
Amazon Kendraの使い方/ナレッジ検索を強化するためのチュートリアル

概要
この記事では、様々なプラットフォームに分散したデータやナレッジの検索機能を提供する Amazon Kendra サービスの使い方を紹介します。
誰に役立つ記事?
社内ナレッジ用の検索エンジン(社内版Google)を作りたい方
Amazon Kendra の使い方を知りたい方
この記事を読んで分かること
Amazon Kendra とは何か?
Amazon Kendra の環境構築手順
Amazon Kendra のデプロイ方法
Amazon Kendraを知ろう
Amazon Kendraとは?
Amazon Kendra は、企業内に分散したデータやナレッジを共通のインターフェースから検索するためのサービスです。

検索に対して、記事のタイトル・本文の抜粋・リンクが表示される点は、Google 検索と変わりません。

Kendraの強み
Kendra の強みは2つあります。1つは、機械学習により非構造化データから関連性の高い回答を抽出できることです。「自然言語 データ活用」といったキーワードを検索はもちろん、自然言語で質問を行うこともできます。
Kendra のもう1つの強みは、複数のプラットフォームとドキュメントを同期できることです。ナレッジ管理では、複数のプラットフォームに分散した情報を取りまとめることが大きな課題になります。Kendra にはメジャーなプラットフォームとのコネクタがあるため、情報集約にコストをかけず、ナレッジ検索を実現できます。

Kendraの料金
Kendra の利用料金は、年間1万ドル程度です。企業向けのエンタープライズ検索サービスとしては、驚くべき安さを実現しています。Kendra の主要な利用料金は、次のとおりです(参考:Amazon Kendra pricing)。
Developer edition
検索上限:4000回/日
最初の30日間の無料枠あり
時間利用料:1.125 USD/時間
コネクタ利用料:0.35 USD/時間(同期実行時のみ)
ドキュメントスキャン料:0.000001 USD/ドキュメント
Enterprise edition
検索上限:8000回/日
時間利用料:1.4 USD/時間
コネクタ利用料:0.35 USD/時間(同期実行時のみ)
ドキュメントスキャン料:0.000001 USD/ドキュメント
Kendraを使うための4ステップ
Kendra は、次の3ステップで実装できます。
Indexをつくる
Index は Kendra サービスの管理単位で、Index ごとに課金が行われます。Data Sourceをつなぐ
Index に Data Source を接続することで、複数のプラットフォームのドキュメントを検索できるようになります。検索性をテストする
開発用の検索コンソールを利用して、Data Source にあるドキュメントの検索性を確認します。Deployして共有する
Kendra を公開して、ユーザーに利用環境を提供します。
1. Indexをつくる
AWSアカウントを作成し、マネジメントコンソールにログインします。ログイン後「Amazon Kendra」サービスのメインページを開きます。
※ 2022年12月現在は東京リージョンが未対応のため、対応しているリージョンを選択します。
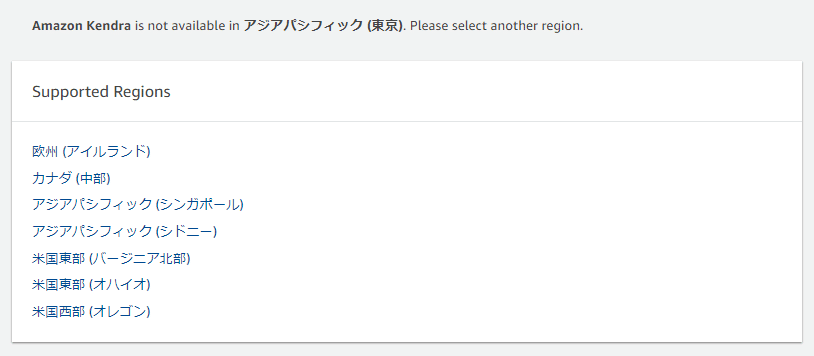
Kendra メインページの「Create an Index」をクリックします。

Index の情報を入力します。
「Index name」には、任意の Index 名を入力します。
「IAM role」では、Index のアクセス制御を行うロールを作成します。

