ['Storage', 'RAM']:
# 正規表現を使って数値を抽出し、GBを取り除く
data[column] = data[column].apply(lambda x: float(re.findall(r'\d+\.\d+|\d+', str(x))[0]))
# Price列のデータ型を数値型に変換
data['Price ($)'] = pd.to_numeric(data['Price ($)'], errors='coerce')
# 欠損値の補完
data.fillna(data.mean(), inplace=True)
# 特徴量の選択
X = data[['Storage', 'RAM', 'Screen Size (inches)', 'Camera (MP)', 'Battery Capacity (mAh)']]
# データの標準化
scaler = StandardScaler()
X_standardized = scaler.fit_transform(X)
# クラスタリング
kmeans = KMeans(n_clusters=6, random_state=42)
clusters = kmeans.fit_predict(X_standardized)
# クラスタリング結果の表示
data['Cluster'] = clusters
cluster_features = data[['Storage', 'RAM', 'Screen Size (inches)', 'Camera (MP)', 'Battery Capacity (mAh)', 'Cluster']]
print(cluster_features)
# クラスタごとの特徴量の平均値を可視化(バブルチャート)
cluster_columns = ['Storage', 'RAM', 'Screen Size (inches)', 'Camera (MP)', 'Battery Capacity (mAh)']
for column in cluster_columns:
plt.figure()
for i in range(6):
cluster_values = data[column][data['Cluster'] == i]
cluster_price = data['Price ($)'][data['Cluster'] == i]
bubble_sizes = [len(cluster_values) * 10]
bubble_centers = [(np.mean(cluster_price), np.mean(cluster_values))]
plt.scatter(*zip(*bubble_centers), s=bubble_sizes, alpha=0.5, label=f'Cluster {i}')
plt.title(f'{column} Distribution by Cluster')
plt.xlabel('Price ($)')
plt.ylabel(column)
plt.legend()
plt.show()
# クラスタごとの特徴量の平均値を表形式で表示
cluster_means = cluster_features.groupby('Cluster').mean().reset_index()
cluster_means['Price ($)'] = data.groupby('Cluster')['Price ($)'].mean().values
print(cluster_means)
# クラスタリング結果の表示
data['Cluster'] = clusters
# 表示オプションの変更
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
# クラスタごとの特徴量とBrand、Modelを表示
cluster_features = data[['Brand', 'Model', 'Storage', 'RAM', 'Screen Size (inches)', 'Camera (MP)', 'Battery Capacity (mAh)', 'Cluster']]
print(cluster_features)
cluster_features.to_csv('cluster_features.csv', index=False)
# 表示オプションを元に戻す
pd.reset_option('display.max_columns')
pd.reset_option('display.max_rows')
実行すると、以下の結果が得られました!(一部を抜粋)
ちなみにですが、クラスター数は事前にエルボー法を用いて6に決定しています。実際のクラスター分布を確認しても(個人的に)違和感がなかったので、クラスター数は6でOKだと思っています。
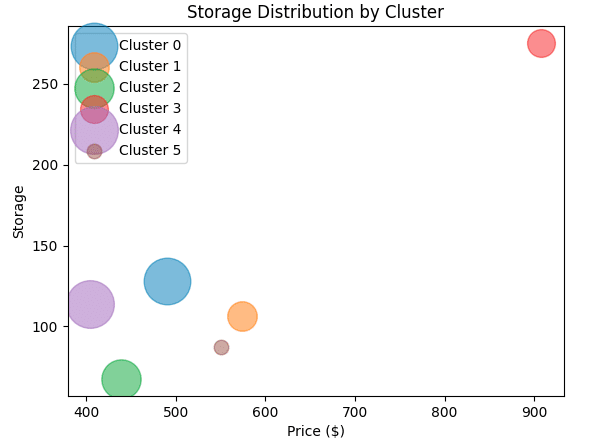





このクラスタリングの結果を見ると、携帯電話の性能や価格によって以下の異なるグループが得られたことが分かりますね。
クラスタ0: 内部ストレージが128GBでRAMも比較的大きく、カメラの性能も高いグループ。バッテリー容量も平均的で価格は中程度。
クラスタ1: 内部ストレージが106GB程度でRAMも平均的なグループ。カメラ性能は低めで価格は中程度。
クラスタ2: 内部ストレージが67GB程度でRAMも小さいグループ。カメラ性能も低く、バッテリー容量が高めで価格は中程度。
クラスタ3: 内部ストレージが275GB程度でRAMが大きく、カメラの性能も高いグループ。バッテリー容量も中程度で価格は高め。
クラスタ4: 内部ストレージが113GB程度でRAMも平均的なグループ。カメラ性能が高めでバッテリー容量も高め。価格は低め。
クラスタ5: 内部ストレージが87GB程度でRAMが小さいグループ。カメラ性能も低めでバッテリー容量が最も低い。価格は中程度。
これらの結果から、携帯電話の性能や価格によって明確なグループが形成されていることが分かります。特にクラスタ3のように高性能で高価なモデルや、クラスタ5のように性能が低いけれども価格を中程度に置けているモデルが存在しているようです!(クラスタ5はブランディングが上手いんだろうな…)
もちろん、データセットにないデザイン等の要素も価格に影響しているとは思いますが……性能面だけで評価しても、クラスターごとに特徴がはっきり出ていて面白いですね!
これらの分析から、携帯電話を開発してる各社がどのようなポジション・ブランディングを狙っているのか参考にできることが学びですね。
また、機械学習のクラスタリング手法を用いることで、大量のデータからザックリとした傾向を見つけ出すことができるということも感じました。
これからもデータ分析の手法を学んで、さまざまな問題に応用していきたいと思います。
以上