
Behind Scout - Lessons from building an AI-powered Skill Matching Feature

Hello, I'm Yuta and SRE at Beatrust. I'm in charge of the overall architecture, notably ML-related. Today, I'm going to look back at the architectural decision of a new product in Beatrust and its lessons.
New feature and its algorithm
We are providing an internal SNS-like product and released a new feature called "Scout" internally as alpha on September 1st, 2024 and to some clients as beta on November 1st, 2024. It provides a good search function with natural language based on the skills extracted from the existing data in our platform.
https://prtimes.jp/main/html/rd/p/000000072.000062843.html
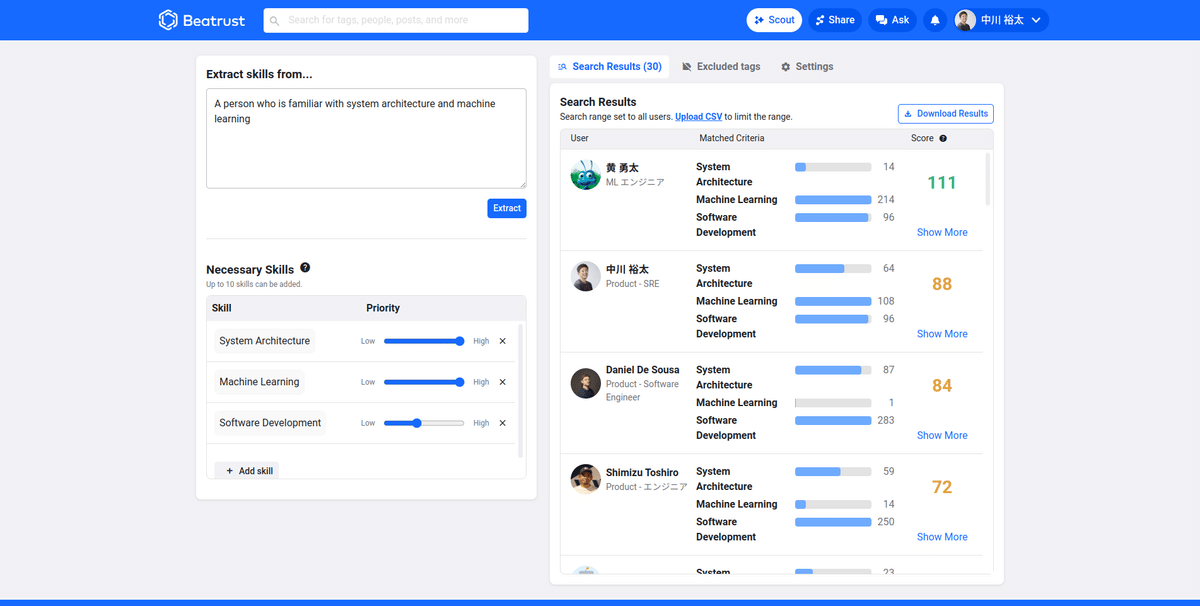
This feature consists of two steps. The first step is the precomputation to extract skills from the existing profile data in our platform. The second step is to search for users who have the skills with natural language. Each step is divided into several steps.
Precomputation
Extract the skills from the existing profile data with LLM.
Embed the skills into a vector expression with a sentence embedding model.
Store the embeddings in a vector store and the linkage between the profile data and skills into the relational database.
Online search
Extract the skill from the natural language input with LLM.
Embed the skills into a vector expression with a sentence embedding model.
Search for similar skills from the vector store with the embeddings.
Return the results linked to similar skills in the precomputation steps.
Overall architecture
This is the architecture that implements the above algorithm.
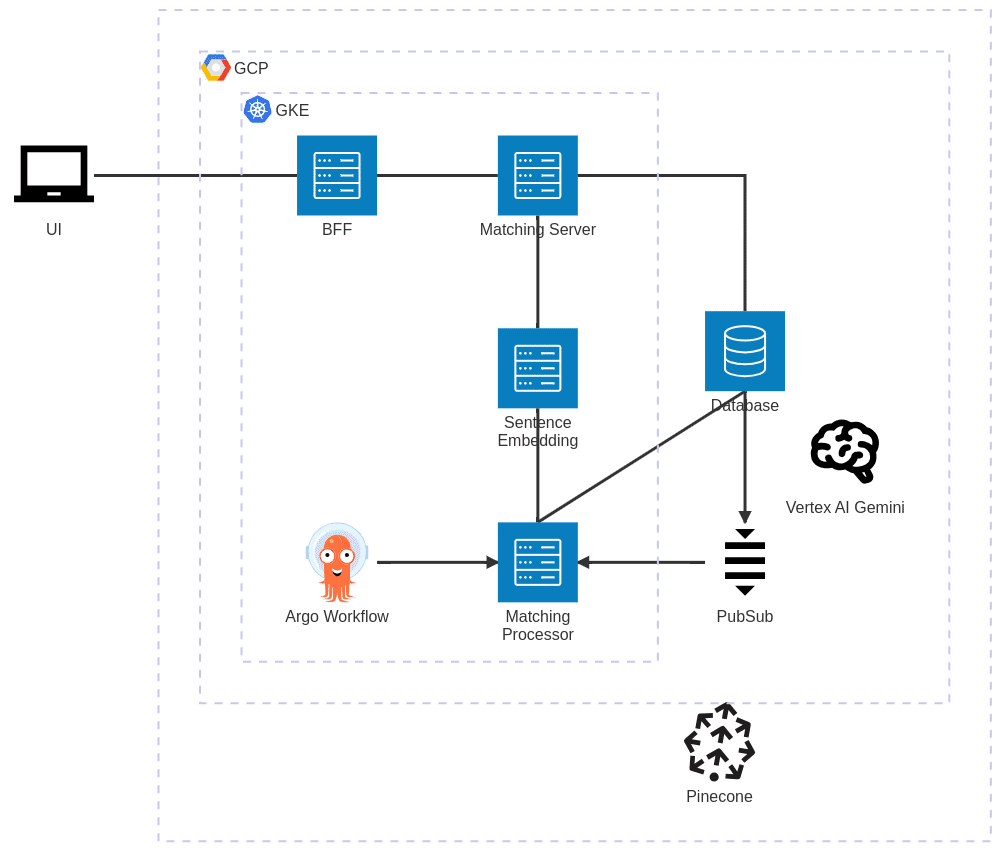
The main requirements that needed to be considered to decide the architecture were the following.
