RLS + 大量データ下でクエリチューニングして100倍高速化した話

Beatrust で SRE をやっている Yuta (中川 裕太) です.運用がラクにできるように色々と改善したり,セキュリティ向上したり,インフラ作ったり API 開発したりしています. 今回のブログでは,Row Level Security (RLS) 下で現実的なレイテンシで大量データを扱うためにクエリをチューニングした結果とそこから学んだプラクティスを紹介します.
モチベーション
Beatrust ではセキュリティ向上のために,顧客 (テナント) ごとにデータを論理的に分離する RLS を用いています.
おかげさまで Beatrust は BtoB サービスとして順調に成長しており,創業3年目のタイミングで 1 顧客あたり数万人規模のお客様の導入も現実味を帯びてきました.RLS はその性質上,データ量の増加に伴い性能が劣化しやすいことが知られており,数万人規模のお客様導入に先んじて性能影響を明確にしたい想いがありました.そこで 1 顧客あたり 10 万人を目標値として設定し,テスト用のテナントを作成し検証を行いました.その結果,Lazy load はしていますが,画面全体を描画するのに平均 5 sec 以上かかることが分かり,パフォーマンスチューニングの必要性が明確になりました.
パフォーマンスチューニングの方向性としては,API を REST から GraphQL へ移行する方法や,データベース自身を PostgreSQL から変更する方法なども考え得ますが,まずはクエリチューニングだけでどこまで大量データに耐えれるかを知りたかったため,今回はクエリチューニングだけを対象としました.
Toy dataset
クエリチューニングをするために,まずは toy dataset を作りパフォーマンスチューニングの勘所を探りました.
Beatrust では tag を用いてそれぞれのユーザを表現しており,1 ユーザあたり平均十数 tag ついています.つまり,10 万人規模では 100 万 tag 規模となるわけです.さらに ACTIVE なユーザの約 8 割が付与している tag が存在するテナントも多くあります.この大量データが性能のボトルネックとなることは分かっていました.また,事前調査の結果,カラムのデータ型と RLS policy によって大きく性能が変わりそうなことがわかっていました.そこで,以下のような user と tag table を簡素化した 4 種類の toy dataset を作ることにしました.

Beatrust における tag A. CITEXT 型 + 間接 RLS
CREATE TABLE "user" (
id TEXT PRIMARY KEY,
tenant_id TEXT NOT NULL
);
CREATE INDEX ON "user" (tenant_id);
ALTER TABLE "user" ENABLE ROW LEVEL SECURITY;
CREATE POLICY user_isolation_policy ON "user" USING (
tenant_id = current_setting('app.tenant_id', true)
);
CREATE TABLE tag (
id TEXT PRIMARY KEY,
name CITEXT NOT NULL,
user_id TEXT NOT NULL REFERENCES "user" (id)
);
CREATE INDEX ON tag(user_id, name);
ALTER TABLE tag ENABLE ROW LEVEL SECURITY;
CREATE POLICY tag_isolation_policy ON tag USING (
user_id IN (
SELECT id FROM "user" WHERE tenant_id = current_setting('app.tenant_id', true)
)
);
B. TEXT 型 + 間接 RLS
CREATE TABLE "user" (
id TEXT PRIMARY KEY,
tenant_id TEXT NOT NULL
);
CREATE INDEX ON "user" (tenant_id);
ALTER TABLE "user" ENABLE ROW LEVEL SECURITY;
CREATE POLICY user_isolation_policy ON "user" USING (
tenant_id = current_setting('app.tenant_id', true)
);
CREATE TABLE tag (
id TEXT PRIMARY KEY,
name TEXT NOT NULL,
user_id TEXT NOT NULL REFERENCES "user" (id)
);
CREATE INDEX ON tag(user_id, name);
ALTER TABLE tag ENABLE ROW LEVEL SECURITY;
CREATE POLICY tag_isolation_policy ON tag USING (
user_id IN (
SELECT id FROM "user" WHERE tenant_id = current_setting('app.tenant_id', true)
)
);
C. CITEXT 型 + 直接 RLS
CREATE TABLE tag (
id TEXT PRIMARY KEY,
name CITEXT NOT NULL,
tenant_id TEXT NOT NULL
);
CREATE INDEX ON tag(tenant_id, name);
ALTER TABLE tag ENABLE ROW LEVEL SECURITY;
CREATE POLICY tag_isolation_policy ON tag USING (
tenant_id = current_setting('app.tenant_id', true)
);
D. TEXT 型 + 直接 RLS
CREATE TABLE tag (
id TEXT PRIMARY KEY,
name TEXT NOT NULL,
tenant_id TEXT NOT NULL
);
CREATE INDEX ON tag(tenant_id, name);
ALTER TABLE tag ENABLE ROW LEVEL SECURITY;
CREATE POLICY tag_isolation_policy ON tag USING (
tenant_id = current_setting('app.tenant_id', true)
);
なお,8 割の user が持っている tag は Beatrust として検証を行いました.
また,性能検証の対象とするクエリについては,Cloud SQL の Query Insights から最も性能のボトルネックとなっていた以下のクエリを選びました.
SELECT COUNT(*) FROM tag WHERE name = 'Beatrust';
クエリチューニングの勘所
PostgreSQL のバージョンによって実行計画が異なる可能性はあるため,本番環境とあわせて PostgreSQL 13.7 を用いて検証を行いました.toy dataset を用いた検証で明らかになった RLS + 大量データ下でのクエリチューニングの勘所は以下 3 つです.
RLS key と search key に複合 index を張る
CITEXT など複雑なデータ型は避ける
直接的な RLS policy を使う
説明の都合上,順番は入れ替えますが,以下で細かく見てきます.
CITEXT など複雑なデータ型は避ける
Beatrust では tag を case insensitive に扱う (Python と python を同一視など) ためにデータ型に CITEXT を用いていました.しかし,RLS + 大量データ下での実行計画を見てみると,index が正しく使われていないことが分かりました.そこで,toy dataset C, D を用いてカラムのデータ型による性能影響を検証しました.
tag の総数に対する実行計画のコストをグラフにしてみると以下のようになり,100 倍以上の性能差が生じることがわかりました.

