
Federated LearningでSentence BERTをFine-tuningできるか?

はじめまして. BoostDraftでリサーチエンジニアを務めるTomo (LinkedIn) です.
本記事では, Federated LearningでSentence BERTをFine-tuningができるかについてお話ししていこうと思います.
TL; DR
NLIデータセットを基にSentence BERTを仮想的な4台のマシン上でファインチューニングし, Federated Learningした結果, STSデータセットで精度向上が見られた
ただし, マージ頻度によって精度が変わる不思議な挙動が生じた
Federated Learning, Sentence BERT等の説明を飛ばしたい方は実験条件へ!
秘密情報を使ってモデルを学習するには?
BoostDraftのお客様が扱っている契約書というのは非常に専門性の高い情報です. このデータを集めて契約書専門の機械学習モデルを作ったら非常に有用なものができそうです. 一方で, それらのデータは非常に機密性の高い情報でもあります. そのため, お客様からデータを集めるのはあまり現実的ではありません.
本稿では, お客様環境を想定したFederated Learningを用いて, データを集めることなくモデルを分散学習できないか, 基礎的な実験をしてみたいと思います.
※注:現在BoostDraftではお客様のデータを集めたり, お客様環境でモデルを学習させてモデル情報を集めたり, といったことは一切やってません. あくまで実験として見ていただけると幸いです.
Federated Learningとは?
Federated Learning(連合学習)は, 複数の参加者がそれぞれ秘密のデータを各自の端末上に持っている状況で, データそのものを他の参加者に共有することなく, 機械学習モデル等を共有しながら機械学習を行う学習方法を言います.
データを共有しないため, データが他の参加者に開示されることはありません. そのため, 本項の様に機密性の高いデータを多数の参加者がそれぞれ持っているようなケースでの活用が期待されている技術です.
マシン毎の学習とモデルのマージ
Federated Learningは参加者がそれぞれ各自のマシン上に各自のデータをもっている環境を前提にしています. ここでは, 集中型と呼ばれるFederated Learningの基本的な流れをご紹介します.
中央サーバーからモデルを参加者に配布する
参加者は各自のマシン上で各自のデータを用いてモデルを追加学習する
モデルを中央サーバーに送信する
中央サーバーでモデルをマージする
1.-4.を繰り返す