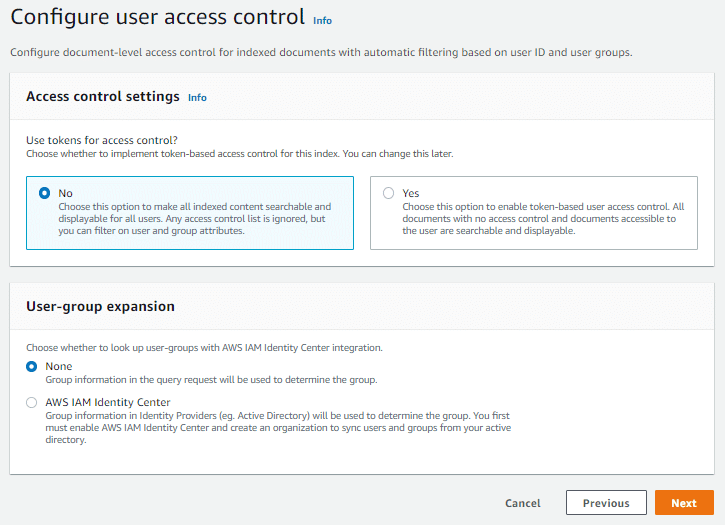
ユーザーアクセス制御を設定します。ここでは、特別な設定は行いません(データが一般に公開されることはありません)。
参考:インデックスのドキュメントへのアクセス制御
Edition を選択します。ここでは、初月無料利用枠のある「Developer edition」を選択します。「Create」をクリックすると Index が作成されます(Index の作成には、最大30分かかる場合があります)。

Index が正常に作成されると、Status 欄に Active と表示されます。

2. Data Sourceをつなぐ
Index にドキュメントを読み込ませるため、Data Source を追加します。Data Source は、各種プラットフォームと同期を行い、ドキュメントの追加・更新・削除を反映します。
画面横のメニューから「Data sources」を選択し、「Add data source」をクリックします。

