BERTのレイヤー数削減による多言語キーフレーズ抽出モデルの軽量化・高精度化

こんにちは、Beatrust で Machine Learning Lead をしている Tatsuya (白川 達也)です。
以前、下記の記事でキーフレーズ抽出機能のご紹介をしましたが、その後の試行錯誤をした結果、以前に比べて軽量化・高精度化に成功したので、これまでにどのような工夫をしたのかをご紹介しようと思います。
下記は今回ご紹介する現状のキーフレーズ抽出における知見です。
多言語BERTモデルを使っておくと、キーフレーズ抽出用に fine tune しても結構多言語転移できてしまう。
キーフレーズ抽出において、BERTはフルレイヤーである必要はなく、最初の数層程度で十分。
BERT のAttention Map のみからでもキーフレーズの推定はできるが、BERTの出力をそのまま使ったほうがロバストっぽい。
モデルの最後に Bi-LSTM のような Sequence Decoder を入れておかないと IOB タグ予測などは変な結果になりやすい
モデルの量子化をすると大幅に高速化もできる。
辞書ベースのキーワード候補抽出による教師なし学習でもかなりうまく学習でき、辞書メンテのみでモデルの学習を改善できる。
Beatrustにおけるキーフレーズ抽出
キーフレーズ抽出とは、与えられたテキストからキーフレーズとよばれる何らかの観点で重要なフレーズを抽出してくるタスクです。たとえば下記の文書の場合、Beatrust、機械学習、データ分析といったフレーズがキーフレーズになります。

Beatrust では、各種テキストデータを解析するためのコアエンジンの一つとして、キーフレーズ抽出エンジンを研究・開発しています。キーフレーズ抽出エンジンはプロフィール情報からユーザーに自身をあらわすタグを推薦したり、Askという質問回答プラットフォーム上での質問内容にキーワードをSuggestするのに使われています。
Beatrustにおけるキーフレーズの課題
1. 多言語対応していること
Beatrust のユーザーには日本語話者だけでなく英語話者も一定数存在しており、今後海外進出していくことも前提としてプロダクト開発を行っているため、多言語対応(特に日・英)が可能である必要があります。言語ごとにモデルを作り込むことももちろん考えられるのですが、アーキテクチャが複雑化したり学習リソースを効率的に利用することが難しくなるので、単一モデルでの多言語対応を目指しています。
2. 多種多様なドメインに対応できること
Beatrust のお客様は製薬業界から商社に至るまで、さまざまな業種・業界に渡っており、異なる背景のそれぞれのお客様に対して一定品質以上の体験を提供する必要があります。それぞれのお客様の業界では、固有の専門用語が存在しており、さらには社内用語のようなものも頻繁に使われています。こういった特殊用語を Beatrust サイドで蓄積・メンテしていくことは現実的に難しいため、必然的に未知のキーフレーズにたいしてもロバストなモデルを作っていくことが求められます。これは想像以上にハードでチャレンジングですが、非常に面白いです。
3. 動作が高速かつ省メモリであること
プロダクト上でリアルタイムに動作させる必要があるため、高速かつ省メモリで動作することは重要になります。UI/UX の工夫次第である程度の解析遅延は許されるのですが、あまりにも解析時間がかかりすぎると、ユーザー離脱を引き起こすかもしれません。そのため、可能な限りユーザーにとって快適な体験を提供できるよう、解析エンジンの遅延がむやみに長く感じられない程度の高速化は必要です。Beatrust では主にCPUを用いて解析を行っているため、リッチなロジックを CPU でも高速に動作させることは非常に大きなチャレンジとなっています。
これまでのキーフレーズ抽出エンジン
上記のとくに 1、2 を意識してこれまでは下記のような多言語 BERT モデルにもとづくエンジンを作っていました。詳細については先程ご紹介したブログ記事をご参照ください。
このエンジンはテキストデータと辞書データを与えれば一切アノテーションすることなく多言語キーフレーズ抽出モデルが得られるので、学習に関してはスケーラブルでしたが、量子化はしているものの推論速度がまだ不十分で、さらなる高速化が必要でした。また、精度面でも取りこぼしが多く、改善が必要でした。
高速化を狙って: UCPhrase 論文との出会い
どう高速化しようかと思案していたとき、KDD2021 で発表された下記の論文に出会いました。
X. Gu+, "UCPhrase: Unsupervised Context-aware Quality Phrase Tagging", SIGKDD21
この論文については当時の自分の課題にジャストミートしたので KDD2021読み会 で発表もしました。発表資料はこちらです。
2021 10-07 kdd2021読み会 uc phrase from Tatsuya Shirakawa www.slideshare.net
この論文では Beatrust の旧来の方法と同様に、教師なしでキーフレーズ抽出を行う方法を提案しており、下記のような主張をしています。
学習データには辞書ベースのフレーズ抽出ではなく、頻度ベースのフレーズ抽出(Core Phrases)を使うべき。
BERT の Feature をキーフレーズ抽出に使うと過学習するので、Attention Map のみを使う。しかもfine tuneしなくてよい。
BERT のレイヤーは最初の 3 層程度で十分。
それぞれみていきます。
1 については納得感のある主張で、辞書ベースだと辞書外のフレーズに対応できないので、辞書ベースではなく頻出フレーズに注目してキーフレーズ候補を抽出せよというものです。UCPhrase 論文では、ドキュメント中で 2 回以上出現したフレーズを抽出し、キーフレーズ候補としています。教師なしのキーフレーズ抽出手法はこれまでもかなり研究の蓄積があり、頻度のような統計情報の基づいたものも多いのですが、それに比べてもだいぶ雑な感じはします。しかし論文によるとこれでも十分だそうです。


