
Massively Multilingual Speech をシュッと?触ってみた

こんにちは最近 Whisper API と戯れることが多い bbz です。
そんな折、 speech-to-text な話題が twitter のタイムラインに
Today we're sharing new progress on our AI speech work. Our Massively Multilingual Speech (MMS) project has now scaled speech-to-text & text-to-speech to support over 1,100 languages — a 10x increase from previous work.
— Meta AI (@MetaAI) May 22, 2023
Details + access to new pretrained models ⬇️
Σ(・□・;)
なんかすげぇのでてきたな。。。
GitHub リポジトリもあるので触ってみるっきゃない
MMS:音声技術を1000以上の言語に拡張する
MMS(Massively Multilingual Speech)プロジェクトは、1,100以上の言語(従来の10倍以上)をサポートする単一の多言語音声認識モデル、4,000以上の言語(従来の40倍)を識別できる言語識別モデル、1,400以上の言語をサポートする事前学習モデル、1,100以上の言語の音声合成モデルの構築によって音声技術を約100言語から1000以上へ拡張する。私たちの目標は、人々が自分の好きな言語で情報にアクセスし、機器を使用することをより簡単にすることです。
詳細は、論文「Scaling Speech Technology to 1000+ languages」やブログ記事でご覧いただけます。
MMSがカバーしている言語の概要は、こちらでご覧いただけます。
ということで例のごとく Google Colab でシュッと触ってみました。
まずは音源を作る
from IPython.display import Javascript
from google.colab import output
from base64 import b64decode
RECORD = """
const sleep = time => new Promise(resolve => setTimeout(resolve, time))
const b2text = blob => new Promise(resolve => {
const reader = new FileReader()
reader.onloadend = e => resolve(e.srcElement.result)
reader.readAsDataURL(blob)
})
var record = time => new Promise(async resolve => {
stream = await navigator.mediaDevices.getUserMedia({ audio: true })
recorder = new MediaRecorder(stream)
chunks = []
recorder.ondataavailable = e => chunks.push(e.data)
recorder.start()
await sleep(time)
recorder.onstop = async ()=>{
blob = new Blob(chunks)
text = await b2text(blob)
resolve(text)
}
recorder.stop()
})
"""
def record(sec=30):
display(Javascript(RECORD))
s = output.eval_js('record(%d)' % (sec*1000))
b = b64decode(s.split(',')[1])
with open('audio.wav','wb') as f:
f.write(b)
return 'audio.wav'
record()このままだと後で読み込めないとなったので修正
import librosa
import soundfile as sf
# Load the audio file with a new sampling rate
audio, sr = librosa.load('audio.wav', sr=16000)
# Save the audio file with the new sampling rate
sf.write('resampled_audio.wav', audio, sr)
いくつかのモデルとできることがあるけど今回は MMS-1B:FL102 モデルで ASR を試してみるよ
というわけで Do It !!
!cd fairseq && python examples/mms/asr/infer/mms_infer.py \
--model "/content/mms1b_fl102.pt" --lang jpn --audio "/content/resampled_audio.wav"結果
>>> preparing tmp manifest dir ...
PYTHONPATH=. PREFIX=INFER HYDRA_FULL_ERROR=1 python examples/speech_recognition/new/infer.py -m --config-dir examples/mms/asr/config/ --config-name infer_common decoding.type=viterbi dataset.max_tokens=4000000 distributed_training.distributed_world_size=1 "common_eval.path='/content/mms1b_fl102.pt'" task.data=/content/tmp dataset.gen_subset="jpn:dev" common_eval.post_process=letter decoding.results_path=/content/tmp
>>> loading model & running inference ...
2023-05-22 22:02:52.055738: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
[2023-05-22 22:02:58,730][HYDRA] Launching 1 jobs locally
[2023-05-22 22:02:58,730][HYDRA] #0 : decoding.type=viterbi dataset.max_tokens=4000000 distributed_training.distributed_world_size=1 common_eval.path='/content/mms1b_fl102.pt' task.data=/content/tmp dataset.gen_subset=jpn:dev common_eval.post_process=letter decoding.results_path=/content/tmp
[2023-05-22 22:02:59,254][__main__][INFO] - /content/mms1b_fl102.pt
Killed
Traceback (most recent call last):
File "/content/fairseq/examples/mms/asr/infer/mms_infer.py", line 54, in <module>
process(args)
File "/content/fairseq/examples/mms/asr/infer/mms_infer.py", line 46, in process
with open(tmpdir/"hypo.word") as fr:
FileNotFoundError: [Errno 2] No such file or directory: '/content/tmp/hypo.word'( ゚д゚)
エラーですな。
/tmp/hypo.wordがないといわれているので tmp フォルダの挙動を確認
tmp の中にいくつかファイルはできるが hypo.word は存在しない。
ふむ。
とりあえず Issue を覗いたらタイムリーに同じエラーが出てる人たちがいた。
が、解決はしておらず。
何故か必要なファイルが作られていないがエラーログからは情報を拾えない。
ふむ。
しょうがないのでコードを覗いていく。
結論。
の
def build_encoder_layer(self, args: Wav2Vec2Config, layer_idx: int):が encoder_layer の数だけループしてメモリが爆死しているのであった。
(デフォルト 48)
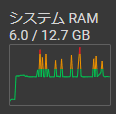
Colab Pro を契約しているがすでにクレジットを使い切っているのでハイメモリが選択できない、、、ぐぬぬ、、、
もうちょい頑張ろうかなと思ったけど
The MMS code and model weights are released under the CC-BY-NC 4.0 license.
ということで商用利用可能なライセンスではなかったので潔くあきらめて撤退するのであった。
とりあえず Issue にはメモリめっちゃ使うから死んでるだけよとだけ記載だけしておいた。。。
今後が楽しみではあるがしばらくは Whisper ちゃんと遊ぶことになりそうなのであった。