Data Source では、様々なプラットフォーム上のドキュメントを読み込むことができます。ここでは、特定のウェブページの検索をしてみましょう。「WebCrawler」の「Add connector」をクリックします。
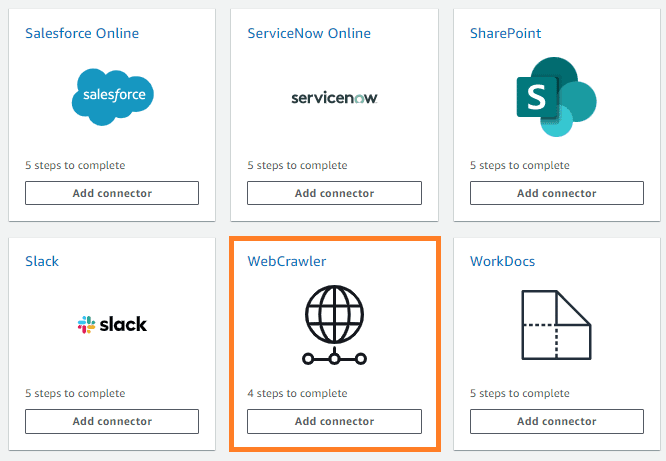
Data Source の情報を入力します。
「Data source name」に任意の Data Source 名を入力します。
「Language」には、対象ドキュメントの言語を設定します。
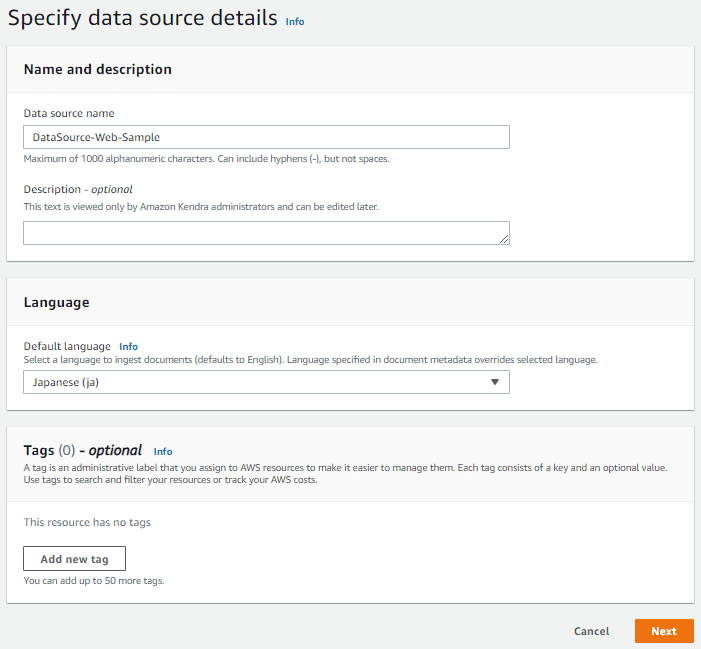
「Source」には、対象となるウェブサイトのURLを入力します。
「IAM role」では、Data Source のアクセス制御を行うロールを作成します。
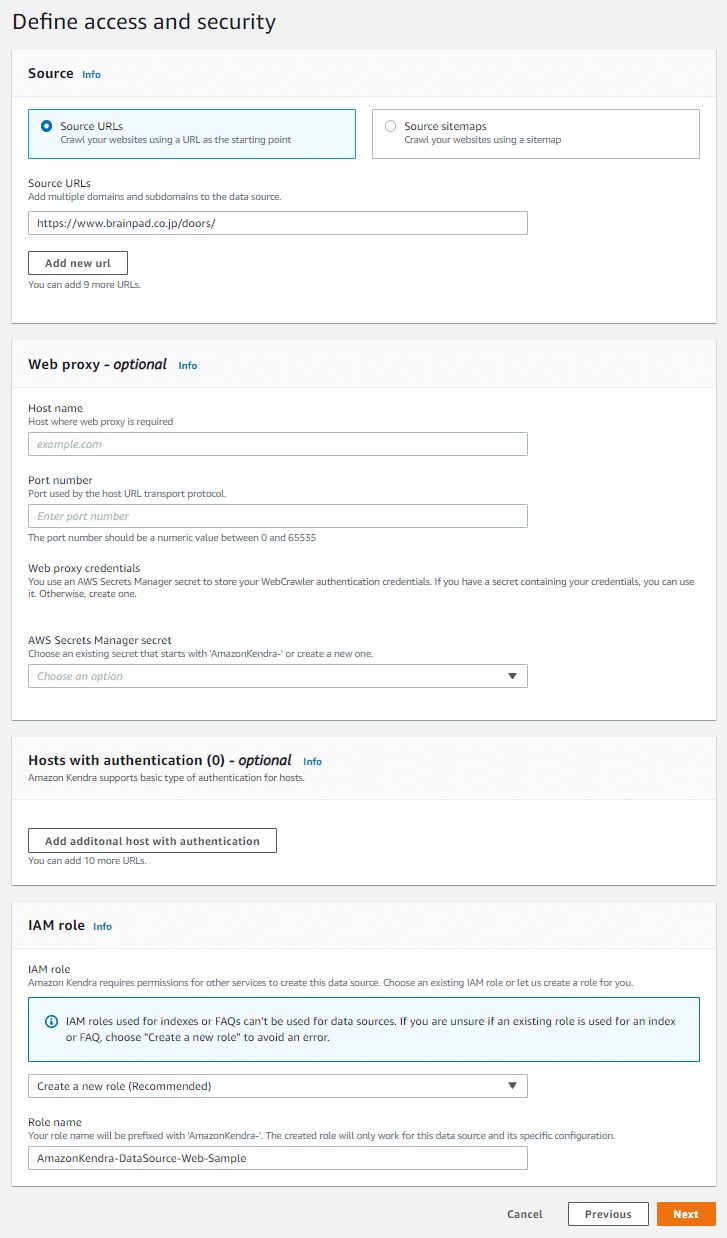
「Crawl scope」では、対象とするドキュメントの範囲を制限します。ここでは「Additional configuration」の「include patterns」を使い、「*/doors/」以下のURLのみを読み込み対象に指定しています。
「Sync run schedule」では、同期頻度を設定します。ここでは自動同期ではなく、「Run on demand」の手動同期を指定します。

確認画面で「Create」をクリックすると、30秒ほどで Data Source が作成されます。作成された Data Source を開き、「Sync now」を実行し、Index にドキュメントを読み込みます。
※ この処理は、ドキュメント量に応じて数分から数時間を要します。

Data Source が正常に読み込まれると、Last sync status 欄に同期結果が表示されます。
Succeeded
正常に同期が完了しています。Incomplete
同期は完了したものの、一部ドキュメントにエラーが発生しています。Failed
同期に失敗しています。