2 はこの論文の一番変わっているところです。論文によると、BERT の出力するベクターは高次元過ぎて過学習(キーフレーズの丸覚え)をするため、Attention Map のみからキーフレーズを抽出をする工夫を行ったとのことです。BERT の各レイヤーの Attention Map を重ね合わせてそれをあたかも画像のように扱い、CNN で特徴抽出をする方法を提案しています。より詳細には、
Step1. BERT の Attention Map を重ね合わせる。
Step2. 注目しているフレーズ領域(下記スライドの矩形領域)に対して CNN により特徴抽出を行う(CNNも数層程度の軽量なもののようです)。
としてフレーズ候補の特徴ベクターを得ています。

この方法は非常に独特で、あえて Attention Map のみをつかって推論する方法ははじめて見ました。BERT を fine tune しなくてもよいとさえ言っているので、構成によっては UCPhrase 専用には CNN 部分しか持たずによく、キーフレーズ抽出専用のモデルは驚異的に小さくできます。これには期待してしまいます。
3 は効率化のための主張です。BERT のフルレイヤーではなく初期数層だけを使うことにすれば、重たい BERT の処理がショートカットできますし、Attention Map の重ね合わせも結果的に薄くなるので実行速度の高速化に繋がり非常に魅力的です。論文の主張によると、3 層程度でも良いとのことでした。

UCPhraseの再現と失敗
半信半疑でしたが論文でなされている主張は非常に魅力的だったので再現実装を行って検証してみました。こちらに著者による実装もありますがベンチマークデータセットに最適化されていたりしていじりにくかったので、独自に実装しました。結果としては、下記の知見を得ましたが、改善の余地ありという感じがしています。
Core Phrase のみでよかった → ある程度はそのとおり!でもノイジーすぎるかも。
Attention Map のみでもキーフレーズ予測できる → できた!
BERT の初期 3 層の Attention Map だけでも十分だった。しかも fine tune いらない → その通り!
UCPhrase は高速だった → BERT 部分は高速化されても、推論時はそれ以外の部分がボトルネックになりあまり速くないっぽい!
1、2、3 について。実装は簡単だったので割とすぐ再現させることができました。とくに BERT 部分は fine tune しなくていいということだったので BERT の出力(Attention Map を重ねたもの)を事前に計算しておき、学習として使う矩形部分を切り取って保存しておけば、よくある Deep Learning のチュートリアルで MNIST の学習をするくらいの気軽さで学習できました。自分の Macbook Pro (非 M1)でも 30 分くらいで学習できて期待に胸が膨らみました。しかもそれなりにうまく学習できていました。

