
Stable Diffusionで実写画像からイラスト風Twitterアイコンを作ってみよう

Stable Diffusionで遊ぶ人がたくさん増えて記事も読み切れないほど出ていますが、身近なテーマで実用的な知見があまり見つからなかったのでタイトルのような使用例をまとめたいと思います。
Twitterアイコンにどの写真を使うかは、ツイ廃の悩みどころではないでしょうか?
好きな動物やアニメキャラクターにするのもいいですが、インターネット匿名時代と比べて自分のパーソナリティーを前に出すことが増えてきた昨今では、自分の顔や姿をアイコンにしたいという需要は多いように思います。
しかし実際の自撮り写真を使うことに抵抗のある人は少なくないでしょう。かくいう私もアイコンはイラスト画像を使っています。
Stable Diffusionは画像を生成する際にベースとなる画像を入力に与えることもでき、それをもとに入力テキストの情報を反映したような画像を生成することができます。
これを利用することでTwitterのようなSNSのアイコン向けに、自分の写真をベースにしたイラスト風画像を生成することができます。
ここまで読んで「難しそうだから自分でやるのは厳しいかも・・・」という方は以下のココナラさんで環境構築のご依頼をお受けしてますので、もしよろしければご覧ください。上場企業のサービスですのでトラブルの心配はありません。
https://coconala.com/services/2512083?ref=top_favorites&ref_kind=home&ref_no=1
環境