The architecture should be scalable enough because it will be the main component of the future roadmap though it won't be called so frequently in the beginning.
Our platform already has a lot of profile data in four years of operation. But the update frequency isn't so large. If we run the precomputation for all the existing data even daily, it exceeds our current cost. Hence, we need to compute it differential-base.
Strict real-time is not required but near real-time is required to search for the latest data.
Based on these requirements, we decided to take the above architecture. The main points are:
1. Hosting the embedding model with high scalability
We've already managed Python monolith for three years to host ML models and implement business logic, which has a lot of scalability and cost-inefficiency issues. We wanted to take a different approach because it's a new feature.
We initially thought to use an ONNX model from Go because we use Go for microservices but onnx-go was already archived (now it's maintained by a different user though) and other libraries weren't pure Go libraries, which is a no-go for us because the developers use multiple OS.
That's why we decided to separately deploy the embedding model and business logic as microservices with Python and Go.
2. Implementing differential-based precomputation
It's not that easy to implement differential-base precomputation when considering model updates. If the models are not updated, the computation should be run only on newly inserted/updated data. But if the model is updated, it should be run on all data.
We already use Change Data Capture (CDC) on PostgreSQL in a different feature and thought it would be good to use it also in this feature because it's easier to trigger the computation in differential-base and run in near real-time.
We also decided to implement a manual script for the precomputation of all the existing data. It supports the case of model updates as well.
Details in each service
I'm going to explain each service and add some detailed decisions.
BFF
This service calls Matching Server to get the search results and decorate additional information fetching from the database. We decided this way in order to make BFF thin enough and Matching Server access the minimum tables in the database.
Matching Server
This service conducts the online search steps. We implemented only business logic here and didn't add any ML models to clearly split from Sentence Embedding.
Sentence Embedding
This service embeds the skills into the vector expression. We decided to use torchserve to host the sentence embedding model. We tried Vertex AI PyTorch integration and realized it's just a wrapper of torchserve. However, the torchserve version of the integration is a bit outdated and it's easier for us to deploy torchserve to GKE instead of using the integration because we can reuse many internal libraries for microservices, e.g. authentication/authorization and tracing.
We initially used the prediction endpoint for a health check but noticed it was unstable because it could call the endpoint before the model load. After changing it to check the model status from the management API with the following Python script, the stability was quite improved.
import json
from urllib.request import urlopen
with urlopen('http://localhost:9080/models/model') as f:
res = json.load(f)
if res[0]['workers'][0]['status'] != 'READY':
raise Exception('Model not ready')
print('Model is ready')Matching Processor
This service pulls the Pub/Sub events containing CDC logs from the database and conducts the precomputation steps. The interesting point of this service is that we decided to launch an internal Connect RPC server, fetch Pub/Sub events, and send them to the internal server. The benefit of this approach is that we can reuse the internal libraries here as well.
LLM
We decided to use Vertex AI Gemini for LLM because the performance and the cost are competitive compared with other services. It's also product-friendly because we can easily control permission with IAM as we use GCP and it supports JSON output mode which is useful when we use strict typing.
Vector Store
We decided to use Pinecone as a vector store because I personally have experience implementing and managing a vector store (you can see my old presentation slides). That was really tough because all the processes should be handled in memory to get reasonable latency while handling proper transactions. Even though Pinecone is not cheap, we decided it's worth paying for it considering the many challenges in a vector store.
Summary
We've implemented the new feature with carefully designed architecture. Because of that, we haven't had any critical issues for three months of operation since the alpha release. It's also cost-effective because the cost is about 10% of the total cost, which is cheap enough for a new service considering the "AI system" tends to be expensive.
The remaining challenge of the system is to stabilize Gemini and Pinecone. Even with retries calling them, they sometimes still return internal errors. We hope they will be stabilized but we could also consider controlling the frequency of calling them in Matching Processor. From the business point of view, the biggest challenge would be how to improve the results. We already implemented a dashboard to see the usage statistics and plan to have user interviews to get both quantitative and qualitative results. We will continue improving this feature based on those feedbacks.
We are hiring those who are interested in working with many talented members in a bilingual environment!
https://en.corp.beatrust.com/careers