Aidemy アプリ開発 課題提出

<成果物>
アップロードされた顔が以下のどの地域の顔の特性に近いかを判定します。
https://funnyfaceclass.herokuapp.com/
①日本系
②欧州系
③オーストロネシア系
開発環境
GoogleColaboratory
画像の取得方法
Bing用クローラーを用いて検索ワードを設定してダウンロードしました。男女比率が同等近くになるようにデータ整理しています。
学習方法
VGG−16のモデルを用いて転移学習させました。
<成果物設定の背景>
私の顔に対して「外国人風の顔に見えるね」とか、「鼻がでかいね」とか、「顔が濃いね」などのコメントを残す知人友人がある一定数いるのですが、
その一方で、日本人顔だよねとコメントする人もいるのでこの差は何なんだろうという疑問を常日頃から抱いていました。
そこでAIによる機械学習により自身の表情により何系の顔と判断されるのか遊び半分真面目半分なエンターテーメント寄り思考で本成果物を作ることに至りました。
(裏の理由は、アノテーションに時間を割くことができなかった。例えば美味しいスイカを判定しようとする場合にはスイカと味のランク付をしなければいけないが、各ラベル数百のデータを集めるには極めて困難だった。
日本文化の侘び寂びを写真から侘び寂び度合いの判定を行おうとしたが、これもランク付けをしなければいけないのはさることながら、侘び寂びは画像だけではわからない見る人の心情など主観も左右されるため極めてランク付が難しい。名高い作品が世の中にはあるが、それをラベル付けしてランクわけするほどの数を見つけるのに大きな手間が発生する。 アノテーションに時間を割くことが実際の現場で多いのは話しに聞くが、今回の課題でそこに時間を割くことは学んだことのアウトプットとして適切ではないと判断しました)
<成果物によって何を解決したのか>
・まず上記地域の人①〜③をある程度の精度で判定できるようになりました。
エポック数が5を超えると検証データの精度が7割で収束してしまいましたが、人の顔を判定するにしてはまずまずの成果ではないかと考えています。
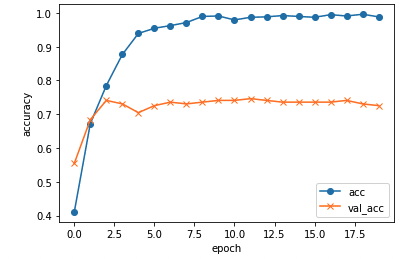
一方で逆に言うと過学習が起こっていたともいえます。
当初は分類は①日本人②中国人③欧州人④オーストロネシア人の4分類で進めていたのですが、データ数は初め各条件200枚でスタートして、検証データ数や画素数、学習率、正規化をして、モデルをこねくり回しても(VGGの転移学習+αのα部分をいくつか書き換えたり)しても精度は5割程度でした。
次に、中国人のデータを削除して分類数を3つへ変更したところ精度が1割程度上がりました。日本人と中国人の顔を分類するにはデータ量が少なくて過学習していたのかと思われます。
更に検証精度を上げるために、データ数が少ないことによる過学習を疑ってデータ数を320枚(増120枚)で行うと検証精度は7割を超えるようになりました。
7割以上を目指して色々とこねくり回したものの改善はせず、更にデータ数を増やす必要があると思われます。
・同一人物であっても、表情によって①〜③に分けることができました。
無表情に近い感情を込めていない証明写真のようなものの場合①日本人と判定されて、顔にシワが入るようなクシャクシャな表情をすると③オーストロネシア人と判定されました。
このように判定される要因の一つは収集した画像データによるかと思われます。③オースとネシア人の顔はシワが入っている傾向が高めでした。
アノテーション用の写真のレベルや表情に地域差があり過学習が起こってしまっていたようにも思いますが、自身の経験的なものと一致するように感じました。つまりは表情豊かに驚いたり顔を歪めたり目を大きくしたり、クシャクシャな顔を作ったりとする場面が多い友人とのコミュニケーションの場において言われることが多かった経験と一致していました。
簡単ですがコードは以下の通りです。
モデル生成コード
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from keras.utils.np_utils import to_categorical
from keras.layers import Dense, Dropout, Flatten, Input
from keras.applications.vgg16 import VGG16
from keras.models import Model, Sequential
from tensorflow.keras import optimizers
from tensorflow.keras.layers import Activation, Conv2D, Dense, Flatten, MaxPooling2D, BatchNormalization
path_jap = os.listdir('/content/drive/MyDrive/train_images/jap2/')
path_itl = os.listdir('/content/drive/MyDrive/train_images/itl2/')
path_aus = os.listdir('/content/drive/MyDrive/train_images/aus2/')
img_jap = []
img_itl = []
img_aus = []
for i in range(len(path_jap)):
img = cv2.imread('/content/drive/MyDrive/train_images/jap2/' + path_jap[i])
img = cv2.resize(img, (200,200))
img_jap.append(img)
for i in range(len(path_itl)):
img = cv2.imread('/content/drive/MyDrive/train_images/itl2/' + path_itl[i])
img = cv2.resize(img, (200,200))
img_itl.append(img)
for i in range(len(path_aus)):
img = cv2.imread('/content/drive/MyDrive/train_images/aus2/' + path_aus[i])
img = cv2.resize(img, (200,200))
img_aus.append(img)
X = np.array(img_jap + img_itl + img_aus)
y = np.array([0]*len(img_jap) +[1]*len(img_itl) + [2]*len(img_aus))
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
# データの分割
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
# 正解ラベルをone-hotの形にします
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# モデルにvggを使います
input_tensor = Input(shape=(200, 200, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# vggのoutputを受け取り、3クラス分類する層を定義します