CITEXT と TEXT のコスト差
より詳細にデータを見てみると,理由は不明ですが,CITEXT を利用した場合にはテナントの tag の総数にコストが比例しており,TEXT を用いた場合には抽出された列数 (今回でいうと Beatrust の tag 数) にコストが比例しているように見えました.おそらく,RLS を用いると実行計画が保守的になる点と PostgreSQL が追記型のアーキテクチャを取っている点が要因ではないかと想像しています.
以上の結果から,データ型を CITEXT から TEXT に変えることで大きく性能が向上することがわかりました.そこで,表示用の name とクエリ用の lower_case_name をそれぞれデータモデルに持たせ,アプリケーション側で case insensitive なクエリになるよう実装を変更しました.これにより,レイテンシが数十倍以上改善されました.
CREATE TABLE tag (
id TEXT PRIMARY KEY,
name TEXT NOT NULL,
lower_case_name TEXT NOT NULL,
user_id TEXT NOT NULL REFERENCES "user" (id)
);
直接的な RLS policy を使う
もともとは正規化されたデータモデルを用いており tenant_id => user => tag の関係で間接的な RLS を tag にかけていました.しかし,この間接的な RLS では実行計画が複雑でチューニングが難しかったこと,また,性能が出づらいなどの記事を見つけ,toy dataset B, D を用いて直接的な RLS と性能を比較することにしました.
tag の総数に対する実行計画のコストをグラフにしてみると以下のようになり,10 倍近い性能差が生じることがわかりました.

直接的な RLS (direct) と間接的な RLS (indirect) のコスト差
より詳細にデータを見てみると,間接的な RLS ではテナントの user の総数にコストが比例し,直接的な RLS では抽出された列数にコストが比例しているように見えました.同名 tag は高々 user 数なので,Beatrust のケースでは非正規化をして直接的な RLS に変えたほうがよいという結果を得ました.これにより,レイテンシはさらに 100 msec 程度改善されました.
CREATE TABLE tag (
id TEXT PRIMARY KEY,
name TEXT NOT NULL,
lower_case_name TEXT NOT NULL,
tenant_id TEXT NOT NULL
);
RLS key と search key に複合 index を張る
RLS を利用する際には,RLS の key となるカラム (今回でいうと tenant_id) と通常 index を張る検索対象のカラム (今回でいうと name) で複合 index を張るべきという記事をしばしば見かけます.Beatrust ではそのプラクティスに従いすでに複合 index は張っていましたが,改めてその効果を検証するために toy dataset D に対して index の張り方を変えることでどのようにコストが変化するかを検証しました.
tag の総数に対する実行計画のコストをグラフにしてみると以下のようになり,確かに複合 index を張ることで 100 倍近い性能差が生じることが明らかになりました.
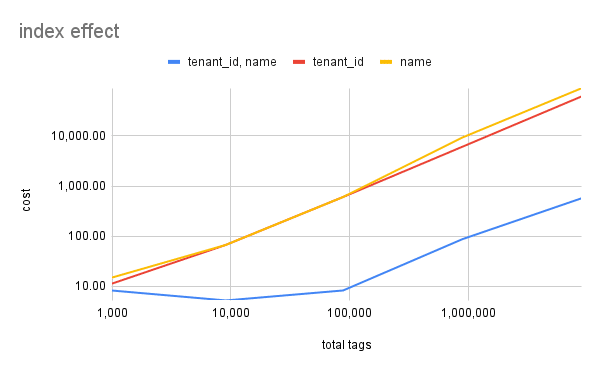
index の違いによるコスト差 まとめ
今回紹介したスキーマレベルのチューニングに加え,簡単な SQL レベルのチューニングも実施し,RLS + 大量データ下でも,平均 5 sec 以上かかっていたエンドポイントを数十 msec まで改善することができました.toy dataset を作り簡単なケースで勘所を掴みつつ実際のクエリチューニングを進めた点は非常によかったなと感じています.RLS 下では性能が出にくいという話は多いですが,実行計画を睨みつけつつ,toy dataset を用いて検証することで大量データに対しても数十 msec 程度までであれば改善できることを知れたことは大きな学びです.
とはいえ,今回の検証を経て 1 テナントあたり 100 万人規模を超えるころには今の PostgreSQL では限界が来ることも分かりました.そのころには,システム全体のアーキテクチャを見直す必要はあると考えています.そんなフェーズを早く迎えれるようプロダクトを成長させていきたいです.
一緒に楽しくプロダクト成長と安定運用のバランスにチャレンジできる仲間を募集中です!