3. 検索性をテストする
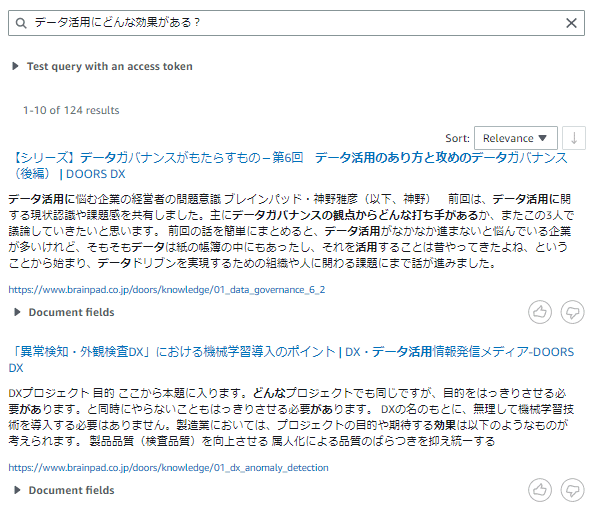
Deploy 前に Data Source の検索性を確認します。画面横のメニューから「Search indexed content」を選択します。

画面右の「Settings」から Data Source で指定した言語を設定して、「Save」をクリックします。

検索バーに適当なキーワードや質問を入力して、関連記事が表示されれば動作確認は完了です。
4. Deployして共有する
Kendra の検索が面をユーザーに共有します。Kendra の Deploy には、2つの方法があります。
Experience Builder
Kendra が提供するサービスを使い、ノーコードで AWS 上に検索画面を実装します。アクセス管理は、AWS の「IAM Identity Center」を使って制御します。React
Kendra はバックエンドとして機能させ、React を使ってフロントエンドを実装します。こちらは、AWS に限らず、任意のプラットフォームに検索画面を実装できます。
ノーコード実装(初級者向け)
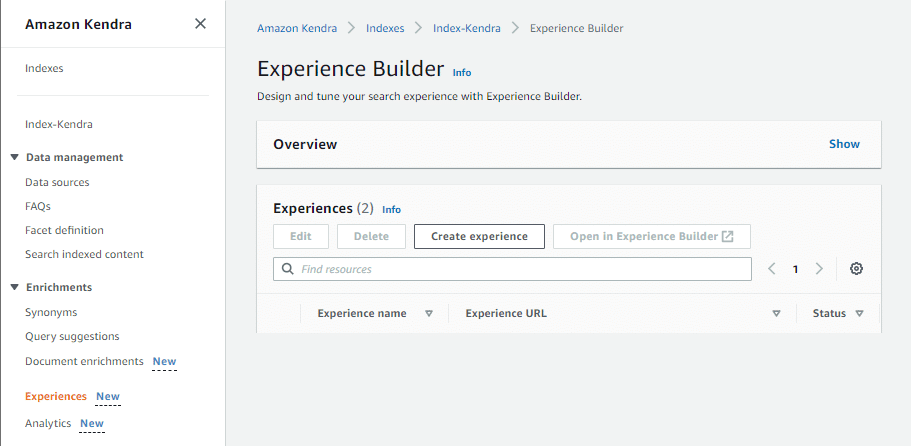
Kendra の提供する検索インターフェースは、Experience と呼ばれます。画面横のメニューにある「Experiences」を開き、「Create experience」をクリックします。
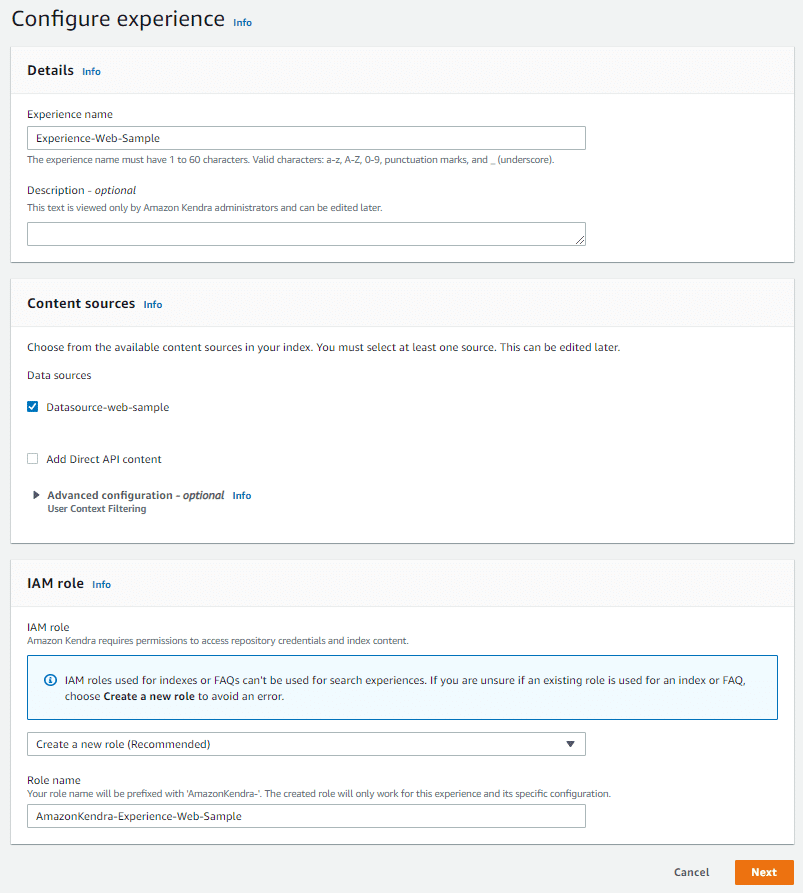
「Experience name」に任意の Experience 名を入力します。
「Content sources」で検索対象の Data Source を選択します。
「IAM role」では、Experience へのアクセス制御を行うロールを作成します。
検索画面へのアクセスを許可するユーザーを設定します。
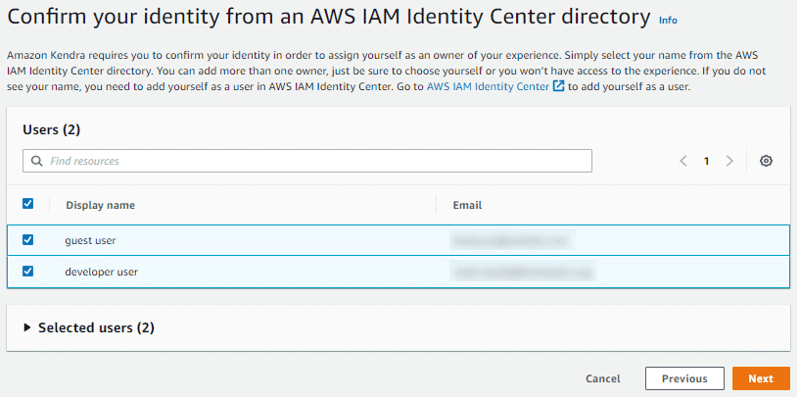
ユーザーは、「IAM Identity Center」で作成してください。検索画面には、設定したユーザー名とパスワードでアクセスします。