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.3))
top_model.add(Dense(3, activation='softmax'))
# vggと、top_modelを連結します
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# vggの層の重みを変更不能にします
for layer in model.layers[:19]:
layer.trainable = False
# コンパイルします
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
# 学習を行います
history = model.fit(X_train, y_train, batch_size=100, epochs=20, validation_data=(X_test, y_test))
#acc, val_accのプロット
plt.plot(history.history["accuracy"], label="acc", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_acc", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
result_dir = 'results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
# 重みを保存
model.save("/content/drive/MyDrive/results/model.h5")index.html
<!DOCTYPE html>
<html lang='ja'>
<head>
<meta charset='UTF-8'>
<meta name='viewport' content="device-width, initial-scale=1.0">
<meta http-equiv='X-UA-Compatible' content="ie=edge">
<title>Face Classifier</title>
<link rel='stylesheet' href="static/stylesheet.css">
</head>
<body>
<header>
<img class='header_img' src="templates/pic/iStock.jpg" alt="Aidemy">
<a class='header-logo' href="#">Facce Classifier</a>
</header>
<div class='main'>
<h2> AIが送信された人物の顔をどの地域に住む人の特色が多く含まれているか判定します</h2>
<p>画像を送信してください</p>
<form method='POST' enctype="multipart/form-data">
<input class='file_choose' type="file" name="file">
<input class='btn' value="submit!" type="submit">
</form>
<div class='answer'>{{answer}}</div>
</div>
<footer>
<img class='footer_img' src="https://aidemyexstorage.blob.core.windows.net/aidemycontents/1621500180546399.png" alt="Aidemy">
<small>© 2021 Tetsushi Sakuma, inc.</small>
</footer>
</body>
</html>main.py
import os
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.preprocessing import image
import numpy as np
classes = ["日本顔","ヨーロッパ顔","オーストロネシア顔"]
image_size = 200
UPLOAD_FOLDER = "uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
model = load_model('./model.h5')
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
#受け取った画像を読み込み、np形式に変換
img = image.load_img(filepath, grayscale=False, target_size=(image_size,image_size))
img = image.img_to_array(img)
#data = np.array([img])
#変換したデータをモデルに渡して予測する
result = model.predict(np.array([img]))#[0]
predicted = result.argmax()
pred_answer = "この顔は " + classes[predicted] + " です"
return render_template("index.html",answer=pred_answer)
return render_template("index.html",answer="")
#WebアプリをHerokuへとデプロイし、全世界に公開する手順
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)
<考察と今後の展望>
人の多様性は顔の様々な表情に現れるいることをAIによる機械学習を通じて学ばせて頂いたように思います。自己啓発本などで人の印象は表情が全て のような文言が書いてあるものがありますが穴がち間違っていないのでしょう。
AIを単なる精度を上げてマッチングに使ったり、コスト削減に使う方法ではなくて、人それぞれの多様性を生かすツールとして仲間として、その人らしさをより引き出すものとして、エンターテーメントとして使用する可能性は大いにあるのではないでしょうか。
この感想を得られたことが、Aidemyで学ぼうと思った理由に繋がるところがあり、今後も継続して学習するとともに社会実験に役立てていく大きなモチベーションになるのではないかと思っています。
<葛藤と感謝>
私自身のプログラミング経験が非常に浅い、学習中に途中でPCをMAC M1に変えてしまったために、AI学習以外のところでつまづいてしまったこと、学習時間が平日夜10時以降や休日ということが多くいためにデバック対応などチューター様との調整で時間をとってしまった面があります。このつまづきは今体験することなのか?という葛藤と隣り合わせでした。
葛藤の度に、好きな漫画であるワンピースで レイリーが黄猿に言う「人生とは戸惑いだ」と言うセリフが度々思い浮かんできました。戸惑いの現場にこそ学びと成長があり、本質が含まれているのでしょう。(と信じています)
葛藤だけではなく、親切にサポート頂いているので感謝の念が大きいです。恐らくアウトプットの質としては高いものではないのでこのブログを閲覧される方は非常に少ないと思いますのでお世辞を言うつもりはないです。