Google Colaboratory(無料版でOK)
Hugging Face (トークンを取得。無料)
Hugging Faceトークンを取得
以下のリンクからHugging Faceアカウントを作成します。メールアドレスとパスワードを入力して「Next」を選択します。
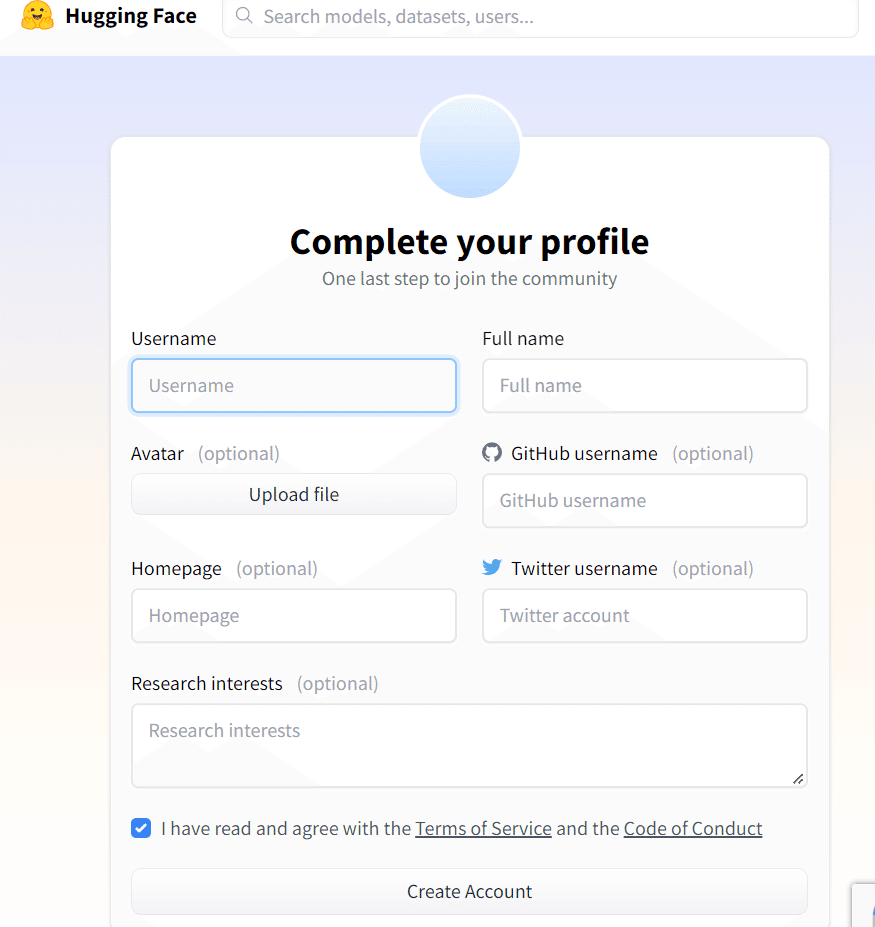
更に詳細情報を求められるので、「Username」と「Full name」のみ入力してチェックボックスにチェックを入れて「Create Account」を選択します。
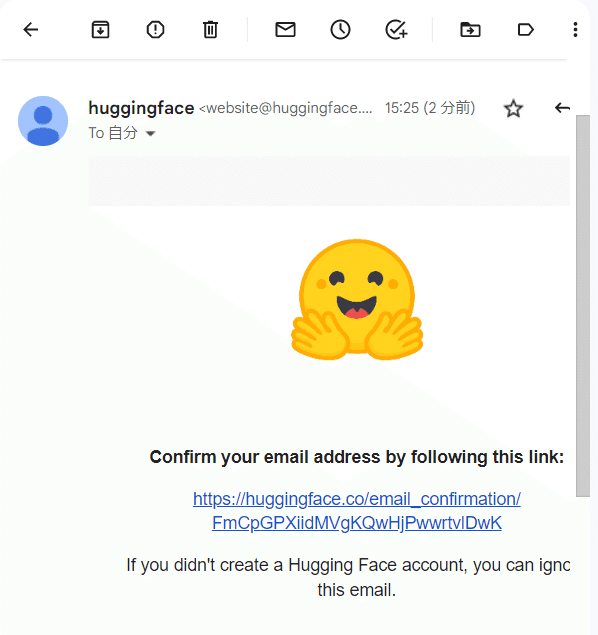
入力したアドレスに認証メールが送信されるので、開いてリンクをクリックします。
Hugging Faceにログイン画面に進むので、アドレスとパスワードを入力してログインします。右上のハンバーガーボタンを選択→「Settings」選択→「Access Token」を選択します。
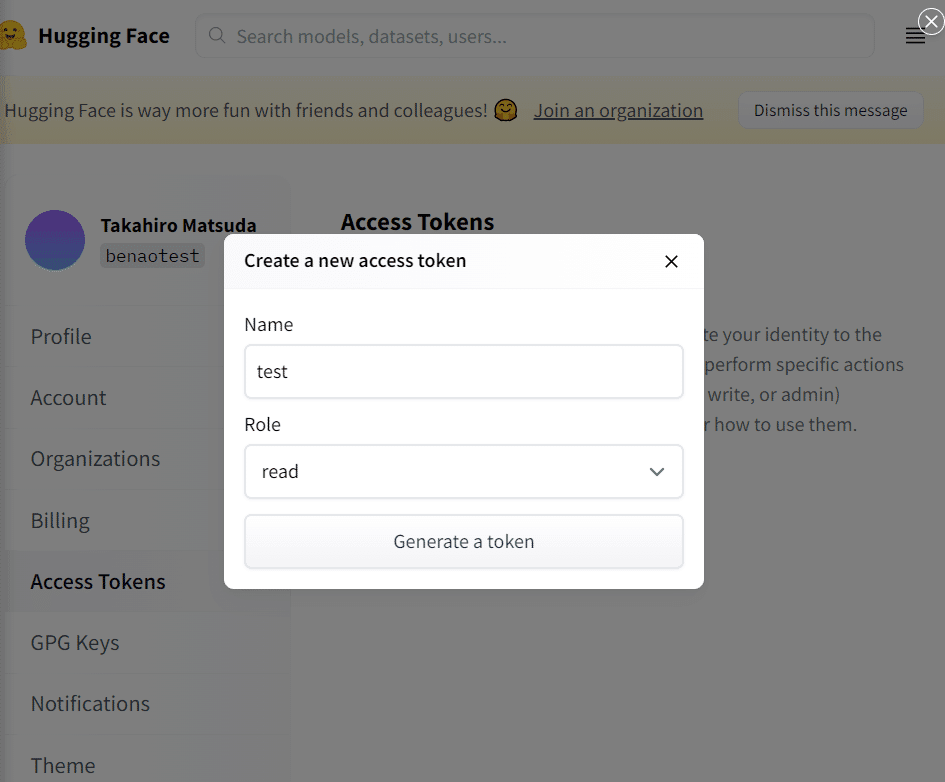
「New Token」を選択すると上画像のようなポップアップが表示されるので、Nameに適当なキー名を入力して「Generate a token」 を選択します。
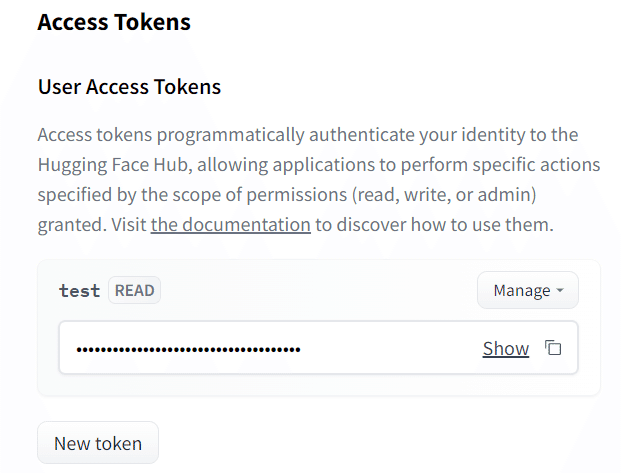
トークンが生成されるので、右側のコピーボタンでコピーして使います。
最後の準備でStable diffusionモデルへのアクセス権を取得します。ログイン後に以下のリンクにアクセスしてください。