「Create Experience and open Experience Builder」をクリックします。数分で Experience が作成されます。
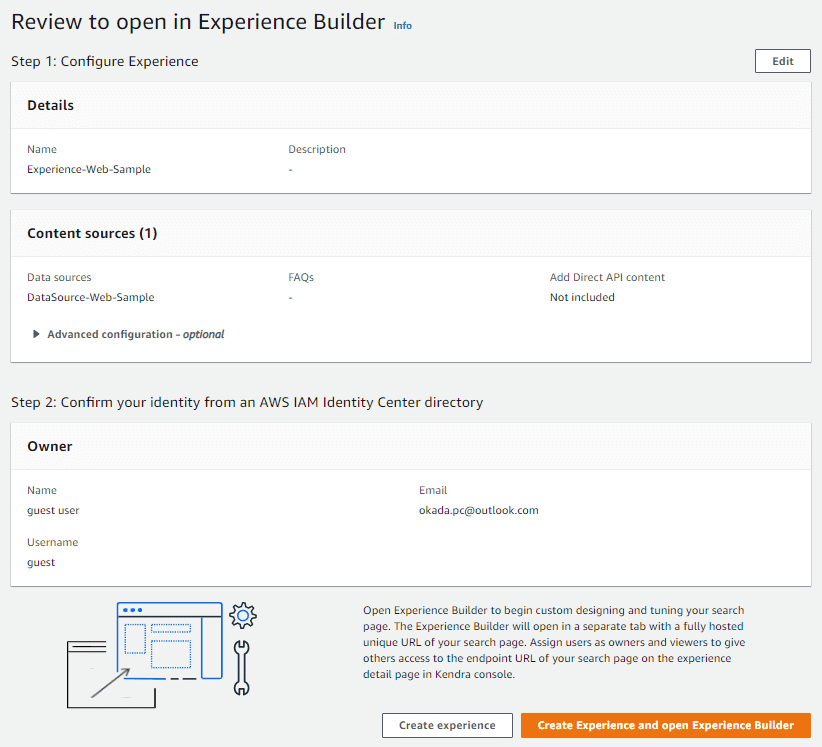
作成された Experience を開き、「Experience URL」をクリックします。
※ この URL には、誰からでもアクセスできます。