しかし、細かく見ていくと、Core Phrase の抽出法では変なフレーズを抽出することが大量にあるせいか(あるいは実装のせい?)、かなりノイジーな学習データが生成されていたりしました。そのためかわかりませんが、学習されたモデルも変な出力をすることがしばしばありました。 上記のSlackコメントの抽出例でも「い」という謎のフレーズが抽出されています。割合的にはそんなに多くはないですが、目につくくらいにはこのような変な出力が散見され、このモデルの出力をそのまま使うのでは印象はあまり良くなさそうです。
4 についてはもっと深刻でした。BERT のレイヤーを 3 層にすると BERT 部分はたしかに高速化(フルレイヤー 12 層に比べるとだいたい4倍速)されるのですが、予測は全体的には全然速くならないという結果となりました。というのも、UCPhrase の方法だと予測時には、
Step1. すべてのキーワード候補をとってくる(Attention Maps のありえる矩形領域の列挙)
Step2. 1 にたいして CNN でキーフレーズかどうかの予測
という 2 段階で予測を作ることにになるのですが、とくに Step1 における矩形領域を列挙で無数の矩形領域が提案されることが多く、結果的に CNN を適用する矩形数が膨大になり、全体としての実行速度が遅くなることが発覚しました。これはなんとも解決しようがなく、学習は速いが推論は遅いという残念な結果になりました。
また、以前 BERT の出力をそのまま使ってキーフレーズ抽出をしたときはそこそこうまくいっていたのですが、UCPhrase の場合、多言語 BERT モデルを使って日本語で学習した場合、多言語での抽出結果がいまいちなことが多く、多言語での性能に一抹の不安を覚えました(Attention Map しか見ていないのでしょうがないのかもですが)。
UCPhrase の失敗からの再挑戦
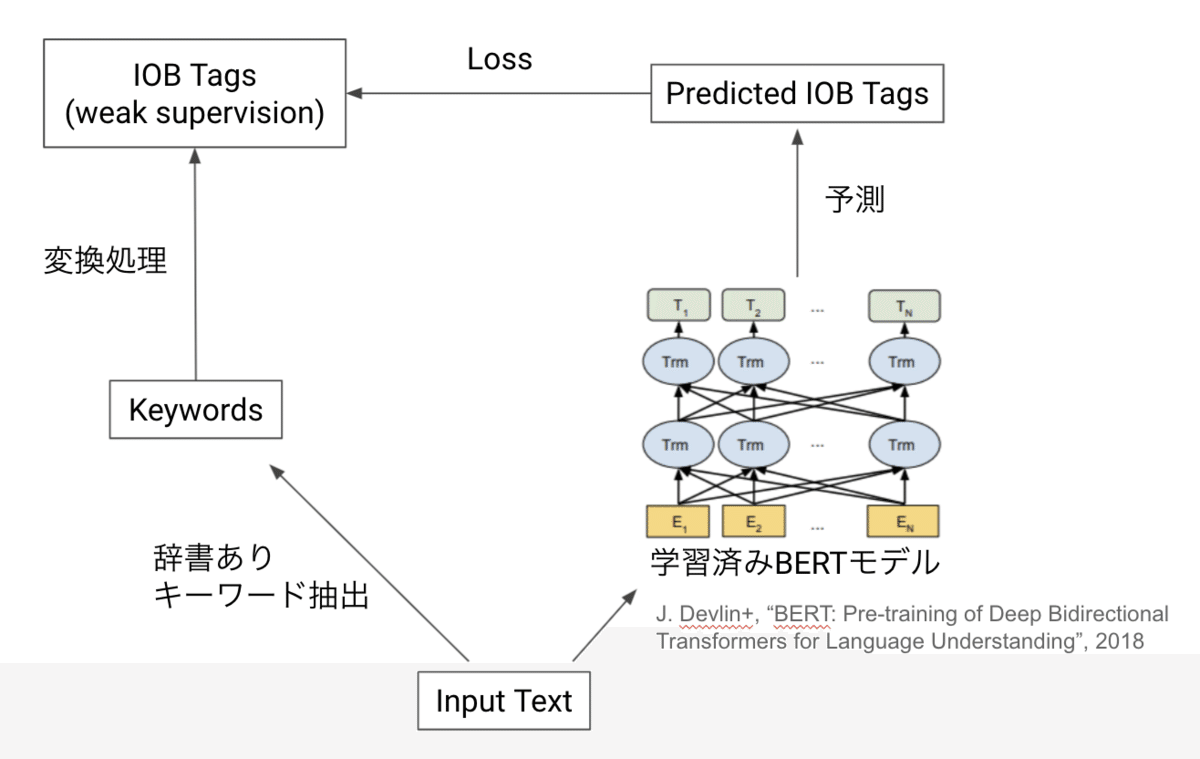
UCPhrase 単体では失敗したものの、BERT の最初の数層の Attention Maps だけでも十分ということで、キーフレーズ抽出自体は実はかなり表面的なタスクなのではないかという思いが高まり、下記の構成で再チャレンジすることにしました。これが現行のモデルです。
特徴抽出は BERT の最初の数層のみにする。BERTは多言語コーパスで学習済みのモデルを使う。
キーフレーズ候補は Core Phrase ではなく辞書ベースで行う
予測は IOB タグで行う
詳しくは下記のようなアーキテクチャになっています。