モデルを使用する場合は連絡先が開発者に共有され、違法なコンテンツなどの作成はできない等の説明が記載されています。
チェックボックスにチェックを入れて「Access repository」を選択します。
Google colaboratoryで実行
Google colaboratoryを新規ノートを作成してPythonコードを入力していきます。
最初にGPUの設定をします。ツールバーの「ランタイム」を選択→「ランタイムのタイプを変更」を選択→「ハードウェアアクセラレータ」を「GPU」に変更して保存します。

!pip install --upgrade diffusers==0.3.0 transformers scipy
ACCESS_TOKEN="<取得したトークン>"必要なライブラリのインストールと前章で取得したをトークン準備します。
import torch
from diffusers import StableDiffusionImg2ImgPipeline
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=ACCESS_TOKEN
).to("cuda")StableDiffusionImg2ImgPipelineは、画像から画像を生成するための学習モデルを作るためのものです。from_pretrained関数の引数にモデル名やトークンを与えることで、Hugging Faceからモデルと設定をダウンロードします。
ここで生成画像の ベースとなる画像を用意します。BTSメンバーのジョングクの写真でやってみます。

Google colabo画面の左側のファイルアイコンをクリックし、「セッションストレージにアップロード」から画像ファイルをアップロードします(jpgまたはpng推奨)。「content」ディレクトリ直下に置かれていることを確認してください。
from PIL import Image
from torch import autocast
init_image = Iage.open("image.jpg").convert("RGB")
init_image = init_image.resize((512, 512))
input_txt = "Illustration of a young male anime character"
with autocast("cuda"):
images = pipe(
prompt=input_txt, # 入力テキスト
init_image=init_image, # ベース画像
strength=0.7, # 入力画像からの修正度合 (0.0-1.0)
guidance_scale=7.5, # プロンプトの影響を調節 (7-11)
num_inference_steps=50, # ステップ数
).images
images[0].save("icon.png")画像ファイルを扱うためにPILライブラリを使います。input_textには生成したい画像についての説明を英語で入力します。今回は「若い男性のアニメキャラのイラスト」と英文で入力しました。必要に応じてGoogle翻訳で作成してください。
実際は一度に目的の画像が生成されることはまれなので、上記のコードブロックを複数コピーするかループ処理を行うと便利です。
全てのコードを実行すると、「content」ディレクトリ直下に画像ファイルが保存されます。
生成結果
下記のような画像が生成できました。



Twitterアイコンであればスマホアプリでは表示は極めて小さくなるので、多少の粗さは問題ないと思います。背景の色合いも大まかに再現していますね。
画像生成がうまくいったらTwitterで教えてください。フォロー・スキもうれしいです。
サポートは料理好きなのでの食材費にさせていただきます。