登録したユーザー名とパスワードで検索画面にアクセスします。画面が開いたら「Switch to build mode」をクリックします。
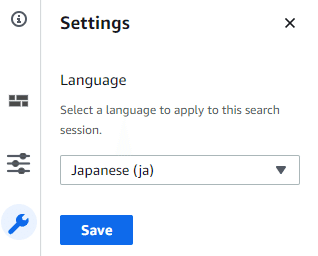
画面右横にある「Settings」からデータソースで設定した言語を選択して、「Save」をクリックします。
検索バーから、関連記事を検索します。
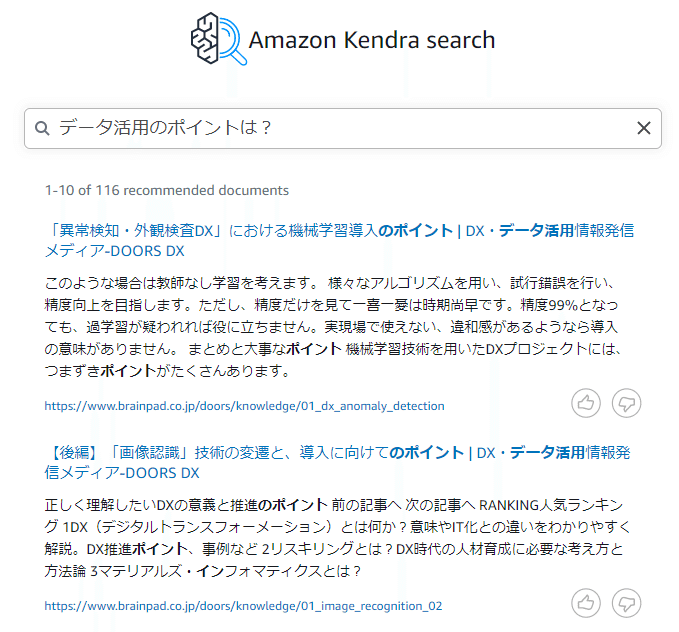
Reactで実装(エンジニア向け)
Experience Builder を使ったノーコードの実装は簡単な反面、検索画面のカスタマイズや、IAM Identity Center 以外のアクセス制御ができません。
そこで、自由度の高い実装に必要な React のサンプルコードを Amazon が公開しています。
aws-kendra-sample-app-master.zip
React は、フロントエンド実装向けの JavaScript ライブラリです。このアプローチでは、 React を使って適当な環境に検索画面を実装し、バックエンドの Kendra で検索を実行します。

ここでは、Google Cloud Platform (GCP) を使ってサンプルコードをデプロイしてみましょう。GCPのプロジェクトを作成し、「Cloud Shell エディタ」のターミナルを開きます。
ホームディレクトリに aws-kendra-sample-app-master.zip をアップロードして解凍します。解凍後、ディレクトリに移動します。
$ unzip aws-kendra-sample-app-master.zip
$ cd aws-kendra-sample-app-masterここで、バックエンドの Kendra へのアクセス情報を設定します。事前に AWS 上で Kendra へのアクセス権限を付与した IAM ユーザーを作成し、「アクセスキー」と「シークレットアクセスキー」を取得します。