ここでモデルのマージの手法には様々な方法が提案されていますが, 本稿ではもっともシンプルな手法として, 集めたモデルの重みパラメータの平均をとる FedAvg を使用するものとします.
https://arxiv.org/pdf/1602.05629
Federated Learningは参加者の所持するデータに偏りがなく, シンプルなSGDを用いたニューラルネットワークの学習において, データを収集して学習するのと等価になります.
また, この枠組みは特に学習モデルや学習データを特定しておらず, 様々な機械学習に応用可能と思われます.
学習対象:Sentence BERTのFine-tuning
BoostDraftの類似文章検索機能
BoostDraftではベータ機能として, Sentence BERTを用いた類似の文章を検索する機能を持っています. これはSECで公開されている英語の契約書を収集して作った独自データを基に事前に学習したモデルをユーザーのローカル環境で動作させています.
文面の意味を解釈して類似の文章を見つけるために, 文章を数値ベクトルに「埋め込み」, 「埋め込み」ベクトルのコサイン類似度から類似文章を検索しています.
この機能はインターネット上に公開されている英語の契約書のデータを用いて事前に弊社サーバー上で学習したモデルを配布して実現しています. そのため, 英語向けにしか動作しません. もし, この機能をFederated Learningでさらに追加学習することができれば, 英語の類似文章検索性能向上が見込めるとともに, 日本語などほかの言語への応用も可能かもしれません.
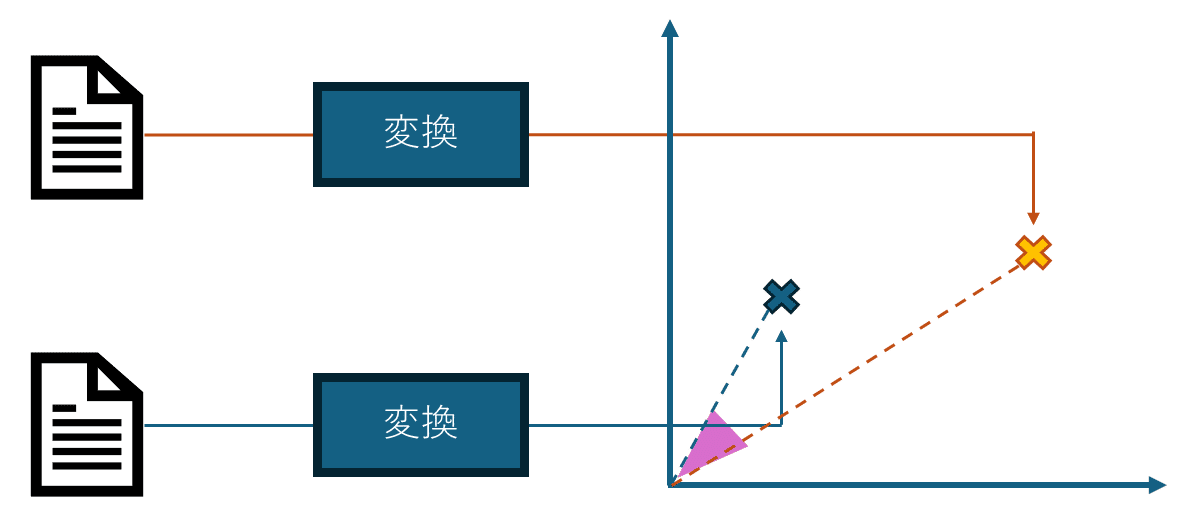
文章の埋め込み
「類似の文章を検索する」ために文章の類似度を定量的に評価することを考えます.
これは文章を数値に変換して, 変換した数字に距離の概念を当てはめることで実現できます.
文章を数値にすることを「埋め込み」と呼びます. これは, 文章を数値ベクトルに変換することで, 様々な文章をベクトル長次元の数値空間にマッピングすることができるからです. 埋め込みの方法はさまざまありますが, その方法が検索性能に直結します. 近年はトランスフォーマーを基とした言語モデルによって文章の文脈をしっかり解釈した埋め込みが可能になってきています. そんな埋め込みの方法の一つがSentence BERTです.
また, 数値に変換した文章の類似度を評価する距離として「コサイン距離(類似度)」が良く使われます. これは, 数値化した文章の「角度」に基づいて, 角度が小さい=距離が近い, 角度が大きい=距離が遠い, と評価する距離指標です.
Sentence BERTとは?
Sentence BERTはトランスフォーマーのエンコーダーであるBERTモデルを基として, 文章の埋め込みの能力を向上させるようにFine-Tuningしたモデルです.
https://arxiv.org/pdf/1908.10084
Sentence BERTの特徴は, 学習時にNLIデータセットやトリプレットと呼ばれるデータを用いることができる点です. NLIデータセットとはある「文章」と「仮説」が与えられたとき, 文章が仮説に対して(「含意」, 「矛盾」, 「関係ない」)の3択からどれが当てはまるかを選択する分類タスクのデータセットです. また, トリプレットとは3つ組の文章がたくさん並んでいるデータセットで, 三つ組みの最初の文章と二つ目の文章は類似であり, 最初の文章と3つ目の文章は意味合いが異なる文章です.
いずれも, 文章の類似度というアノテーションが難しいラベルを用いないため, 学習データを大量に確保するのに向いています. なお, 文章の類似度を数値としてちゃんとラベル化したSTSというデータセットもあります. 今回はNLIデータセットを学習用データセット, STSデータセットを精度テスト用のデータセットとして用いてます.
実験条件
前段が長くなりましたが実験をしていきましょう!
データセット
学習用
3種類のNLIデータセットの混合データセット
MNLI + SNLI + ANLI (約100万サンプル)
テスト用
STSベンチマークデータセット
評価指標=コサイン距離とベンチマークの類似度とのピアソンの積率相関係数
事前学習モデル
MiniLM
Federated Learningの設定
学習データをランダムにシャッフルして4分割
4台のマシンを想定, 分割したデータセットをそれぞれのマシンに配置
各マシンに共通のPre-trainedモデルを配置
マシン毎に分割したデータセットをもとにFine-Tuning
定期的に各マシンのモデルを集め, FedAvgでマージ, マージしたモデルを各マシンに再配置
学習設定
最適化アルゴリズム:SGD
上記のFederated Learningの論文が基本的なSGDに基づいているため, Adam等のバリエーションも利用せず, 様々な最適化手法をオフにしてます
バッチサイズ:16
勾配クリッピング:オフ
スケジューラー:オフ
実験結果と考察
青線:全データを用いて通常の学習
緑線:1/4のデータだけを用いて通常の学習
赤線:4台のマシンでFederated Learning, Step毎にモデルをマージ・再配布
黒線:4台のマシンでFederated Learning, 1000Step毎にモデルをマージ

うまくいった点
ステップが進むにつれ上の図のピアソン積率相関係数と連動して, バリデーションロス(NLIデータセット)も下がっており, 学習は正常に進んでいるように思われます.
このことから, Federated Learningによって, Sentence BERTのファインチューニングでも精度を上げることができる可能性が示唆されました.
疑問, 今後の課題
一方, 疑問点がいくつか出てきました. 最も大きい疑問は, データを全て収集して学習する場合と比較して大きく差が開いたことです. 前述のように, Federated Learningはデータの分布が参加者間で一様で, 学習にSGDを用いるうえでは等価になるはずなのですが. 最適化手法も単純なものを敢えて選択しているので, なぜこんなに差が開いたか現時点ではわかりませんでした.
次に, マージする頻度に依存性がありそうなことです. 毎ステップごとにマージをすると, マージを全くせず1/4のデータのみで学習する場合と比べても性能的に劣りそうです.
これらの現象から, 現状学習の安定性に問題があるのかもしれません. 学習率の調整をして安定性の観点で検証してみることを今後の課題としたいと思います.
最後に
BoostDraftでは私と共に開発を進めてくださるリサーチエンジニアをはじめ, 全方位で採用強化中となりますので, ご興味ある方はぜひ以下のリンク先から採用ポジションをご確認ください.
執筆者:藤野知之(Research Engineer)
SNS: LinkedIn
経歴: 慶応義塾大学にて修士(工学)取得後, NTT研究所にてクラウドWebブラウザ, 製造業向けIoTシステムの開発に従事するとともに映像処理, 生体信号処理, 機械学習アルゴリズムの研究に取り組む. 2022年にリサーチエンジニアとしてBoostDraftに入社後, 検索機能, エラーチェック機能の開発に従事し, 現在は主に生成AIや深層学習モデルを用いた新機能の検討を行っている.