まずテキストを形態素解析したのち、subwords 分解を行い、BERT の最初の数層へ入力します。以前の検証で DistilBERT を使った場合、量子化をしたときに出力がおかしくなったことがあったので、普通の BERT モデルを使用しています。また、多言語対応を考え、多言語コーパスで学習済みのモデルを使います。BERT の出力は subwords 単位で得られるのですが、もともと同一の word に属していた subwords たちに対して pooling(subwords pooling、現状は単純加算しています)を行うことで words 単位に集約し、さらに最後の Bi-directional LSTM でデコードして予測結果を得ています。
UCPhrase の主張とは反していますが、Core Phrases ではキーフレーズ候補がノイジー過ぎたので辞書ベースに戻しました。また、もともと BERT ベースのモデルでもそれなりの精度が出ていたのと、UCPhrase によると BERT の最初の数層だけでよいということで、BERTの最初の数層の出力(Attention Mapではなく)を使うことにしました。
また、常套手段として subwords 分解はしていますが、後処理で subwords -> words の集約を行おうとすると、words 単位の IOB タグを subwords 単位にどうやって変換するのかという別の非本質的な問題が発生するので、モデルの中で pooling して subwords 単位に出力された BERT の出力を words 単位に集約するようにしています。
最後の Bi-LSTM によるデコードはかなり重要な処理のようで、これを外すと前後の予測を無視したような出力がでやすいです。
特徴抽出器のレイヤー数とデコーダー(Bi-LSTM)の層数や次元数はハイパーパラメータチューニングを行い決定しました。BERT、Bi-LSTM のレイヤー数についてはは 1, 2 層くらいでも良さそうということがわかりました。Beatrust ではさらにモデルの 8 bit 量子化も行い、CPU 環境での高速化を狙っています。結果として、LSTM の手前にうすい Transformer 層と subwords pooling 層を付け加えるという、以前から行われていた LSTM ベースのキーフレーズ抽出に毛の生えたような構成におちつきました。なお、UCPhrase 論文と同様に BERT レイヤーを固定することも検討したのですが、現状は精度を優先させるため、BERT レイヤーも fine tune しています。
実行速度は下記の通りです(モデルの inference 部分のみ)。入力テキストには自分の社員インタビューから抽出した 4000 文字程度のテキストを使っています。BERT のレイヤー数に対しておおむね線形に推論時間が変化していることが確認できます(量子化した BERT が速すぎるのが気になりますが)。レイヤー数を減らしたり量子化をしても精度的にもそこまで目立った劣化はありませんでした。

以前も量子化は行っていたのですが、今回の修正で推論速度は以前までの実装と比べて 3.5 倍速ほどになり、かなり高速化させることができました。メモリ使用量については、実は今使っている BERT モデルだと Embeddings レイヤーのパラメータ数が支配的なので、大幅な改善はありませんが、100〜200MBくらいの削減には成功しています。なお、今使っている PyTorch のバージョンだと Embeddings レイヤーの量子化はサポートされていないのですが、手元で無理やり量子化してみたところ、サイズは大幅に減らせましたが、推論速度がちょびっと落ちるのでプロダクトへ Embeddings の量子化を組み込むかは今後検討していきたいと思います。
最後に念のため、量子化したモデルで学習コーパスにいれていない中国語でのキーフレーズ抽出も試してみました。下記の通り、confidenceはいまいちですが、それっぽいフレーズは抽出できているので、仮に急遽中国語対応が必要になったとしても最低限の機能は提供できるのかなぁと思っています。

さいごに
UCPhrase の再現実装での学びから、BERT のレイヤー数を極端に減らしても大丈夫そうなことがわかり、既存のモデルにたいしてかなりの高速化ができました。自分の手を動かして試して学びを得ることはやはり大事だなと感じました。
キーフレーズ抽出は単にキーフレーズを抽出してくるだけのタスクですが、今後は、抽出されたキーフレーズがその人にどんなふうにどれくらい関連づいているのかの推定(ランキング、関係性推定)やテキスト中に現れないキーフレーズの推薦なども行っていき、Personal Knoledge Base の(半)自動構築などにもチャレンジしていきたいと思います。また、これらも可能な限り、スケーラブルな学習方法を探っていきたいと思います。
最後に、Beatrustではデータ関連職種を募集中です。ご興味ある方はお気軽にお声がけください!