Kendra へのアクセスファイルを作成します。
$ cp .env.development.local.example .env.development.local「.env.development.local」ファイルにアクセス情報を記入します。
REACT_APP_INDEX
Kendra の Index 画面に記載されている「Index ID」を入力します。REACT_APP_AWS_ACCESS_KEY_ID
AWS IAM で作成したユーザーの「アクセスキー」を入力します。REACT_APP_AWS_SECRET_ACCESS_KEY_ID
AWS IAM で作成したユーザーの「シークレットアクセスキー」を入力します。REACT_APP_AWS_SESSION_TOKEN
ここでは利用しないため、空白を入力します。REACT_APP_AWS_DEFAULT_REGION
Kendra の Index を作成したリージョンを入力します。
REACT_APP_INDEX='********-****-****-****-************'
REACT_APP_AWS_ACCESS_KEY_ID='********************'
REACT_APP_AWS_SECRET_ACCESS_KEY='************************************'
REACT_APP_AWS_SESSION_TOKEN=''
REACT_APP_AWS_DEFAULT_REGION='ap-southeast-1'サンプルコードでは、検索言語がデフォルトの英語になっています。日本語の Data Source を利用する場合は、「src/search/search.tsx」ファイルの 67 行目の params を以下の次のとおりに変更し、言語を日本語に設定します。
const params = {
IndexId: process.env.REACT_APP_INDEX!,
QueryText: qiueryText,
PageNumber: pageNumber,
AttributeFilter: {
"EqualsTo": {
"Key": "_language_code",
"Value": {
"StringValue": "ja"
}
}
}
};続いて、ビルド環境を構築します。
$ nvm install 18
$ yarn add react-scripts
$ npm install util lodash aws-sdk typescript
$ npm rebuild node-sassソースコードをビルドして、実行します。
$ npm install
$ npm start正常に実行されると、下記メッセージが表示されます。
Compiled successfully!
You can now view aws-kendra-sample-app in the browser.
Local: http://localhost:3001
On Your Network: http://172.17.0.4:3001
Note that the development build is not optimized.
To create a production build, use yarn build.
webpack compiled successfully
Files successfully emitted, waiting for typecheck results...
Issues checking in progress...
No issues found.表示された「http://localhost:****」にアクセスすると、検索画面が表示されます。

ここで production ビルドを行いたいものの、サンプルコードに不備があり、正常に動作しません。そこで「node_modules/react-scripts/scripts/build.js」の12, 13行目を下記のとおり書き換えます。
process.env.BABEL_ENV = 'development';
process.env.NODE_ENV = 'development';デプロイ用のビルドは、以下のコマンドで実行します。
$ yarn buildビルドが完了すると「build」ディレクトリが生成されます。次のコマンドを実行して挙動を確認します。
$ npm install -g serve
$ serve -s build
┌──────────────────────────────────────────────────┐
│ │
│ Serving! │
│ │
│ - Local: http://localhost:46535 │
│ - Network: http://172.17.0.4:46535 │
│ │
│ This port was picked because 3000 is in use. │
│ │
└──────────────────────────────────────────────────┘表示された「http://localhost:*****」へアクセスして、期待の挙動をしていればビルド作業は完了です。
続いて、 Google App Engine へデプロイを行います。まず、デプロイ用に必要な「app.yaml」ファイルを下記の内容で作成します。
runtime: nodejs18
handlers:
# Serve all static files with url ending with a file extension
- url: /(.*\..+)$
static_files: build/\1
upload: build/(.*\..+)$
# Catch all handler to index.html
- url: /.*
static_files: build/index.html
upload: build/index.htmlまた、不要なファイルをアップロードしないように「.gcloudignore」ファイルを下記の内容で作成します。
.*
.*/
src/
public/
node_modules/最後に下記コマンドを実行して、App Engine へのデプロイは完了です。
$ gcloud app deploy環境によって、下記のエラーが出る場合があります。
error Your lockfile needs to be updated, but yarn was run with `--frozen-lockfile`.
その場合は、下記のコマンドを実行します。
$ yarn install改めて、デプロイコマンドを実行して完了です。
$ gcloud app deployまとめ
この記事では、社内ナレッジを共通のインターフェースで検索する(社内版 Google をつくる)ために有効な Amazon Kendra サービスの使い方をまとめました。
ナレッジマネジメントは、多くの企業が抱える大きな課題の1つです。Kendra では主要なデータソースのコネクタを提供しているため、データソースプラットフォームにメジャーバージョンアップがあったとしても、ユーザー側で対応コストがかかりません。リリースして間もないサービスながら、持続的な運用に適した機能を備えています。
分散した社内ナレッジの検索性を改革する Amazon Kendra サービスの今後の進化が楽しみです。